







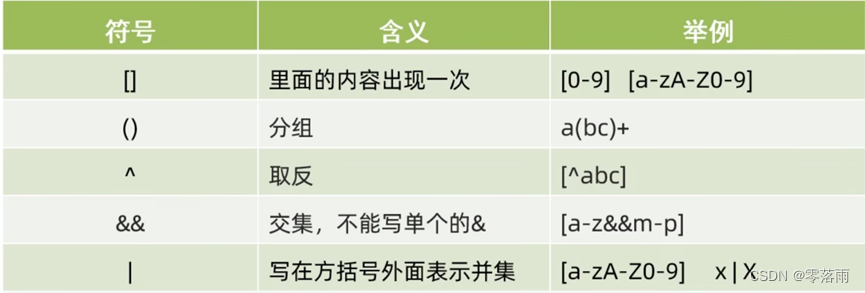
一、正则表达式
1.基础知识
matches("正则表达式") 校验字符串是否满足规则,满足返回true,不满足返回false

正则表达式的表示方法如下:

public class Demo1 {
public static void main(String[] args) {
System.out.println("a".matches("[a-z&&[def]]"));//false
System.out.println("&".matches("[a-z&&[def]]"));//false
System.out.println("a".matches("[a-z&[def]]"));//true
System.out.println("&".matches("[a-z&[def]]"));//true
System.out.println("aa".matches("[a-z&[def]]"));//false
}
}细节:
① &&表示交集,但&并没有任何含义,只是一个特殊符号,表示匹配的字符串是否是该符号
② [ ]只能匹配一个字符,如果字符串内有多个字符,则会返回false
public class Demo2 {
public static void main(String[] args) {
// .表示任意一个字符
System.out.println("你".matches("."));//true
//如果只想表示一个.符号,需要转义
System.out.println(".".matches("\\."));//true
System.out.println("a".matches("\\."));//false
}
}③ . 表示任意一个字符均可,但 \n 回车符号不匹配。如果只想表示一个. 符号,需要使用转义,转义符是 \ ,也就是 \. 。在java中,\\ 表示 \ 。前面一个 \ 表示转义字符,改变了后面 \ 的含义,将其变成一个特殊符号 \ 。所以单独表示一个 . 要用 \\.
public class Demo3 {
public static void main(String[] args) {
// \w表示单词字符,必须是数字,字母,下划线
// {5,}表示至少5位
System.out.println("23_dF".matches("\\w{5,}"));//true
System.out.println("23dF".matches("\\w{5,}"));//false
// \W表示非单词字符
System.out.println("你".matches("\\W"));//true
System.out.println("a".matches("\\W"));//false
//必须是数字和字符,且是4位
// ^ 表示取反
System.out.println("23dF".matches("[\\w&&[^_]]{4}"));//true
System.out.println("23_F".matches("[\\w&&[^_]]{4}"));//false
}
}④ 同理,虽然 \w 表示单词字符,但是 \\ 表示 \ ,所以要用 \\w
public class Demo4 {
public static void main(String[] args) {
//24小时的正则表达式
//时:00-09,10-19,20-23 ([01]\\d|2[0-3])
//:分:00-09,...50-59 (:[0-5]\\d)
//:秒:00-09,...50-59 (:[0-5]\\d)
String regex="([01]\\d|2[0-3])(:[0-5]\\d){2}";
System.out.println("23:11:11".matches(regex));//true
System.out.println("00:00:00".matches(regex));//true
}
}⑤ () 表示分组, 单独的一个 | 符号表示或者,[ ]内表示或者的话不需要加 | 。比如 "(\\d|X|x)" 等价于 "[\\dXx]"
⑥ 出现 | 的话,一定要记得用 () 分组,不然默认和前面所有要求进行或。比如下方 "[1-9]\\d{5}(18|19|20)",如果不加 () ,则是 [1-9]\\d{5}18|19|20,也就是 [1-9]\\d{5}18或者19或者20
public class Demo5 {
public static void main(String[] args) {
//身份证号的正则表达式
//前面6位:省份,市区,派出所等信息,第一位不能是0,后五位任意 [1-9]\\d{5}
//年:18xx,19xx,20xx (18|19|20)\\d{2}
//月:01-09,10,11,12 (0[1-9]|1[0-2])
//日:01-09,10-19,20-29,30,31 (0[1-9]|[12]\\d|30|31)
//后四位:前三位任意,后一位可以是数字,可以是X,也可以是x (\\d{3}[\\dXx])
String regex="[1-9]\\d{5}(18|19|20)\\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\\d|30|31)(\\d{3}[\\dXx])";
System.out.println("13013319720403902X".matches(regex));//true
}
}
public class Demo6 {
public static void main(String[] args) {
//在匹配的时候忽略abc的大小写
System.out.println("abc".matches("(?i)abc"));//true
System.out.println("ABC".matches("(?i)abc"));//true
System.out.println("aBc".matches("(?i)abc"));//true
//在匹配的时候忽略bc的大小写
System.out.println("abc".matches("a(?i)bc"));//true
System.out.println("ABC".matches("a(?i)bc"));//false
System.out.println("aBC".matches("a(?i)bc"));//true
//在匹配的时候忽略b的大小写
System.out.println("abc".matches("a((?i)b)c"));//true
System.out.println("ABC".matches("a((?i)b)c"));//false
System.out.println("aBC".matches("a((?i)b)c"));//false
}
}
⑦ (?i)表示忽略后面字符的大小写,如果只想忽略一部分,需要使用 () 进行分组,比如 "a((?i)b)c" 表示只忽略b的大小写
2.爬虫
(1)文本爬取
爬取文本中所有的以Java开头的字符串
public class Demo7 {
public static void main(String[] args) {
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +
"因为这两个是长期支持的版本,下一个长期支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//获取文本匹配器的对象m --> m按照p的规则去读取字符串str,从头开始读取,去大串中找符合规则的子串
Matcher m = p.matcher(str);
//m调用find方法进行读取,没有返回false,有返回true,并在底层记录起始索引和结束索引+1,然后停止读取
while (m.find()) {
//m调用group方法会根据find方法记录的索引进行字符串截取
//subString(起始索引,结束索引) --> 包头不包尾
String s = m.group();
System.out.println(s);
}
}
}注: find方法底层虽然记录的是结束索引+1,但字符串在截取的时候,是包头不包尾的。比如:subString(0,4),截取的是索引为0到3的字符串,所以+1和不包尾正好抵消了。
运行结果:

(2)网页爬取
获取该网站的所有身份证号
public class Demo8 {
public static void main(String[] args) throws IOException {
//创建一个URL网址的对象
URL url = new URL("https://www.pv138.com/idCard/list/");
//连接上这个网址
URLConnection conn = url.openConnection();
//创建一个对象去读取网络中的数据
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
//获取正则表达式的对象
String regex = "[1-9]\\d{17}";
Pattern pattern = Pattern.compile(regex);
//在读取的时候吗,每次读一整行
while ((line = br.readLine()) != null) {
// System.out.println(line);
Matcher matcher = pattern.matcher(line);
while (matcher.find()) {
System.out.println(matcher.group());
}
}
br.close();
}
}
二、待条件爬取和贪婪爬取
1.带条件爬取
(1)?=
需求1:爬取版本号为8,11,17的Java文本,但是只要Java,不显示版本号。
注:?=在获取索引的时候,只获取前半部分Java
public class Demo9 {
public static void main(String[] args) {
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +
"因为这两个是长期支持的版本,下一个长期支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
// ?表示前面的字符串Java
// =表示Java后面跟随的字符串
// ?=在获取索引的时候,只获取前半部分Java
Pattern p = Pattern.compile("Java(?=7|8|11)");
Matcher m = p.matcher(str);
while (m.find()) {
String s = m.group();
System.out.println(s);
}
}
}运行结果:

(2)?:
需求2:爬取版本号为8,11,17的Java文本。正确爬取结果为:Java8 java11 Java17
注:?:在获取索引的时候,获取整体所有部分
public class Demo9 {
public static void main(String[] args) {
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +
"因为这两个是长期支持的版本,下一个长期支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
// ?:在获取索引的时候,获取整体所有部分
Pattern p = Pattern.compile("Java(?:8|11|17)");
Matcher m = p.matcher(str);
while (m.find()) {
String s = m.group();
System.out.println(s);
}
}
}运行结果:

(3)?!
需求3:爬取除了版本号为8,11的Java文本
注:! 表示Java后面跟随的字符串不能为8或11,?! 在获取索引的时候,依然只获取前半部分Java
public class Demo9 {
public static void main(String[] args) {
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +
"因为这两个是长期支持的版本,下一个长期支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
// !表示Java后面跟随的字符串不能为8或11
// ?!在获取索引的时候,依然只获取前半部分Java
Pattern p = Pattern.compile("Java(?!8|11)");
Matcher m = p.matcher(str);
while (m.find()) {
String s = m.group();
System.out.println(s);
}
}
}
运行结果:

2.贪婪爬取和非贪婪爬取
(1)贪婪爬取(默认):+
需求1:按照ab+的方式爬取ab,b尽可能多获取
public class Demo10 {
public static void main(String[] args) {
String str = "abbbbbbbbbbbbaaaaaaaaaaaaaaaaaa";
//贪婪爬取:尽可能多的获取数据
String regex = "ab+";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(str);
while (m.find()){
System.out.println(m.group());//abbbbbbbbbbbb
}
}
}(2)非贪婪爬取:+?
需求2:按照ab+的方式爬取ab,b尽可能少获取
public class Demo10 {
public static void main(String[] args) {
String str = "abbbbbbbbbbbbaaaaaaaaaaaaaaaaaa";
//非贪婪爬取:尽可能少的获取数据
String regex = "ab+?";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(str);
while (m.find()){
System.out.println(m.group());//ab
}
}
}3.正则表达式在字符串方法中的使用

(1)replaceAll方法
要求1:把字符串中三个姓名之间的字母替换为vs
public class Demo11 {
public static void main(String[] args) {
String s = "小诗诗qwasdasdaskj465465a小丹丹askjdbnaksjbdaskj654小灰灰";
//第一个参数表示满足的正则表达式,第二个参数表示要替换的字符串
String result = s.replaceAll("[\\w&&[^_]]+", "vs");
System.out.println(result);
}
}细节:方法在底层跟之前一样,也会创建文本匹配器的对象m,之后也会通过循环一直find,只要有满足的,就用第二个参数进行替换。
运行结果:

(2)split方法
要求2:把字符串中的三个姓名切割出来
public class Demo11 {
public static void main(String[] args) {
String s = "小诗诗qwasdasdaskj465465a小丹丹askjdbnaksjbdaskj654小灰灰";
//split 按照正则表达式中的规则切割字符串
String[] arr = s.split("[\\w&&[^_]]+");
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}细节:split 方法返回的是一个切割后的字符串数组,遍历即可
运行结果:

三、捕获分组和非捕获分组
1.捕获分组
前面说过,() 表示分组,每组也是有组号的,也就是序号。

注:只看左括号,从左往右数
捕获分组就是把这一组的数据捕获出来,再用一次
(1)正则表达式内部捕获
在正则表达式内部,通过 \\组号 的方式,就可以把第x组的内容拿出来继续使用。
① 捕获一个字符的分组
需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符
举例:a123a b456b 17891 &abc& a123b(false)
public class Demo11 {
public static void main(String[] args) {
// (.) :将第一个字符作为第一组
// \\组号:表示把第x组的内容拿出来用一次
String regex = "(.).+\\1";
System.out.println("a123a".matches(regex));//true
System.out.println("b456b".matches(regex));//true
System.out.println("17891".matches(regex));//true
System.out.println("&abc&".matches(regex));//true
System.out.println("a123b".matches(regex));//false
}
}② 捕获多个字符的分组
需求2:判断一个字符串的开始部分和结束部分是否一致?可以有多个字符
举例:abc123abc b456b 123789123 &!@abc&!@ abc123abd(false)
public class Demo12 {
public static void main(String[] args) {
// (.+) :表示把开始部分的前n个字符作为一组(第一组,n>=1)
// \\组号:表示把第x组的内容拿出来用一次
String regex = "(.+).+\\1";
System.out.println("abc123abc".matches(regex));//true
System.out.println("b456b".matches(regex));//true
System.out.println("123789123".matches(regex));//true
System.out.println("&!@abc&!@".matches(regex));//true
System.out.println("abc123abd".matches(regex));//true
}
}③ 捕获分组内的分组
需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也需要一样
举例:aaa123aaa bbb456bbb 111789111 &&abc&& aaa123aab
public class Demo13 {
public static void main(String[] args) {
// (.):把首字母看做一组(第2组)
// \\2:把首字母拿出来再次使用
// * :作用于\\2,表示后面重复的第二组的内容出现0次或多次
String regex = "((.)\\2*).+\\1";
System.out.println("aaa123aaa".matches(regex));//true
System.out.println("bbb456bbb".matches(regex));//true
System.out.println("111789111".matches(regex));//true
System.out.println("&&abc&&".matches(regex));//true
System.out.println("aaa123aab".matches(regex));//false
}
}注:
分组的序号是只看左括号的,从左到右数,所以第一个字符 (.) 是第二组。
由于开始部分内部每个字符也需要一样,就是让第一个字符后面再接0个或多个相同字符,也就是 \\2*
这时的第一组和需求2一样,表示整个开始部分(含1个或多个相同字符)
(2)正则表达式外部捕获
在正则表达式外部,通过 $组号 的方式,就可以把第x组的内容拿出来继续使用。
需求:将字符串 "我要学学编编编编编编编编编编程程程程程程程程程程程程程程"
替换为 "我要学编程"
public class Demo14 {
public static void main(String[] args) {
String str = "我要学学编编编编编编编编编编程程程程程程程程程程程程程程";
// (.) :表示把重复内容的第1个字符看做一组
// \\1+:表示第1组再次出现至少一次
// $1 :表示把正则表达式中第一组的内容,再拿出来用
String s = str.replaceAll("(.)\\1+", "$1");
System.out.println(s);
}
}
细节:
replaceAll方法会将所有满足正则表达式的字符串替换为对应字符,这里想替换的字符应该就是出现的第一个字符,也就是第一组的内容。
由于在正则表达式外部使用,所以要用$1
2.非捕获分组
在java的正则表达式中,使用 () 分组,默认是捕获分组
非捕获分组表示,分组之后不再使用本组数据,仅仅是把数据括起来,而不占用组号

以上三种带条件爬取,都是非捕获分组 。
但更多的是使用第一个 ?: ,因为 ?: 代表在获取索引的时候,获取整个部分。

能够很明显的看到,虽然使用了 () 进行分组,但是由于 是 (?:正则) ,属于非捕获分组,不占用组号,所以 \\1 直接报错。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









