







Redis基本特点
- 非关系型的键值对数据库,可以根据键以O(1) 的时间复杂度取出或插入关联值
- Redis 的数据是存在内存中的
- 键值对中键的类型可以是字符串,整型,浮点型等,且键是唯一的
- 键值对中的值类型可以是string,hash,list,set,sorted set 等
- Redis 内置了复制,磁盘持久化,LUA脚本,事务,SSL, ACLs,客户端缓存,客户端代理等功能
- 通过Redis哨兵和Redis Cluster 模式提供高可用性
应用场景
计数器:redis可以通过incr或decr等操作数值得方法对key的值进行加减,而且由于redis是基于内存的操作,性能非常的高。
分布式ID:生成利用自增特性,一次请求一个大范围的ID,如 incr 2000 ,缓存在本地使用,用完再请求。
海量数据统计: 存储是否参过某次活动,是否已读谋篇文章,用户是否为会员, 日活统计。
会话缓存:可以使用 Redis 来统一存储多台应用服务器的会话信息。当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。
分布式队列/阻塞队列:List 是一个双向链表,可以通过 lpush/rpush 和 rpop/lpop 写入和读取消息;通过使用brpop/blpop 来实现阻塞队列。
分布式锁:在分布式场景下,JVM层面的锁无法保证集群环境下数据的并发安全,此时可以使用 Redis 自带的SETNX 命令实现分布式锁。
热点数据存储:最新评论,最新文章列表,使用list 存储,ltrim取出热点数据,删除老数据。
社交类需求:Set 可以实现交集,从而实现共同好友等功能,Set通过求差集,可以进行好友推荐,文章推荐。
排行榜:sorted_set可以实现有序性操作,从而实现排行榜等功能。
延迟队列:使用sorted_set,使用 【当前时间戳 + 需要延迟的时长】做score, 消息内容作为元素,调用zadd来生产消息,消费者使用zrangbyscore获取当前时间之前的数据做轮询处理。消费完再删除任务 rem key member
Key的数据类型
Redis是一个存储键值对类似数据的非关系型数据库,其key的值都会被Redis服务器处理为String类型,而Value可以是String,Hash,List,Set,SortSet等各种类型。
K-V
map-> dict
key: String
value: String,Hash,List,Set,SortSet
数据库要有一个海量数据存储的功能,就需要依赖直接在内存中使用的数据结构
数组 O(1)
链表 O(n)redis中数组创建过程
- 通过hash计算得到一个超大的自然数,也称为hash值
- 根据数组长度进行取模得到对应[0,数组长度-1]的下标
key计算的特点是
- 相同值得key的输入,得到的下标的值一定相同
- 但不同值的key的输入,得到的下标的值也可能相同
但会产生hash碰撞的问题,也称为hash碰撞,当中这种情况下,同一个下标上有多个元素,需要使用链表来存储;有些类似于java中的hashMap
Key数据结构
Key数据结构
C语言中
--字符串类型是char类型的数组,且每一个值以\0结尾 char data[] = "aaa\0"
因为客户端传到服务端的key可能存在“\0”的字符,若使用C语言的String结构类型,key值会被截断;因此Redis自己定义了一种String的数据类型:SDS(simple dynamic string)
sds:
free:buf中剩余的数组长度
len:字节长度
char buf[] = "aaaa"
其数组大小在不足以存放key时会进行扩容,扩容机制为
新数组的长度 = (sds原本的len + 新的key大于len的长度)*2
等同于新key长度*2
其优点在于可以有空闲的内存空间,在key发生变化,且长度未超过原长度2倍时直接使用;注意,当数组的大小达到1M时,就不会成倍的扩容,而是每次增加1M
其数据结构的特点:
- 是一个安全的二进制数据结构
- 提高内存预分配机制,皮面了频繁的内存分配
- 兼容了C语言的函数库,其尾部会自动加"\0"
key详细信息
数据结构
redis 3.2 以前
struct sdshdr {
int len;长度 = 2^(4*8)-1
int free;
char buf[];//初始化数组的长度过大,分配的空间几乎不能使用完
};
redis 3.2 后根据使用情况创建了不同大小的数组
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
redisDb整体数据结构
redisDb
typedef struct redisDb {
dict *dict;
dict *expires;
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
int id;
long long avg_ttl;
unsigned long expires_cursor;
list *defrag_later;
} dict
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
unsigned long iterators;
}dictht
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}dictEntry
头插法将数据存入链表
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
}redisObject
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
}
bitMap
bitmap是通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态。一个bit的值,或者是0,或者是1;也就是说一个bit能存储的最多信息是2。
优点
1.基于最小的单位bit进行存储,所以非常省空间。
2.设置时候时间复杂度O(1)、读取时候时间复杂度O(n),操作是非常快的。
3.二进制数据的存储,进行相关计算的时候非常快。
4.方便扩容
缺点
redis中bit映射被限制在512MB之内,所以最大是2^32位。建议每个key的位数都控制下,因为读取时候时间复杂度O(n),越大的串读的时间花销越多。
List数据结构
帮助命令
help @list
数据实现
链表
pre //头节点指针8byte
next //尾节点指针8byte缺点
- 数据多的时候,指针占用大量内存
- 占用的是不连续的内存空间,会产生内存碎片
List是一个有序(按set的时序排序)的数据结构,Redis采用quicklist(双端链表) 和ziplist(还是一个连续的内存空间结构) 作为List的底层实现。可以通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率。
zplist数据结构底层编码
zlbytes:标识当前list存放的数据量(字节总数)
zltail:尾结点索引位置,通过尾结点遍历()
zllen:list有多少个entry元素
entry:存放数据的数据项
zlend:标识数据结尾,固定位255
prerawlen:上一个entry元素的信息,根据数据项是否小于254来决定其数据占有的位数,若小于,占1byte,否则占5byte,其中1byte用来标记254,其他4byte用来存放数据。
len:当前entry数据的长度
data:实际存放的数据
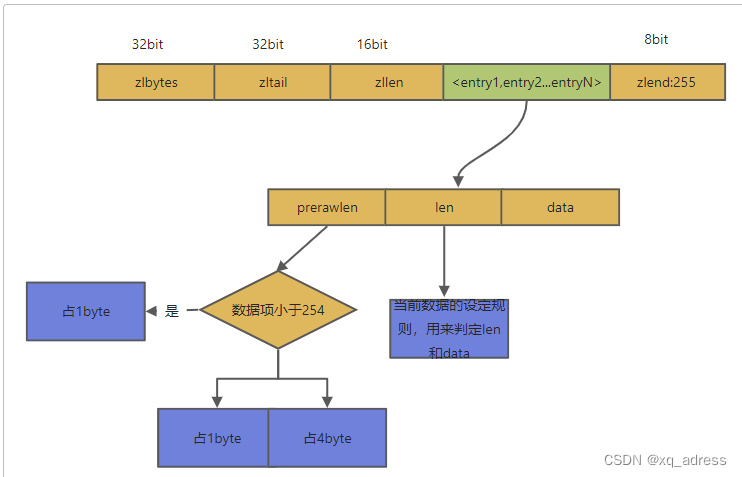
entry中如果存放全部的数据,那么当对这个list进行数据的增加或删除的时候,都需要先释放,然后重新分配内存,因此使用了双端链表来存储。其实现方式为将大量的数据拆分为多个list,然后使用链表来进行关联。
quicklist
底层源码
robj *createQuicklistObject(void) {
quicklist *l = quicklistCreate();
robj *o = createObject(OBJ_LIST,l);
o->encoding = OBJ_ENCODING_QUICKLIST;
return o;
}
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
quicklist->bookmark_count = 0;
return quicklist;
}
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count;
unsigned long len;
int fill : QL_FILL_BITS;
unsigned int compress : QL_COMP_BITS;
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz;
unsigned int count : 16;
unsigned int encoding : 2;
unsigned int container : 2;
unsigned int recompress : 1;
unsigned int attempted_compress : 1;
unsigned int extra : 10;
} quicklistNode;
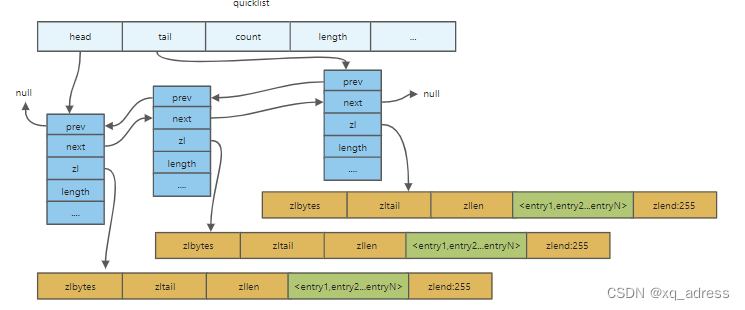
- head:头结点
- tail:尾结点
- count:元素个数
- length:链表长度
可以通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率
list-max-ziplist-size -2 // 单个ziplist节点最大能存储 8kb ,超过则进行分裂,将数据存储在新的ziplist节点中
list-compress-depth 1 // 0 代表所有节点,都不进行压缩,1, 代表从头节点往后走一个,尾节点往前走一个不用压缩,其他的全部压缩,2,3,4 ... 以此类推
Hash数据结构
Hash 数据结构底层实现为一个字典( dict ),也是RedisBb用来存储K-V的数据结构,当数据量比较小,或者单个元素比较小时,底层用ziplist存储,数据大小和元素数量阈值可以通过如下参数设置。
hset a-hash name xinqi age 25 f1 v1 f2 v2 f3 v3
Set数据结构
Set 为无序的,自动去重的集合数据类型,Set 数据结构底层实现为一个value 为 null 的 字典( dict ),当数据可以用整形表示时,Set集合将被编码为intset数据结构。
两个条件任意满足时Set将用hashtable存储数据
- 元素个数大于 set-max-intset-entries
- 元素无法用整形表示
inset数据结构
typedef struct intset {
uint32_t encoding;//编码类型
uint32_t length;//元素个数
int8_t contents[];//元素存放
} intset;
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))整数集合是一个有序的,存储整型数据的结构。整型集合在Redis中可以保存int16_t,int32_t,int64_t类型的整型数据,并且可以保证集合中不会出现重复数据。
Zset数据结构
ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为 字典(dict) + 跳表(skiplist) ,当数据比较少时,用ziplist编码结构存储。
// 创建zset 数据结构: 字典 + 跳表
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
// dict用来查询数据到分数的对应关系, 如 zscore 就可以直接根据 元素拿到分值
zs->dict = dictCreate(&zsetDictType,NULL);
// skiplist用来根据分数查询数据(可能是范围查找)
zs->zsl = zslCreate();
// 设置对象类型
o = createObject(OBJ_ZSET,zs);
// 设置编码类型
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
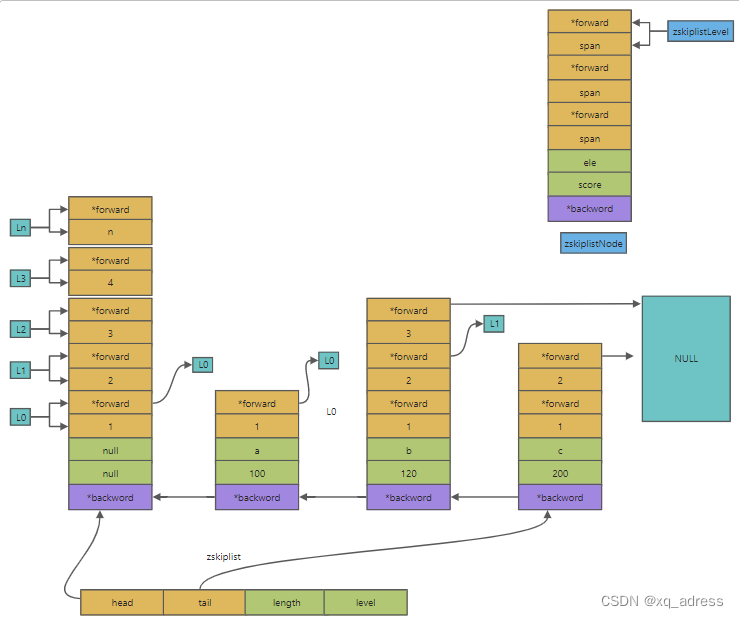
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
zset-max-ziplist-entries 128 // 元素个数超过128 ,将用skiplist编码
zset-max-ziplist-value 64 // 单个元素大小超过 64 byte, 将用 skiplist编码
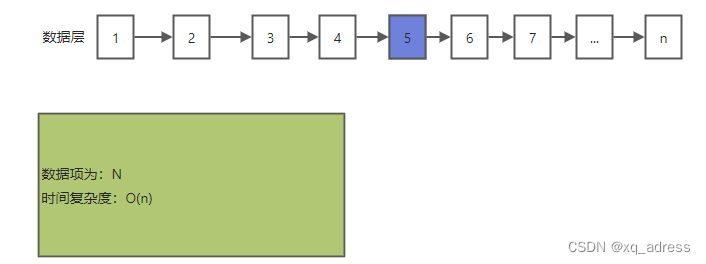
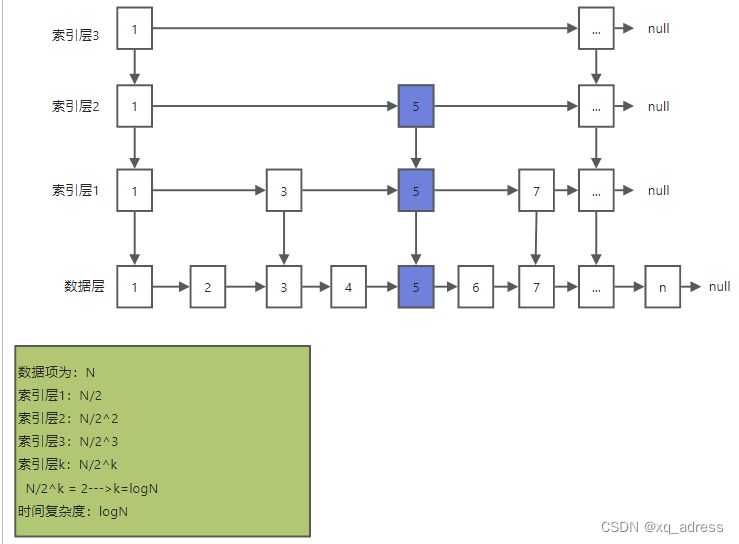
跳表(skiplist)原理
优点类似B+树的做法,数据放在最底层,通过索引来进行二分查找,以建立不同高度的索引层来进行遍历查询,加快查询的速度,将原本时间复杂度为O(n)的链表遍历,变为时间复杂度为
链表遍历
跳表遍历
zskiplist
// 创建zset 数据结构: 字典 + 跳表
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
// dict用来查询数据到分数的对应关系, 如 zscore 就可以直接根据 元素拿到分值
zs->dict = dictCreate(&zsetDictType,NULL);
// skiplist用来根据分数查询数据(可能是范围查找)
zs->zsl = zslCreate();
// 设置对象类型
o = createObject(OBJ_ZSET,zs);
// 设置编码类型
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
- level:整个跳表最高的索引的层数
- head:头结点
- tail:尾节点
- length:元素个数















 1406
1406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









