







一.HTTP协议
在互联网世界中,HTTP(HyperText Transfer Protocol,超文本传输协议)是一个至关重要的协议。它定义了客户端(如浏览器)与服务器之间如何进行通信,以交换或传输超文本。
1.URL
我们使用浏览器访问网站的时候,上方会出现该网站的网址,如https://www.bilibili.com。这其实就是URL。
![]()
而URL每一部分都表示着不同的含义:
0x1.https
指定用于访问资源的网络协议,如HTTP(超文本传输协议)、HTTPS(安全超文本传输协议)、FTP(文件传输协议)等。
0x2.www.bilibili.com
域名,其实就是ip地址。我们访问目标服务器,都要知道对方的ip地址和端口号,才能与之进行连接。而域名的出现主要是为了方便记忆。当我们通过域名访问网站时,会先将该请求发送到DNS服务器,DNS服务器内部保存了ip地址和域名之间的映射关系,DNS找到之后会将该请求转发到对应ip地址的服务器上。
通常,当我们点入网站的某部分,URL就会发生变化。当我们点进腾讯新闻的一个新闻详情之后,它的URL就会发生如下变化:

0x3./rain/a/20250515A8HE200
这一部分表示的是访问资源的路径。那么资源是什么呢?网页、图片、音频、视频、文字等等。而最前面的“/”并不是Linux的根目录,而是web根目录。其实是当前工作目录下一个指定的文件夹。所有的资源都存放在该文件夹下。
但是就怪了,访问目标服务器,不是得借助ip+port么?域名就是ip,那么端口号在哪呢?其实对于成熟的协议来说,它们的端口号都是确定的:http:80, https:443。也就是说,当我们指定了协议之后,其实也就相当于知道了端口号了。
2.urlencode 和 urldecode
在URL中,像#、%、/、?、&等符号都已经有了特殊含义,因此这些字符不能随意出现。当这些字符以参数等形式出现在URL中,客户端(一般是浏览器),会对这些字符进行编码encode,防止直接请求,导致服务端解析失败。
对于encode的url,服务端会自动进行decode。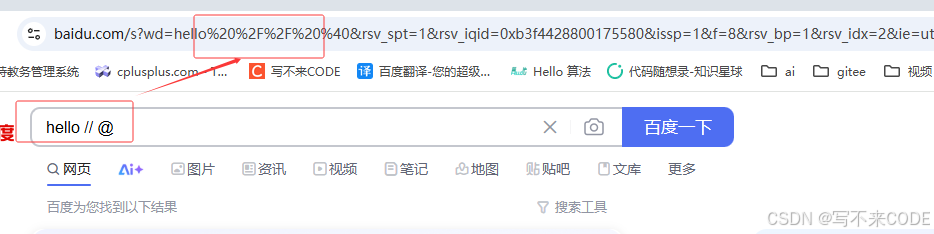
转换规则:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY的格式。
我们可以使用下面这个工具来实现urlencode和urldecodeUrlEncode编码/UrlDecode解码 - 站长工具
二.http 请求
如下就是一个http请求:
http协议作为一个成熟的协议,它本质上也就是个结构化的数据。但其实服务器收到的就是上图的一个大字符串,只不过通过换行符和空行分割起来了而已。
1.http 请求的具体格式 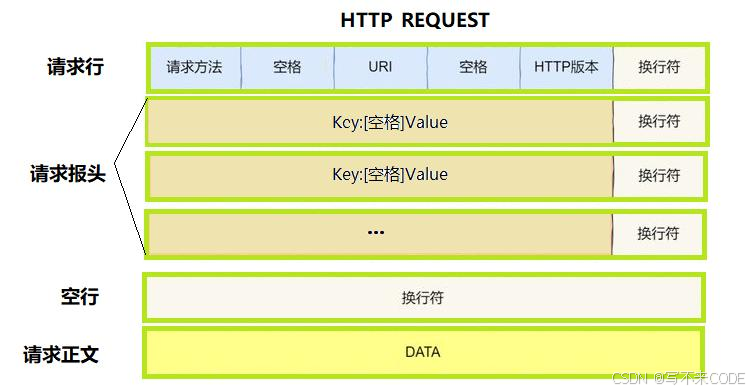
宏观结构:整个http请求由空行分割,空行上方是请求行和请求报头,空行下方则是请求正文。
请求行:请求方法 + URI +HTTP版本号构成,中间由空格分开,结尾有换行符。
请求报头:有多行,均是key value结构,中间由冒号和空格分割,表示的是请求时的一些属性。
请求正文:请求正文可以为空,如果不为空,则在请求报头中应该包含一个Content-Length属性,用来表明正文的长度。
所以,作为一个http请求,它的结构化数据就应该包含上述的几个部分:
class HttpRequest
{
private:
std::string _req_method;
std::string _rui;
std::string _version;
std::unordered_map<std::string, std::string> _headers;
std::string _blankRow;
std::string _text;
};客户端发送请求的过程,其实就是填写该结构化数据的过程。
有了http请求的结构化数据,那么http请求是如何做到报头和有效载荷的分离呢?
借助空行,就可以读到完整的请求行和请求报头,然后再通过请求报头中的Content-Length属性来获取正文长度,最后就能将正文从一个请求中截取出来。
http协议是如何进行序列化和反序列化的呢?
http协议的序列化过程其实是借助特殊字符进行字符串拼接,且不依赖任何第三方库。
2.uri
uri,统一资源标识符。用来表示该请求用来访问什么资源。该资源必须是在服务器特定路径下的文件中。
当我们访问一个url时,并为指定访问该网站的那个资源时,默认访问的就是该网站的首页,此时的uri就是/,它表示的是访问默认首页,服务器会自动给后面拼上index.html/index.htm.![]()
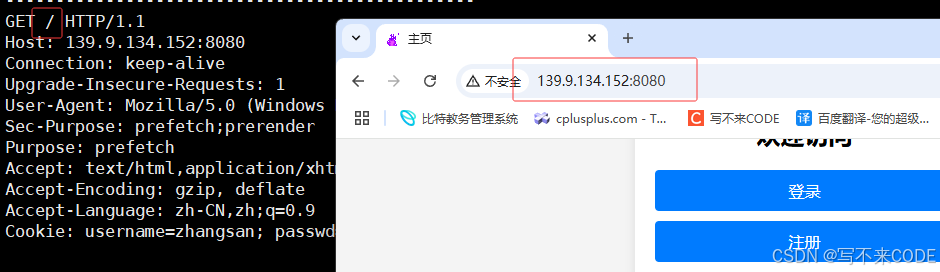
比如说,我们要访问服务器特定目录下的网页,/a/b/c.html.此时,这就是这次请求的uri。服务器在收到请求后,会将保存网页资源的web根目录拼接到该uri的前面,这样就形成了一个绝对路径。服务器就可以根据该绝对路径,来判断你要访问的资源是否存在。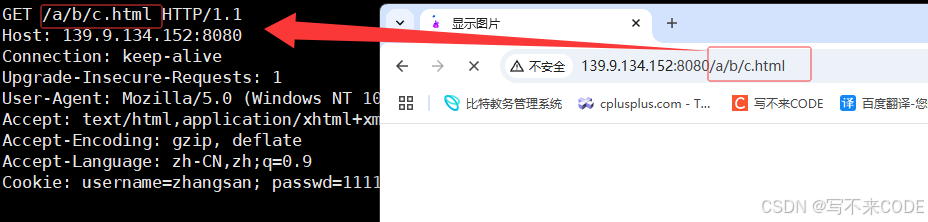
综上,http请求的本质,其实就是请求我们代码中web根目录下的特定路径下的资源。而uri中的路径,就是我们要拼接在web根目录下的。
三.http 响应
如下,就是一个服务器给客户端返回的http 响应: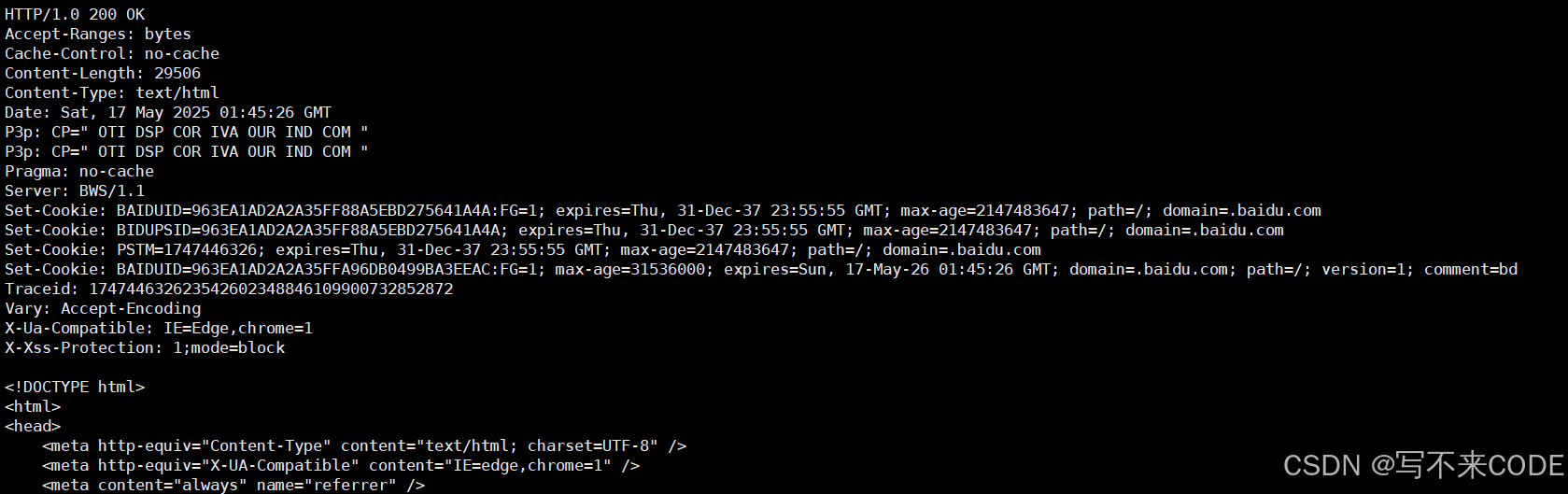
我们可以看到它的整体结构和http请求是非常相似的。
1.http 响应的具体格式

我们可以看到,http response 和http request的结构是非常类似的。同时通过空行将正文与报文分割。
状态行:HTTP版本 + 状态码 + 状态码描述,状态行通常用来表示客户端的请求是否成功。
响应报头:与请求报头类似,都是key:value的结构,用冒号和空格分开,表示这次响应的属性。
正文部分:即请求所请求的网页信息等资源的具体内容。
2.状态码
状态码使用来表示请求是否成功的标志。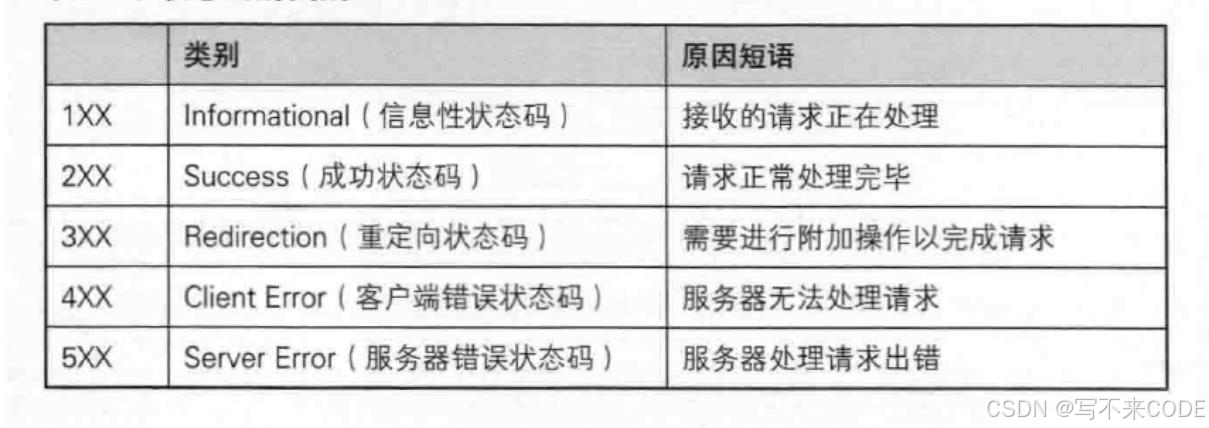
常见的状态码有:
- 200---OK,访问成功;
- 404---Not Found,访问资源不存在;
- 301---Moved Permanently ,永久重定向;
- 302---See Other,临时重定向
这里值得说的就是重定向状态码。重定向说的就是当我们访问一个网页资源时,会跳转到另一个网站的过程,就是重定向。
临时重定向: 原URL仍有效,会跳转到另一个url,但下次访问时还是会先访问原url。常见的就是在视频网站,要求我们登录的场景,登录之后,此时就会重定向到首页。临时重定向并不会修改原来的请求方法。
永久重定向:原URL已经失效,原url对应的资源已经迁移至新的url,客户端和搜索引擎应永久使用新 URL,后续请求直接访问新地址,原 URL 可废弃。常见的就是更换域名。永久重定向有可能会修改请求方法。
那么重定向操作是如何让客户端访问到另一个页面呢?
通过报头属性Location。
当我们访问的资源被迁移后,我们访问该资源,服务器给我们发送的响应中就会包含Location属性,对应的value就是重定向的url,客户端收到之后,就会自动向Location的url重新发送请求。此时响应的状态码为301/302。
四.报头属性
1.常见的报头属性
0x1.Content-Length
表明正文长度
0x2.Content-Type
数据类型,http作为超文本传输协议,我们不仅仅用其传输文本,还可以用来传输图片,音频,视频等等资源。所以,我们在传输资源的时候,根据传输的资源,需要填写Content-Type来表明你要访问资源的类型,以提前让客户端知道该怎么处理资源。
常见的资源与其对应的类型:
- text/html : HTML格式
- text/plain :纯文本格式
- text/xml : XML格式
- image/gif :gif图片格式
- image/jpeg :jpg图片格式
- image/png:png图片格式
需要注意的是:我们访问的网页可能里面还包含了处文字外的各种图片、视频等等。所以当我们发出请求访问该网页时,其实会发出多次请求,第一次用来请求网页本身,然后再依次请求网页中的图片资源。这几次访问使的content-type是不一致的。
0x3.Host
客户端告知服务器,所请求的资源是在那个主机的那个端口上
0x4.User-Agent
声明用户的操作系统,以及浏览器版本信息
0x5.refer
当前页面是从那个页面跳转过来的
0x5.Location
搭配3开头状态码,实现重定向的效果,告诉客户端接下来要去访问那里
0x6.Cookie
用来存储用户信息,通常用于使用会话(session)功能
2.connection
connection用来表明该客户端或者服务器是否支持长连接。如果支持长连接则为keep-alive,如果不支持长连接则为close。
在http刚刚出现的时候,都是短连接,即发一次request,收一次response服务端就会将连接断开。如果想要继续访问,此时就得重新进行连接。而http是基于tcp的,所以连接的时候需要经历三次握手。而一张网页动不动就包含十几二十张图片,每次都需要断开连接,重新连接后再访问。此时服务器就得受理多次。
而当HTTP/1.1出现后,有了长连接方案。在一次连接中,可以一次发送多条request,也可以收多条response。这样就解决了需要多次连接的问题。
当客户端和服务端都支持长连接,此时就会默认使用长连接,如果一方不支持,就采取短连接的方式。
3.cookie
在一些视频网站,经常需要登录之后,才能进行观看,或者只有vip用户才能观看。当我们登录之后,服务器会对账号和密码进行认证,认证成功之后就可以观看了。
但http是一个无状态的协议,即每次请求都需要建立新的连接,且服务器不会保存客户端的状态信息。这也就意味着,我们登录之后,如果向看具体的一个电影,此时它因为无状态,又需要我们进行登录,认证,认证通过后才能观看。
所以,为了解决这个问题,就有了cookie属性。当我们第一次认证将我们的信息给服务器后,服务器进行认证,认证成功后,会将账号和密码通过set-cookie响应写给客户端。客户端拿着cookie会将其进行保存,有可能是文件,也有可能是内存级保存。
有了cookie之后,下一次客户端访问的时候,就会自动在请求中带入cookie属性。服务器收到之后,就会自动进行认证了。这就不需要我们重复登陆了。
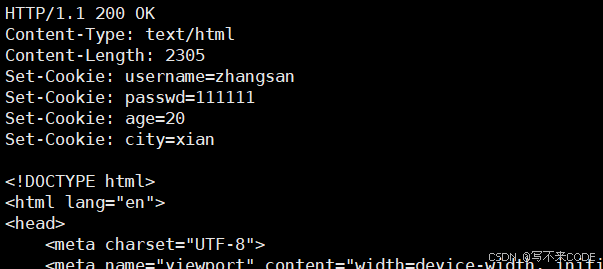
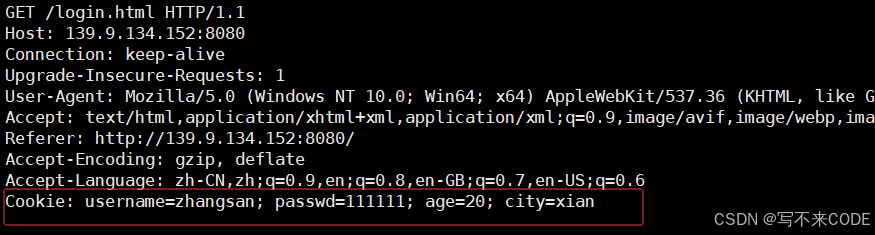
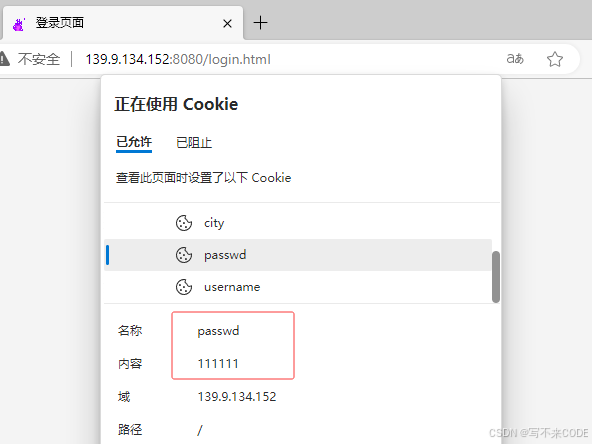
但是这种方案已经被淘汰了。因为使用cookie会导致两个问题:
1.你本地浏览器上的cookie文件可能会被盗用,这样其他人就可以拿着你的cookie,以你的身份访问服务端
2.cookie文件对内容做了编码,但依旧是可见的,所以,你的隐私会泄露
所以,我们通常采取cookie和session同时使用的方法,来解决一部分问题:
当我们登录的时候,服务端那我们的登录信息,会在服务器内部创建一个临时文件session,该文件有一个session_id,是唯一的。
服务端会将该session_id通过Set-Cookie写回客户端。自此,客户端再访问的时候,就会借助session_id来进行访问服务端再拿到session_id之后,在其内部判断该session_id是否存在,如果存在登录成功,失败,则重新进行登录.
当然,借助session只能解决你的隐私信息不被泄露seesion_id依旧有可能被他人获取,进行访问。所以我们通常会又一些辅助方案来解决session_id被他人使用的方案。比如ip溯源、异常账号检测等等。
这种方案,称为会话管理和会话保持。
五.请求方法
我们上网的行为无非两种:从服务端获取资源到本地,将本地资源上传至服务器。
1.GET、POST
我们平常都借助GET方法从服务器获取资源。POST用来将本地资源上传到服务器。
其实GET方法也可以用来上传资源,是通过uri来上传参数的。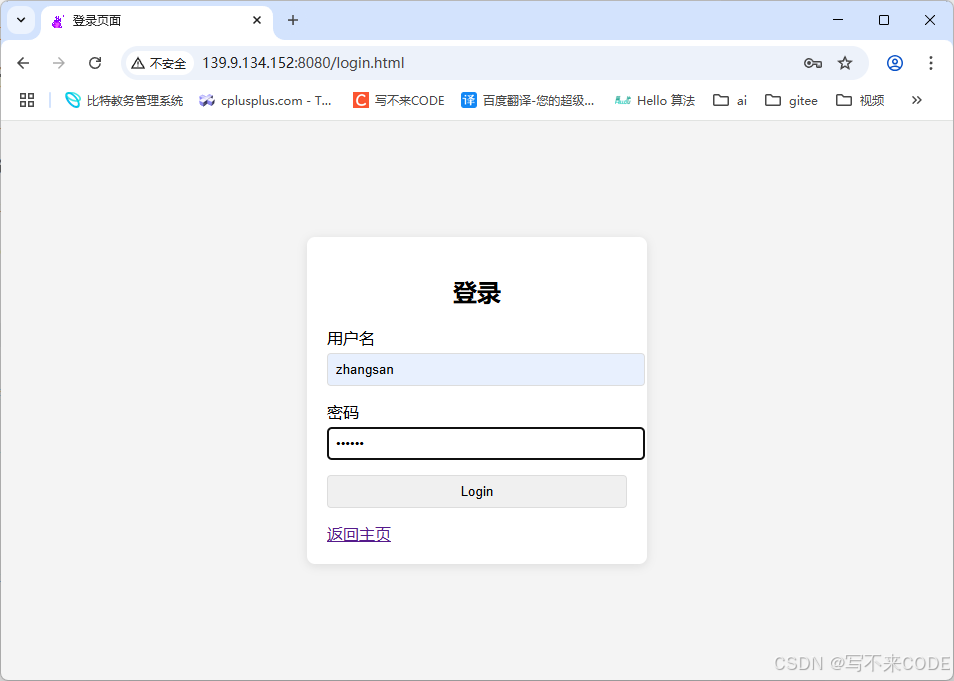
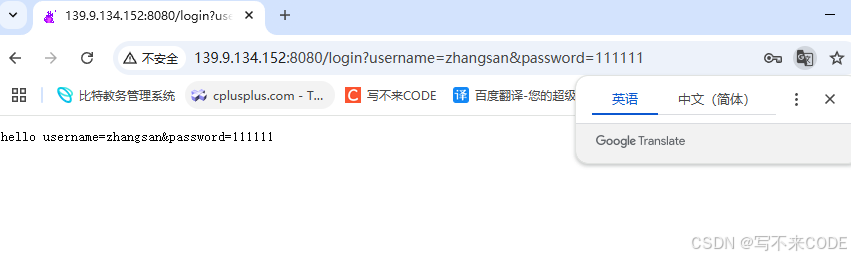
而post方法上传参数是通过正文来传参的。
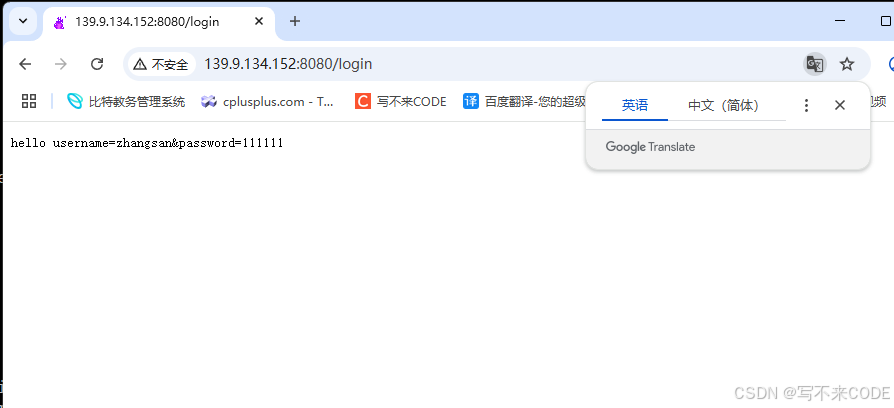
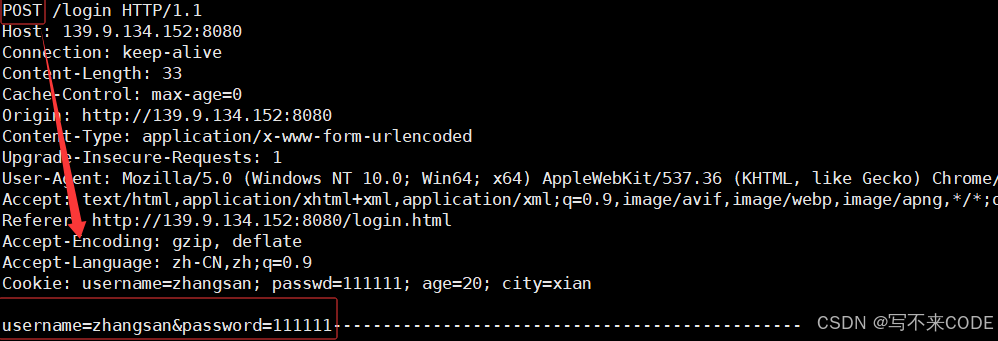
我们看到上面的实验结果,可以得出一下结论:
- GET提交参数,是通过uri提交的,且会回显参数,建议参数不要过长,因为uri的长度一般都是有限的。
- POST通过正文提交参数,不回显,更加私密。通过正文传递,就意味着可以传递长数据。
虽然说,POST和GET提交参数一个回显,一个通过正文,但是都不安全,因为可以被抓取。要做到真正的安全就得对报文进行加密——https协议。
这里还有其他的请求方法,但是GET和POST方法,已经可以覆盖大部分情况了。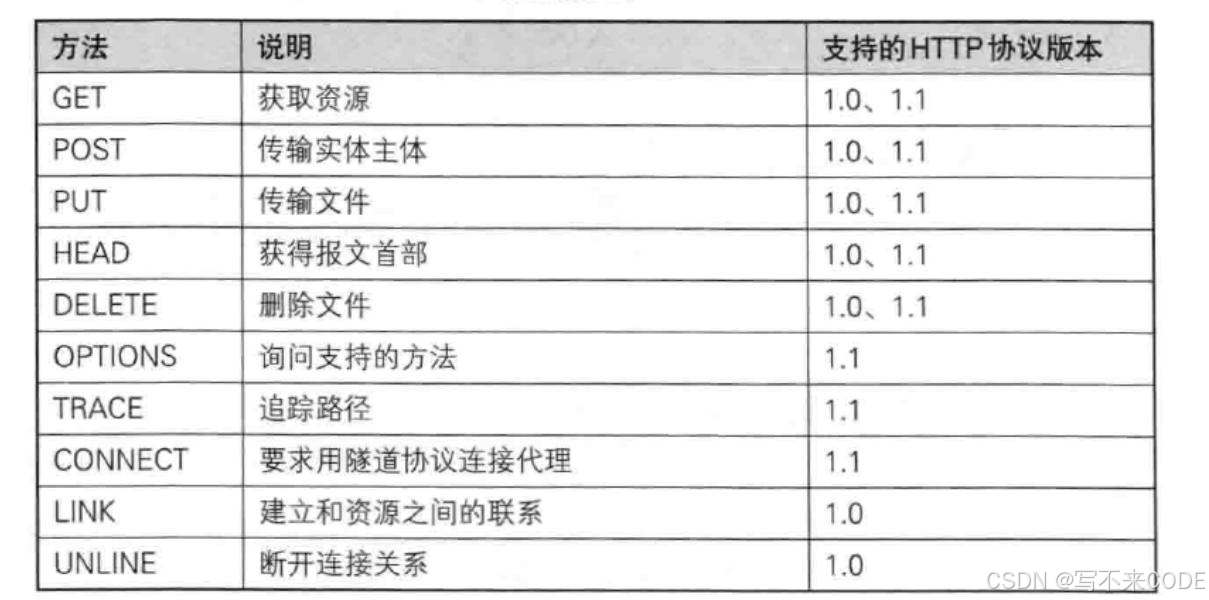

















 6140
6140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









