







词法分析是lucene的一个模块,lucene自带的中文分词器(analyzer)一般效果不是很理想。现在项目中用的分词工具是北理工的NLPIR,但是NLPIR没有一个现成的lucene分词器(analyzer)实现类。这里就需要自己来写一个比较简短的基于NLPIR的analyzer实现类。
不同的Analyzer就是组合不同的Tokenizer和TokenFilter得到最后的TokenStream。以StandardAnalyzer为例。以下代码截图来自StandardAnalyzer源码。红框中可以看到TokenFilter使用的是装饰者模式,Tokenizer和TokenFilter都继承自TokenStream类。
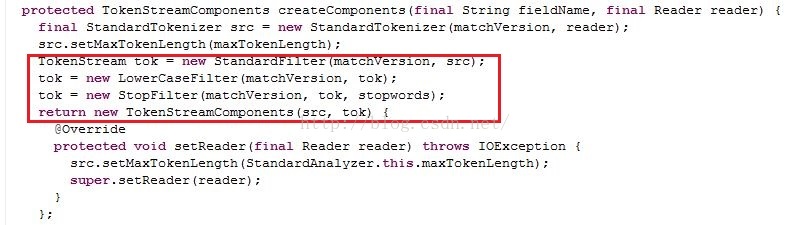
分词器实现一:基于lucene4.7.2
参考:http://www.360doc.com/content/12/0512/21/1542811_210601163.shtml
核心思想:用WhiteSpaceTokenizer分词器处理 NLPIR分词后的结果(词与词之间有空格作为间隔)。
代码:
import com.sun.jna.Library;
import com.sun.jna.Native;
public class NLPTool {
public interface CLibrary extends Library {
// 定义并初始化接口的静态变量
CLibrary Instance = (CLibrary) Native.loadLibrary("code/NLPIR",
CLibrary.class);
public int NLPIR_Init(String sDataPath, int encoding,
String sLicenceCode);
public String NLPIR_ParagraphProcess(String sSrc, int bPOSTagged);
public String NLPIR_GetKeyWords(String sLine, int nMaxKeyLimit,
boolean bWeightOut);
public String NLPIR_GetFileKeyWords(String sLine, int nMaxKeyLimit,
boolean bWeightOut);
public int NLPIR_AddUserWord(String sWord);// add by qp 2008.11.10
public int NLPIR_DelUsrWord(String sWord);// add by qp 2008.11.10
public String NLPIR_GetLastErrorMsg();
public void NLPIR_Exit();
}
public static String SegAndPos(String sInput,int type) {
String argu = ".";
String nativeBytes = "";
int charset_type = 1;
CLibrary.Instance.NLPIR_Init(argu, charset_type, "0");
try {
// CLibrary.Instance.NLPIR_AddUserWord("奇虎360 nt");
nativeBytes = CLibrary.Instance.NLPIR_ParagraphProcess(sInput, type); //第二个参数为1表示,进行词性标注。
CLibrary.Instance.NLPIR_Exit();
} catch (Exception ex) {
ex.printStackTrace();
}
return nativeBytes;
}
}
import java.io.Reader;
import org.apache.lucene.analysis.util.CharTokenizer;
import org.apache.lucene.util.Version;
/*
*@author:xyd
*@department:CasCeep
*/
public class MyChineseTokenizer extends CharTokenizer {
public MyChineseTokenizer(Reader in) {
super(Version.LUCENE_47, in);
}
public MyChineseTokenizer(AttributeFactory factory, Reader in) {
super(Version.LUCENE_47, in);
}
/*
* @see org.apache.lucene.analysis.util.CharTokenizer#isTokenChar(int)
*/
@Override
protected boolean isTokenChar(int c) {
return !Character.isWhitespace(c);
}
}import java.io.BufferedReader;
import java.io.IOException;
import java.io.Reader;
import java.io.StringReader;
import lucene.NLPTool;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.core.LowerCaseFilter;
import org.apache.lucene.analysis.core.StopFilter;
import org.apache.lucene.analysis.standard.StandardFilter;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionLengthAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.apache.lucene.analysis.util.CharArraySet;
import org.apache.lucene.util.Version;
/*
*@author:xyd
*@department:CasCeep
*/
public final class MyChineseAnalyzer extends Analyzer {
private CharArraySet stopWords;
/**
* An array containing some common English words that are not usually useful
* for searching.
*/
public static final String[] CHINESE_ENGLISH_STOP_WORDS = {"我", "的" };
/** Builds an analyzer which removes words in ENGLISH_STOP_WORDS. */
public MyChineseAnalyzer() {
this.stopWords = StopFilter.makeStopSet(Version.LUCENE_47,
CHINESE_ENGLISH_STOP_WORDS);
}
@Override
protected TokenStreamComponents createComponents(String arg0, Reader reader) {
// TODO Auto-generated method stub
BufferedReader br = new BufferedReader(reader);
Tokenizer tokenizer = null;
TokenStream tokFilter = null;
try {
String text = br.readLine();
String string = NLPTool.SegAndPos(text, 0);
// 分词中间加入了空格
tokenizer = new MyChineseTokenizer(new StringReader(string));
tokFilter = new StandardFilter(Version.LUCENE_47, tokenizer);
tokFilter = new LowerCaseFilter(Version.LUCENE_47, tokFilter);
// 使用stopWords进行过滤
tokFilter = new StopFilter(Version.LUCENE_47, tokFilter, stopWords);
} catch (IOException e) {
e.printStackTrace();
}
return new TokenStreamComponents(tokenizer, tokFilter);
}
public static void main(String[] args) throws IOException {
String string = "我的老师在中国科学院工作";
Analyzer analyzer = new MyChineseAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("field",
new StringReader(string));
tokenStream.reset();
while (tokenStream.incrementToken()) {
// 文本属性
CharTermAttribute attribute = tokenStream
.addAttribute(CharTermAttribute.class);
// 偏移量
OffsetAttribute offsetAtt = tokenStream
.addAttribute(OffsetAttribute.class);
// 距离增加量
PositionIncrementAttribute positionAttr = tokenStream
.addAttribute(PositionIncrementAttribute.class);
// 距离
PositionLengthAttribute posL = tokenStream
.addAttribute(PositionLengthAttribute.class);
// 词性
TypeAttribute typeAttr = tokenStream
.addAttribute(TypeAttribute.class);
System.out.println(offsetAtt.startOffset() + ":"
+ offsetAtt.endOffset() + "\t" + attribute + "\t"
+ typeAttr.type() + "\t" + posL.getPositionLength() + "\t"
+ positionAttr.getPositionIncrement());
}
}
}结果与说明
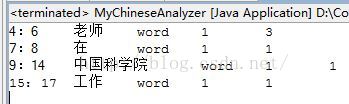
上面一共有三个类,NLPTool是对NLPIR这个分词工具进行封装的类,调用其中方法直接进行分词,在结果中我们可以看到,“我”和“的”这两个词语被认为是停止词直接过滤了。MyChineseTokenizer.java这个类直接拷贝lucene自带的源码WhitespaceTokenizer.java(其实直接使用WhitespaceTokenizer也没关系,但是考虑到下一步的工作,还是自己再新建一个类好了,以便修改)。
MyChineseAnalyzer是自定义analyzer的实现类,直接就在里面测试了。
参考资料
http://www.360doc.com/content/12/0512/21/1542811_210601163.shtml
http://itindex.net/detail/47940-lucene-lucene-%E5%AE%9A%E4%B9%89
http://www.cnblogs.com/forfuture1978/archive/2010/06/06/1752837.html
http://blog.csdn.net/jiejiuxunhuan/article/details/8534783
分词器实现二
上面的结果也可以看到,分词结果没有词性这一项(WhiteSpaceTokenizer分词器只分空格,词性都默认为word了),所以想把这个模块补上,上文提过要自定义一个analyzer要重新实现Tokenizer和TokenFilter这两个类,然而之前的实现方法相当于直接使用源码中的Tokenizer和TokenFilter,并没有做什么更改,所以要加入词性这一项,还要现实自己的Tokenizer类。
参考lucene的源码和另外两个项目的源码:
IKAnalyzer项目地址:http://git.oschina.net/wltea/IK-Analyzer-2012FF
Hanlp项目地址:http://hanlp.linrunsoft.com/
当然,除此之外,读相关的博客是必不可少的,例如下面两个博客地址:
http://blog.csdn.net/ddupd/article/details/26967225
http://www.blogjava.net/brock/archive/2015/01/07/422100.aspx
这些人都是使用NLPIR(前身是ictclas)实现lucene的自定义analyzer。因本人使用java,故参考了第二个网址,然而对于博客中的以下两个类,并不理解。

虽然直接拷贝代码不能实现,但是还是具有一定的参考意义。
================================我是分割线======================================
上面扯了那么多,都是我的学习过程。下面还是老样子,直接进入正题,先看结构图,再上代码,代码基本上是一拷贝就能使用的。

图中框中的就是所有的代码了,代码一个一个上。
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Tokenizer;
/**
*@author:xyd
*@department:CasCeep
*/
public class MyAnalyzer extends Analyzer {
public MyAnalyzer() {
super();
}
@Override
protected TokenStreamComponents createComponents(String fieldName,
Reader reader) {
Tokenizer tokenizer = new MyTokenizer(reader);
return new TokenStreamComponents(tokenizer);
}
}package lucene.v41;
import java.io.BufferedReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import lucene.NLPTool;
/**
*@author:xyd
*@department:CasCeep
*特别说明下:我这段代码参考自hankcs的hanlp中源码。在此特别感谢这些优秀开源项目提供的学习机会。
*/
public class MySegment {
BufferedReader br;
// 因为next是单个term出去的,所以在这里做一个记录
Term[] termArray;
// termArray下标
int index;
// term的偏移量,由于wrapper是按行读取的,必须对term.offset做一个校正
int offset;
Pattern pattern = Pattern.compile("/[a-z\\d]+");
public MySegment(BufferedReader br) {
this.br = br;
}
public Term next() throws IOException {
if (termArray != null && index < termArray.length)
return termArray[index++];
String line = br.readLine();
while (isBlank(line)) {
if (line == null)
return null;
offset += line.length() + 1;
line = br.readLine();
}
List<Term> termList = segToTermList(line);
if (termList.size() == 0)
return null;
termArray = termList.toArray(new Term[0]); // 这里有个list转数组的方法,可以记下来
for (Term term : termArray) {
term.offset += offset;
}
index = 0;
offset += line.length() + 1;
return termArray[index++];
}
int startP = 0;
/**
* NLPIR在这个方法中进行分词,提取词性和词语,并且记录初始位置
*/
public List<Term> segToTermList(String text) {
String res = NLPTool.SegAndPos(text, 1);// 1表示进行词性标注
String[] words = res.split("\\s+"); // nlp的分词结果是每个词都有空格分开
List<Term> list = new ArrayList<Term>();
for (String WordAndPos : words) {
Term xTerm = new Term();
Matcher m = pattern.matcher(WordAndPos);
while (m.find()) {
String pos = m.group();
xTerm.nature = pos.substring(1); // 去掉词性符号“/”
xTerm.word = WordAndPos.replace(pos, "");
xTerm.offset = startP;
}
startP = startP + xTerm.word.length();
list.add(xTerm);
}
return list;
}
/**
* 重置分词器
*/
public void reset(BufferedReader br) {
this.br = br;
termArray = null;
index = 0;
offset = 0;
}
/**
* 判断字符串是否为空(null和空格)
*/
private static boolean isBlank(CharSequence cs) {
int strLen;
if (cs == null || (strLen = cs.length()) == 0) {
return true;
}
for (int i = 0; i < strLen; i++) {
if (!Character.isWhitespace(cs.charAt(i))) {
return false;
}
}
return true;
}
}
package lucene.v41;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.Reader;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
/**
*@author:xyd
*@department:CasCeep
*/
public class MyTokenizer extends Tokenizer {
// 当前词
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
// 偏移量
private final OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
// 距离
private final PositionIncrementAttribute positionAttr = addAttribute(PositionIncrementAttribute.class);
// 词性
private TypeAttribute typeAtt = addAttribute(TypeAttribute.class);
protected MySegment segment;
protected MyTokenizer(Reader input) {
super(input);
segment = new MySegment(new BufferedReader(input));
}
@Override
public boolean incrementToken() throws IOException {
clearAttributes();
Term term = segment.next();
if (term != null) {
positionAttr.setPositionIncrement(1); //没有停止词和过滤词,所以设为1,其实这项都可以不要。
termAtt.setEmpty().append(term.word);
offsetAtt.setOffset(term.offset, term.offset + term.word.length());
typeAtt.setType(term.nature);
return true;
} else {
return false;
}
}
@Override
public void reset() throws IOException {
super.reset();
segment.reset(new BufferedReader(this.input));
}
}
下面的是词语封装类
package lucene.v41;
/**
*@author:xyd
*@department:CasCeep
*/
public class Term {
// 词语
public String word;
// 词性
public String nature;
// 在文本中的开始位置
public int offset;
@Override
public String toString() {
return word + "/" + nature;
}
}见上文的NLPTool.java
测试类
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
/**
*@author:xyd
*@department:CasCeep
*/
public class MyAnalyzerTest {
public static void main(String[] args) throws IOException {
String text = "我是工程师,我是夜行动物!";
Analyzer analyzer = new MyAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("field", text);
tokenStream.reset();
while (tokenStream.incrementToken()) {
//文本属性
CharTermAttribute attribute = tokenStream
.getAttribute(CharTermAttribute.class);
// 偏移量
OffsetAttribute offsetAtt = tokenStream
.getAttribute(OffsetAttribute.class);
// 距离
PositionIncrementAttribute positionAttr = tokenStream
.getAttribute(PositionIncrementAttribute.class);
// 词性
TypeAttribute typeAttr = tokenStream
.getAttribute(TypeAttribute.class);
System.out.println("["+offsetAtt.startOffset()+":"+
offsetAtt.endOffset()+"]"+"\t"+positionAttr.getPositionIncrement()+"\t"+
attribute+"\t词性:"+typeAttr.type());
}
}
}结果展示和小结:
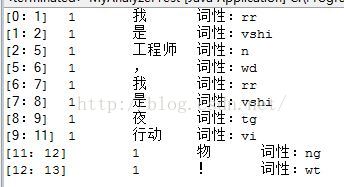
好了,到这里为止,基本上已经实现了Tokenizer类了,lucene模块也差不多就这样了,如果还要做文章的话,就考虑实现一些TokenFilter类了。以后项目中用到,我再添加好了,但是基本使用就如上文所示的了!
代码下载:http://download.csdn.net/detail/xsdxs/9309683















 2405
2405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









