







1 背景
之前工作都是把spark程序打包好,上传到公司的集群环境后进行代码调试!一个spark程序用maven打包后往往有100M左右,上传调试很不方便。spark可以local单机运行,所以就在eclipse上搭建了一个单机调试环境。
2 环境配置
首先需要配置java(版本:1.8)以及maven(版本:3.3.9)环境,版本不要求一致,也可使用其他java和maven版本配置开发环境。这两者配置在此不做介绍。
1. Window 7 下装hadoop 2.6.4,需要下载两个文件:
Hadoop:hadoop-2.6.4.tar.gz
下载地址:http://hadoop.apache.org/releases.html
Hadoop-Common:hadoop2.6(x64)V0.2.zip(2.4以后)、(hadoop-common-2.2.0-bin-master.zip)
下载地址:http://download.csdn.net/detail/myamor/8393459
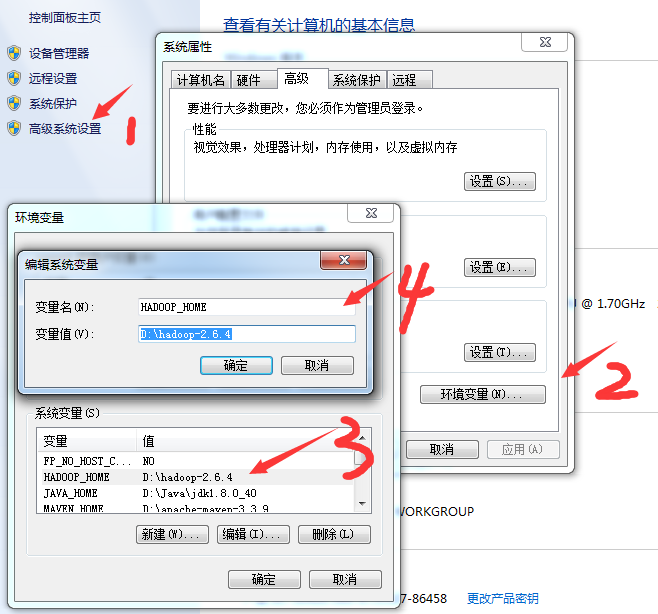
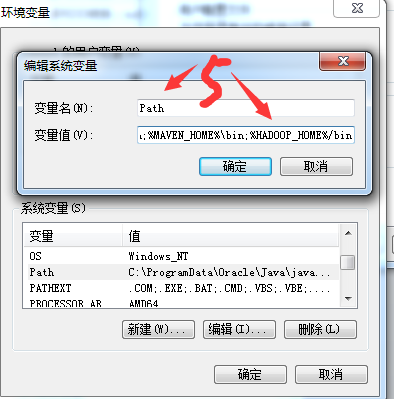
2. 配置hadoop_home环境变量
把hadoop-2.6.4.tar.gz解压到某个路径,如:D:\hadoop-2.6.4。新建HADOOP_HOME,并把%HADOOP_HOME%\bin加到path中。环境变量配置流程,如下图。
3.拷贝Hadoop-Common 下的文件
官方下载的Apache hadoop 2.6.4的压缩包里,缺少windows下运行的链接库(hadoop.dll,winutils.exe,libwinutils.lib等)。下载Hadoop-Common后直接解压,把里面的文件全部拷贝到官方hadoop目录下的bin目录即可。
缺少winutils.exe,否则运行会报如下错误:
java.io.IOException: Could not locate executable D:\hadoop-2.6.4\bin\winutils.exe in the Hadoop binaries.
3 maven pom 依赖
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}\lib\tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
</dependency>4 代码
经典案例,词频统计。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class WordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("wordCountTest");
JavaSparkContext sc = new JavaSparkContext(conf);
String outputDir=args[0];
List<String> list=new ArrayList<String>();
list.add("1 1 2 a b");
list.add("a b 1 2 3");
JavaRDD<String> RddList=sc.parallelize(list);
//先切分为单词,扁平化处理
JavaRDD<String> flatMapRdd = RddList.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String str) {
return Arrays.asList(str.split(" "));
}
});
//再转化为键值对
JavaPairRDD<String, Integer> pairRdd = flatMapRdd.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
//对每个词语进行计数
JavaPairRDD<String, Integer> countRdd = pairRdd.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
System.out.println("结果:"+countRdd.collect());
countRdd.saveAsTextFile(outputDir);
sc.close();
}
}5 运行以及结果
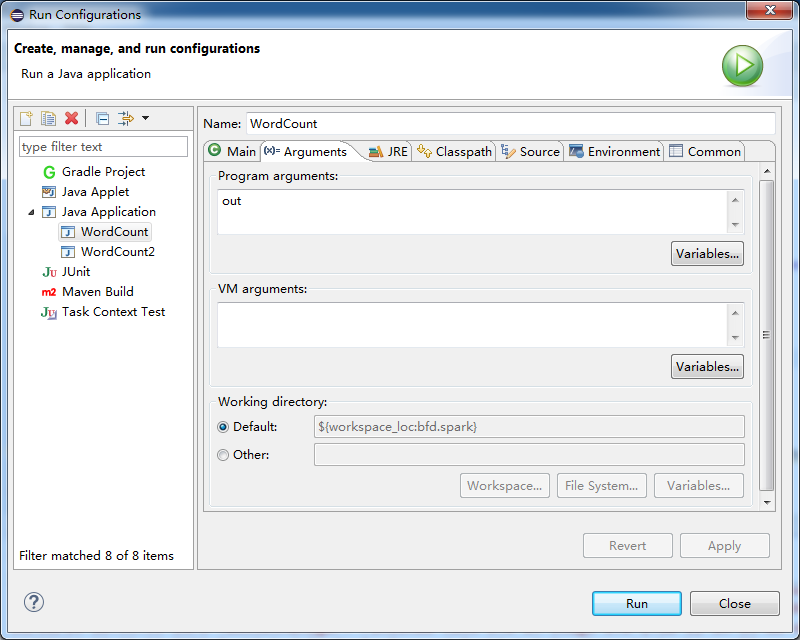
- 运行:Eclipse 下Run Configuration输入参数out。注意,输出目录必须不存在,否则报错。
- 结果
结果1:控制台正常输出,且不报错。
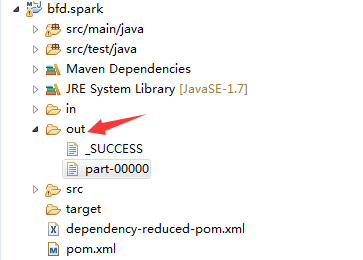
结果2:生成一个out文件
其中part-00000内容为:
(a,2)
(b,2)
(2,2)
(3,1)
(1,3)

6 下载
这是jdk 1.8的工程项目,如果不是jdk1.8,需要在pom.xml 中进行修改成对应版本,然后执行 maven –>update project 命令,进行更新
http://download.csdn.net/download/xsdxs/9602880

















 980
980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









