







参考以下两个网址,但运行报错,以下是我自己改进方式和使用总结。
https://github.com/medcl/elasticsearch-analysis-ik/issues/93
http://elasticsearch.cn/?/question/29
本文前提默认已经装好ES和IK插件。
1:elasticserach.yml 最后一行添加如下内容(该文件位于elasticsearch-x.x.x/config目录下):
index.analysis.analyzer.default.type: ik
2:在elasticsearch-x.x.x/config目录下新建同义词文件synonyms.txt。
其中,synonyms.txt 编码格式为’utf-8’,内容建议为空。
3:创建索引
curl -XPUT localhost:9200/test -d'
{
"settings": {
"index": {
"analysis": {
"analyzer": { "jt_cn": { "type": "custom", "use_smart": "true", "tokenizer": "ik_smart", "filter": ["jt_tfr","jt_sfr"], "char_filter": ["jt_cfr"] }, "ik_smart": { "type": "ik", "use_smart": "true" }, "ik_max_word": { "type": "ik", "use_smart": "false" } },
"filter": { "jt_tfr": { "type": "stop", "stopwords": [" "] }, "jt_sfr": { "type": "synonym", "synonyms_path": "synonyms.txt" } },
"char_filter": { "jt_cfr": { "type": "mapping", "mappings": [ "| => \\|" ] } }
}
}
}
}'4:创建映射
curl -X PUT localhost:9200/test/haizhi/_mapping -d '{
"haizhi": {
"properties": {
"title": {
"include_in_all": true,
"analyzer": "jt_cn",
"term_vector": "with_positions_offsets",
"boost": 8,
"store": true,
"type": "string"
}
}
}
}'5:插入数据
curl -XPUT localhost:9200/test/haizhi/1 -d '{
"title": "番茄"
}'
curl -XPUT localhost:9200/test/haizhi/2 -d '{
"title": "西红柿"
}'
curl -XPUT localhost:9200/test/haizhi/3 -d '{
"title": "我是西红柿"
}'
curl -XPUT localhost:9200/test/haizhi/4 -d '{
"title": "我是番茄"
}'
curl -XPUT localhost:9200/test/haizhi/5 -d '{
"title": "土豆"
}'
curl -XPUT localhost:9200/test/haizhi/6 -d '{
"title": "aa"
}'6:查询1
curl -XPOST 'localhost:9200/test/haizhi/_search?pretty' -d '
{
"query": {
"match_phrase": {
"title": {
"query": "西红柿",
"analyzer": "jt_cn"
}
}
},
"highlight": {
"pre_tags": [
"<tag1>",
"<tag2>"
],
"post_tags": [
"</tag1>",
"</tag2>"
],
"fields": {
"title": {}
}
}
}'- 结果如下

7:查询2
我们知道“西红柿”和“番茄”是同义词,我们在同义词词典(synonyms.txt)中添加如下内容,并重启ES,再用第6步的查询。
#Example:
西红柿, 番茄- 结果如下,成功匹配同义词

8:查询3
修改同义词词典(synonyms.txt)为如下内容,重启ES。
#Example:
西红柿, 番茄
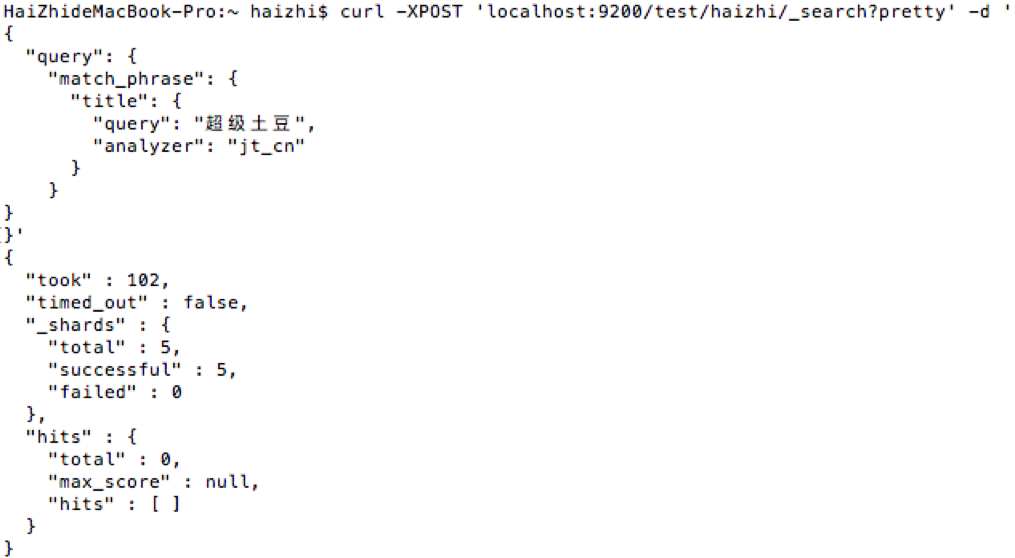
超级土豆, 土豆查询如下:
curl -XPOST 'localhost:9200/test/haizhi/_search?pretty' -d '
{
"query": {
"match_phrase": {
"title": {
"query": "超级土豆",
"analyzer": "jt_cn"
}
}
}
}'- 结果如下,查不到结果
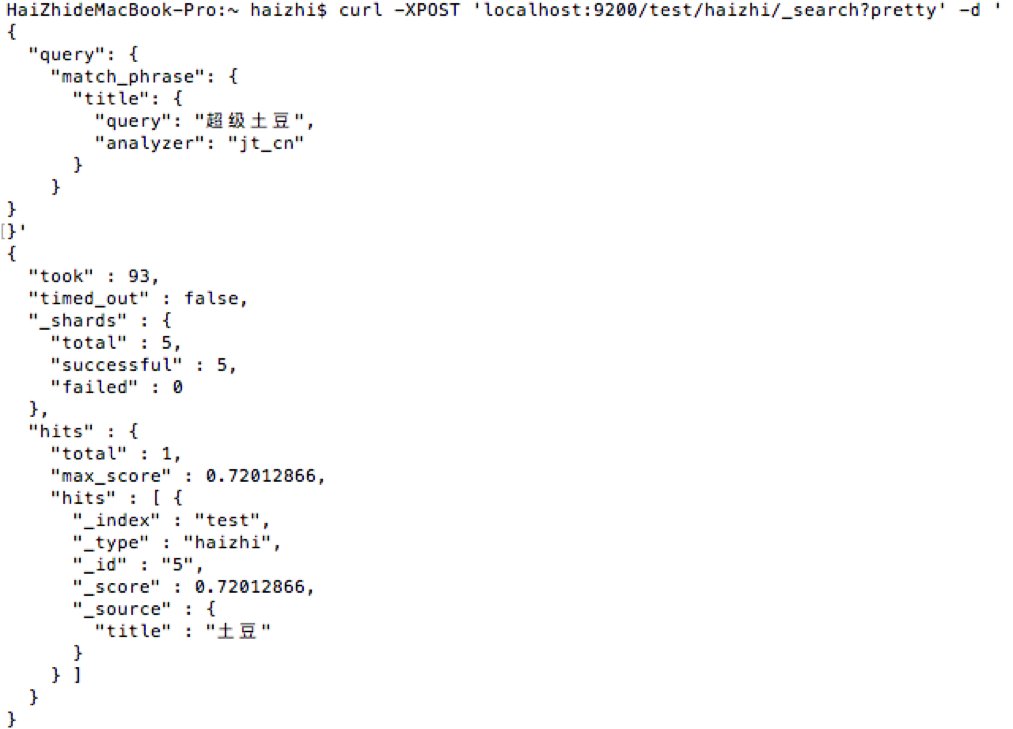
9:查询4
在{plugins}/elasticsearch-analysis-ik-*/config/custom/mydict.dic词典中新加“超级土豆”一词,并且重启ES。
- 结果如下,成功用“超级土豆”搜索到“土豆”一词
10:小结
- 同义词字典或是IK用户自定义词典更新,必须每次重启elasticsearch才有效。
- 同义词词对是必须能被完成切分的词语。
比如在synonyms.txt 文件中增加同义词对: ‘超级土豆’ – ‘土豆’ 。但在实际的搜索中用“超级土豆”是搜不到“土豆”的。因为“超级土豆”会被切分为多个词语。必须在{plugins}/elasticsearch-analysis-ik-*/config/custom/mydict.dic词典中新加“超级土豆”一词,才能用“超级土豆”一词搜出“土豆”。

















 8711
8711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









