







1.什么是SPI?
SPI的全称是Service Provider Interface, 直译过来就是"服务提供接口",为了降低耦合,实现在模块装配的时候动态指定具体实现类的一种服务发现机制。动态地为接口寻找服务实现。它的核心来自于ServiceLoader这个类。
java SPI应用场景很广泛,在Java底层和一些框架中都很常用,比如java数据驱动加载。Java底层定义加载接口后,由不同的厂商提供驱动加载的实现方式,当我们需要加载不同的数据库的时候,只需要替换数据库对应的驱动加载jar包,就可以进行使用。。
Spring和Dubbo也在java spi机制之上定义了自己的SPI机制。
1.1SPI和API的区别?
API(Application Programming Interface)
大多数情况下,都是实现方来制定接口并完成对接口的不同实现,调用方仅仅依赖却无权选择不同实现。
SPI(Service Provider Interface)
调用方来制定接口,实现方来针对接口来实现不同的实现。调用方来选择自己需要的实现方。
RPC 框架有很多可扩展的地方,如:序列化类型、压缩类型、负载均衡类型、注册中心类型等等。
假设框架提供的注册中心只有zookeeper,但是使用者想用Nacos、Eureka等,修改框架以支持使用者的需求显然不是好的做法。
最好的做法就是留下扩展点,让使用者可以不需要修改框架,就能自己去实现扩展。
2.JDK SPI机制
要使用Java SPI,需要遵循如下约定:
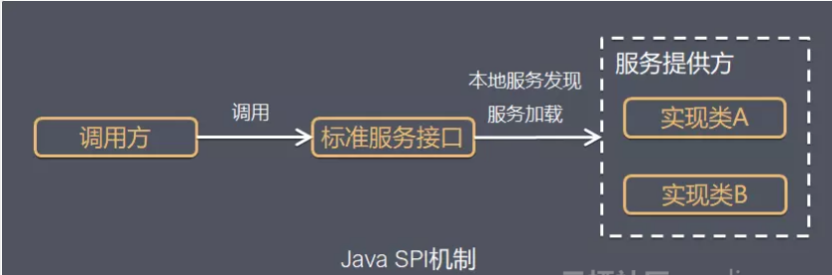
1、当服务提供者提供了接口的一种具体实现后,在jar包的META-INF/services目录下创建一个以“接口全限定名”为命名的文件,内容为实现类的全限定名(约定大于配置的体现);
2、接口实现类所在的jar包放在主程序的classpath中;
3、主程序通过java.util.ServiceLoader动态装载实现模块,它通过扫描META-INF/services目录下的配置文件找到实现类的全限定名,把类加载到JVM;
4、SPI的实现类必须携带一个不带参数的构造方法
以序列化为例
先设计一个序列化接口
public interface Serializer {
/**
* 序列化
*
* @param obj 要序列化的对象
* @return 字节数组
*/
byte[] serialize(Object obj);
/**
* 反序列化
*
* @param bytes 序列化后的字节数组
* @param clazz 目标类
* @param <T> 类的类型。举个例子, {@code String.class} 的类型是 {@code Class<String>}.
* 如果不知道类的类型的话,使用 {@code Class<?>}
* @return 反序列化的对象
*/
<T> T deserialize(byte[] bytes, Class<T> clazz);
}
实现JSON序列化 jackson包来处理
public class JsonSerializer implements Serializer {
private static final Logger logger = LoggerFactory.getLogger(JsonSerializer.class);
private ObjectMapper objectMapper = new ObjectMapper();
@Override
public byte[] serialize(Object obj) {
try {
return objectMapper.writeValueAsBytes(obj);
} catch (JsonProcessingException e) {
logger.error("序列化时有错误发生: {}", e.getMessage());
e.printStackTrace();
return null;
}
}
@Override
public Object deserialize(byte[] bytes, Class<?> clazz) {
try {
Object obj = objectMapper.readValue(bytes, clazz);
if(obj instanceof RpcRequest) {
obj = handleRequest(obj);
}
return obj;
} catch (IOException e) {
logger.error("反序列化时有错误发生: {}", e.getMessage());
e.printStackTrace();
return null;
}
}
/*
这里由于使用JSON序列化和反序列化Object数组,无法保证反序列化后仍然为原实例类型
需要重新判断处理
*/
private Object handleRequest(Object obj) throws IOException {
RpcRequest rpcRequest = (RpcRequest) obj;
for(int i = 0; i < rpcRequest.getParamTypes().length; i ++) {
Class<?> clazz = rpcRequest.getParamTypes()[i];
if(!clazz.isAssignableFrom(rpcRequest.getParameters()[i].getClass())) {
byte[] bytes = objectMapper.writeValueAsBytes(rpcRequest.getParameters()[i]);
rpcRequest.getParameters()[i] = objectMapper.readValue(bytes, clazz);
}
}
return rpcRequest;
}
}
public class ProtostuffSerializer implements Serializer {
/**
* Avoid re applying buffer space every time serialization
*/
private static final LinkedBuffer BUFFER = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
@Override
public byte[] serialize(Object obj) {
Class<?> clazz = obj.getClass();
Schema schema = RuntimeSchema.getSchema(clazz);
byte[] bytes;
try {
bytes = ProtostuffIOUtil.toByteArray(obj, schema, BUFFER);
} finally {
BUFFER.clear();
}
return bytes;
}
@Override
public <T> T deserialize(byte[] bytes, Class<T> clazz) {
Schema<T> schema = RuntimeSchema.getSchema(clazz);
T obj = schema.newMessage();
ProtostuffIOUtil.mergeFrom(bytes, obj, schema);
return obj;
}
}
在 resources/META-INF/services 目录下添加一个 com.xsj.Serializer 的文件,这是 JDK SPI 的配置文件:
com.xxx.JsonSerializer
com.xxx.ProtostuffSerializer
如何使用 SPI 将实现类加载出来呢?
public static void main(String[] args) {
ServiceLoader<Serializer> serviceLoader = ServiceLoader.load(Serializer.class);
Iterator<Serializer> iterator = serviceLoader.iterator();
while (iterator.hasNext()) {
Serializer serializer= iterator.next();
System.out.println(serializer.getClass().getName());
}
}
输出如下:
com.xsj.JSONSerializer
com.xsj.ProtostuffSerializer
那么具体是如何实现的呢?
先看看JDK SPI的缺点
2.1JDK SPI机制的原理分析
先从源码来看看JDK SPI是如何实现的?
JDK SPI机制是一种服务发现机制,动态地为接口寻找服务实现。它的核心来自于ServiceLoader这个类。
一下源码分析 参考博文:
https://zhuanlan.zhihu.com/p/266553920
梳理的非常清除
测试代码:
ServiceLoader<Fruit> serviceLoader = ServiceLoader.load(Fruit.class);
Iterator<Fruit> iterator = serviceLoader.iterator();
while (iterator.hasNext()) {
Fruit fruit = iterator.next();
System.out.println(fruit.getName());
}
ServiceLoader#load(java.lang.Class<S>)
public static <S> ServiceLoader<S> load(Class<S> service) {
// 获取当前线程的ClassLoader
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
ps:这个上下文getContextClassLoader 打破了双亲委派机制 可以寻找第三方实现类进行加载
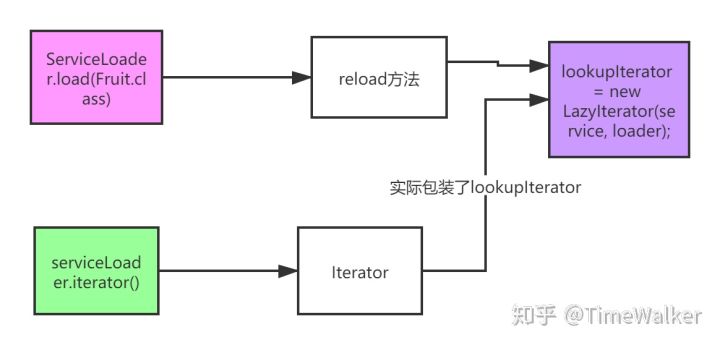
ServiceLoader.load(service, cl);最终会调用下面的构造器
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
reload()方法需要关注一下
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
这里创建了LazyIterator
总结一下:
-
ServiceLoader#load(java.lang.Class<S>) -
-
ServiceLoader.load(service, cl)、 -
-
ServiceLoader#reload -
new LazyIterator
-
-
可见,ServiceLoader#load(Class<S>)实际上是创建了一个LazyIterator迭代器对象。
serviceLoader.iterator()
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
// 核心
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
// 核心
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
这里创建了一个
Iterator,当我们调用它的hasNext方法时,debug走下来看,其实就是调用LazyIterator#hasNext方法,然后会调用hasNextService方法。
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
这里先总结一下,通过
serviceLoader.iterator()方法创建的Iterator对象,它的hasNext方法和next方法实际上是调用了LazyIterator中的对应方法,所以真正的主角就是LazyIterator对象。
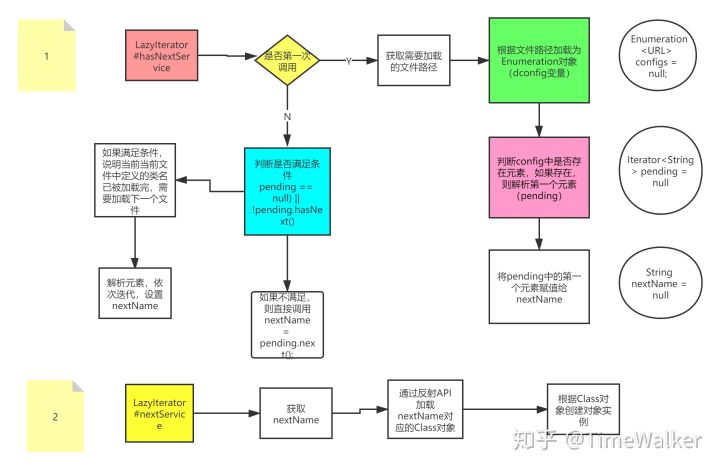
LazyIterator#hasNextService
private boolean hasNextService() {
if (nextName != null) {
return true;
}
// 如果不是第一次执行,configs !=null ,不仅会进入第一个判断
if (configs == null) {
try {
// 文件名:META-INF/services/cn.ajin.practical.java.spi.Fruit
// service.getName() : 类名,这里就是 cn.ajin.practical.java.spi.Fruit
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
// 根据fullName获取Enumeration对象
configs = loader.getResources(fullName);
} catch (IOException x) {
...
}
}
while ((pending == null) || !pending.hasNext()) {
// 判断元素是否存在
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
总结LazyIterator迭代原理
原理总结
到这里,我想大家对于ServiceLoader加载定义好的实现类的原理应该有比较清晰的了解吧,其实就是先获取文件名(配置文件),并根据文件名获取一个Enumeration对象,再去迭代,最终创建实现类对象。
JDK SPI机制的优缺点
-
优点:JDK SPI使得我们可以面向接口编程,无需硬编码的方式即可引入实现类
-
缺点:
-
- 不能按需加载,虽然
ServiceLoader做了延迟载入,但是基本只能通过遍历全部获取,也就是接口的实现类得全部载入并实例化一遍。就是接口的实现类得全部载入并实例化一遍。如果你并不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,这就造成了浪费。 - 多线程并发场景下加载是线程不安全的
- 不能按需加载,虽然
通过上面的例子,我们可以了解到 SPI 的简单用法以及优缺点。接下来,我们就来看增强版的 SPI 是如何实现的,又增强在哪里。
3.增强版 SPI
我们先来看看增强版 SPI 是如何使用的吧,还是拿序列化来举例。
- 定义接口,接口加上
@SPI注解
@SPI
public interface Serializer {
/**
* 序列化
*
* @param obj 要序列化的对象
* @return 字节数组
*/
byte[] serialize(Object obj);
/**
* 反序列化
*
* @param bytes 序列化后的字节数组
* @param clazz 目标类
* @param <T> 类的类型。举个例子, {@code String.class} 的类型是 {@code Class<String>}.
* 如果不知道类的类型的话,使用 {@code Class<?>}
* @return 反序列化的对象
*/
<T> T deserialize(byte[] bytes, Class<T> clazz);
}
-
实现类,这个代码跟上面的一模一样,就不重复贴代码了
-
配置文件 key=val对的形式
kyro=com.xsj.serialize.kyro.KryoSerializer
protostuff=com.xsj.serialize.protostuff.ProtostuffSerializer
- 获取扩展类,我们可以只实例化想要的实现类,实现按名称加载
public static void main(String[] args) {
ExtensionLoader<Serializer> loader = ExtensionLoader.getLoader(Serializer.class);
Serializer serializer = loader.getExtension("protostuff");
System.out.println(serializer.getClass().getName());
}
3.1增强版SPI机制
增强版针对JDK SPI机制的两个缺点进行了改进。
3.1.1改进策略
1.不能按需加载:
JDK SPI 在查找实现类的时候,需要遍历配置文件中定义的所有实现类,而这个过程会把所有实现类都实例化。一个接口如果有很多实现类,而我们只需要其中一个的时候,就会产生其他不必要的实现类。 例如 Dubbo 的序列化接口,实现类就有 fastjson、gson、hession2、jdk、kryo、protobuf 等等,通常我们只需要选择一种序列化方式。如果用 JDK SPI,那其他没用的序列化实现类都会实例化,实例化所有实现类明显是资源浪费!
解决方法:采用按实现类名称进行加载
2.线程安全问题
采用线程同步方案中的 阻塞式同步 synchronized解决 线程安全问题。
3.1.2改进具体实现
3.1.1扩展类实例按名称加载
ExtensionLoader.getExtension(String name)
/**
* 指定名称扩展点
* 通过配置的对象名称 拿到对应的实例
* 先从缓存中拿 holder引用,如果没有就先put进去这个holder
* 如果从holder中拿不到 证明这个实例还没有创建 就就调用createExtension 注意DCL懒汉式单例
* @param name
* @return
*/
public T getExtension(String name) {
if (name == null || name.isEmpty()) {
throw new IllegalArgumentException("Extension name should not be null or empty.");
}
// firstly get from cache, if not hit, create one
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<>());
holder = cachedInstances.get(name);
}
// create a singleton if no instance exists
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
}
参考 dubbo实现
这是一个典型的 double-check 懒汉单例实现,当程序需要某个实现类的时候,才会去真正初始化它。
会先去缓存中获取,获取不到DCL懒汉单例模式去初始化
3.1.2配置文件格式
配置文件采用的格式参考 dubbo,示例:
kyro=com.xsj.serialize.kyro.KryoSerializer
protostuff=com.xsj.serialize.protostuff.ProtostuffSerializer
采用 key-value 的配置格式有个好处就是,要获取某个类型的扩展,可以直接使用名字来获取,可以大大提高可读性。
加载配置文件
/**
* 1.从缓存当中获取加载扩展实现类 返回一个map<实现类名name,类实例>
* 2.如果是空的就DCL懒汉式创造 这类对象
* 3.DCL创造单例模式中设计到去 扩展目录中去加载文件
* 4.最后拿到指定的类实例
* @return
*/
private Map<String, Class<?>> getExtensionClasses() {
// get the loaded extension class from the cache
Map<String, Class<?>> classes = cachedClasses.get();
// double check
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
classes = new HashMap<>();
// load all extensions from our extensions directory
loadDirectory(classes);
cachedClasses.set(classes);
}
}
}
return classes;
}
/**
*
* @param extensionClasses
*/
private void loadDirectory(Map<String, Class<?>> extensionClasses) {
//文件名为 文件路径 "META-INF/extensions/"+ 类对象名称 例如 netty
String fileName = ExtensionLoader.SERVICE_DIRECTORY + type.getName();
try {
Enumeration<URL> urls;
//拿到当前类的类加载器
ClassLoader classLoader = ExtensionLoader.class.getClassLoader();
//加载 资源
urls = classLoader.getResources(fileName);
if (urls != null) {
while (urls.hasMoreElements()) {
URL resourceUrl = urls.nextElement();
//根据URL拿到该类 见下面的方法 根据扩展点和ExtensionLoader的类加载器 去指定url下进行类加载放到extensionClasses中
loadResource(extensionClasses, classLoader, resourceUrl);
}
}
} catch (IOException e) {
log.error(e.getMessage());
}
}
/**
* 根据扩展点和ExtensionLoader的类加载器 去指定url下进行类加载放到extensionClasses中
* @param extensionClasses
* @param classLoader
* @param resourceUrl
*/
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader, URL resourceUrl) {
//创建 指定对应URL的输入流
try (BufferedReader reader = new BufferedReader(new InputStreamReader(resourceUrl.openStream(), UTF_8))) {
String line;
// read every line 开始读文件
while ((line = reader.readLine()) != null) {
// get index of comment
final int ci = line.indexOf('#');
if (ci >= 0) {
// string after # is comment so we ignore it
line = line.substring(0, ci);
}
line = line.trim();
if (line.length() > 0) {
try {
final int ei = line.indexOf('=');
String name = line.substring(0, ei).trim();
String clazzName = line.substring(ei + 1).trim();
// our SPI use key-value pair so both of them must not be empty
if (name.length() > 0 && clazzName.length() > 0) {
Class<?> clazz = classLoader.loadClass(clazzName);
//放到extensionClasses 中
extensionClasses.put(name, clazz);
}
} catch (ClassNotFoundException e) {
log.error(e.getMessage());
}
}
}
} catch (IOException e) {
log.error(e.getMessage());
}
}
核心流程其实和JDK SPI 类似 也是去指定文件加载 资源 然后将加载到的class文件缓存起来。
3.1.2扩展类的创建
通过反射创建扩展类
当获取扩展类不存在时,会加锁实例化扩展类。实例化的流程如下:
- 从配置文件中,加载该接口所有的实现类的 Class 对象,并放到缓存中。
- 根据要获取的扩展名字,找到对应的 Class 对象。
- 调用
clazz.newInstance()实例化。(Class 需要有无参构造函数)
private T createExtension(String name) {
// 获取当前类型所有扩展类
Map<String, Class<?>> extensionClasses = getAllExtensionClasses();
// 再根据名字找到对应的扩展类
Class<?> clazz = extensionClasses.get(name);
return (T) clazz.newInstance();
}
3.1.3加载器缓存
加载器指的就是 ExtensionLoader<T>,为了减少对象的开销,屏蔽了加载器的构造函数,提供了一个静态方法来获取加载器。
//缓存ExtensionLoader
private static final Map<Class<?>, ExtensionLoader<?>> EXTENSION_LOADERS = new ConcurrentHashMap<>();
/**
* 两个限制条件: 是否为interface; 是否spi注解
* @param type
* @param <S>
* @return
*/
public static <S> ExtensionLoader<S> getExtensionLoader(Class<S> type) {
if (type == null) {
throw new IllegalArgumentException("Extension type should not be null.");
}
//必须包含interface
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type must be an interface.");
}
//必须有SPI注解
if (type.getAnnotation(SPI.class) == null) {
throw new IllegalArgumentException("Extension type must be annotated by @SPI");
}
// firstly get from cache, if not hit, create one
ExtensionLoader<S> extensionLoader = (ExtensionLoader<S>) EXTENSION_LOADERS.get(type);
if (extensionLoader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<S>(type));
extensionLoader = (ExtensionLoader<S>) EXTENSION_LOADERS.get(type);
}
return extensionLoader;
}
EXTENSION_LOADERS缓存了各种类型的加载器。获取的时候先从缓存获取,缓存不存在则去实例化,然后放到缓存中。这是一个很常见的缓存技巧。
3.1.4默认扩展
NettyRPC提供了默认扩展的功能,接口在使用 @SPI (自定义注解)的时候可以指定一个默认的实现类名
这样当获取扩展名留空没有配置的时候,就会直接获取默认扩展,减少了配置的量。
在扩展类的构造函数中,会从 @SPI 中获取 value(),把默认扩展名缓存起来。
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface SPI {
/**
* 默认扩展类全路径
*
* @return 默认不填是 default
*/
String value() default URLKeyConst.DEFAULT;
}
private final String defaultNameCache;
private ExtensionLoader(Class<T> type) {
this.type = type;
SPI annotation = type.getAnnotation(SPI.class);
defaultNameCache = annotation.value();
}
获取默认扩展的代码就很简单了,直接使用了 defaultNameCache 去获取扩展。
public T getDefaultExtension() {
return getExtension(defaultNameCache);
}
3.1.5适配扩展
获取扩展类的时候,需要输入扩展名,这样就需要先从配置里面读到响应的扩展名,才能根据扩展名获取扩展类。这个过程稍显麻烦,参照dubbo 本rpc框架还提供了一种适配扩展,可以动态从 URL 中读取对应的配置并自动获取扩展类。
下面我们来看一下用法:
@SPI
public interface RegistryFactory {
/**
* 获取注册中心
*
* @param url 注册中心的配置,例如注册中心的地址。会自动根据协议获取注册中心实例
* @return 如果协议类型跟注册中心匹配上了,返回对应的配置中心实例
*/
@Adaptive("protocol")
Registry getRegistry(URL url);
}
下面我们来看一下用法:
@SPI
public interface RegistryFactory {
/**
* 获取注册中心
*
* @param url 注册中心的配置,例如注册中心的地址。会自动根据协议获取注册中心实例
* @return 如果协议类型跟注册中心匹配上了,返回对应的配置中心实例
*/
@Adaptive("protocol")
Registry getRegistry(URL url);
}
public static void main(String[] args) {
// 获取适配扩展
RegistryFactory zkRegistryFactory = ExtensionLoader.getLoader(RegistryFactory.class).getAdaptiveExtension();
URL url = URLParser.toURL("zk://localhost:2181");
// 适配扩展自动从 url 中解析出扩展名,然后返回对应的扩展类
Registry registry = zkRegistryFactory.getRegistry(url);
}
从示例代码,可以看到,有一个@Adaptive("protocol") 注解,方法中有 URL 参数。其逻辑就是,SPI 从传进来的 URL 的协议中字段中,获取到扩展名 zk。
获取适配扩展的代码是怎么是的呢?
public T getAdaptiveExtension() {
InvocationHandler handler = new AdaptiveInvocationHandler<T>(type);
return (T) Proxy.newProxyInstance(ExtensionLoader.class.getClassLoader(),
new Class<?>[]{type}, handler);
}
适配扩展类其实是一个代理类,接下来来看看这个代理类 AdaptiveInvocationHandler:
public class AdaptiveInvocationHandler<T> implements InvocationHandler {
private final Class<T> clazz;
public AdaptiveInvocationHandler(Class<T> tClass) {
clazz = tClass;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (args.length == 0) {
return method.invoke(proxy, args);
}
// 找 URL 参数
URL url = null;
for (Object arg : args) {
if (arg instanceof URL) {
url = (URL) arg;
break;
}
}
// 找不到 URL 参数,直接执行方法
if (url == null) {
return method.invoke(proxy, args);
}
Adaptive adaptive = method.getAnnotation(Adaptive.class);
// 如果不包含 @Adaptive,直接执行方法即可
if (adaptive == null) {
return method.invoke(proxy, args);
}
// 从 @Adaptive#value() 中拿到扩展名的 key
String extendNameKey = adaptive.value();
String extendName;
// 如果这个 key 是协议,从协议拿。其他的就直接从 URL 参数拿
if (URLKeyConst.PROTOCOL.equals(extendNameKey)) {
extendName = url.getProtocol();
} else {
extendName = url.getParam(extendNameKey, method.getDeclaringClass() + "." + method.getName());
}
// 拿到扩展名之后,就直接从 ExtensionLoader 拿就行了
ExtensionLoader<T> extensionLoader = ExtensionLoader.getLoader(clazz);
T extension = extensionLoader.getExtension(extendName);
return method.invoke(extension, args);
}
}
从配置中获取扩展的代码注释都有,我们在梳理一下流程:
-
从方法参数中拿到
URL参数,拿不到就直接执行方法 -
获取配置 Key。从
@Adaptive#value()拿扩展名的配置 key,如果拿不到就直接执行方法 -
获取扩展名。判断配置 key 是不是协议,如果是就拿协议类型,否则拿URL后面的参数。
例如URL是:
zk://localhost:2181?type=eureka- 如果
@Adaptive("protocol"),那么扩展名就是协议类型:zk - 如果
@Adaptive("type"),那么扩展名就是type参数:eureka
- 如果
-
最后根据扩展名获取扩展
extensionLoader.getExtension(extendName)
4.总结:
RPC 框架扩展很重要,SPI 是一个很好的机制。
JDK SPI 获取扩展的时候,会实例化所有的扩展,造成资源的浪费。
本rpc框架 自己实现了一套增强版的 SPI,有如下特点:
- 实现按名称加载
- 实现类单例缓存
- k-v配置文件格式
- 加载器缓存
- 默认扩展
- 适配扩展















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









