







上一篇文章介绍了 单机版本的Redis分布式锁有哪些问题并且Redisson是如何解决的
那如果Redis崩溃了呢?怎么提高可用性?
- Redis 的 Redlock 有什么问题?一定安全吗?
- 业界争论 Redlock,到底在争论什么?哪种观点是对的?
- 分布式锁到底用 Redis 还是 Zookeeper?
- 实现一个有「容错性」的分布式锁,都需要考虑哪些问题?
首先考虑主从集群及故障转移的情况
那当「主从发生切换」时,这个分布锁会依旧安全吗?
试想这样的场景:
- 客户端 1 在主库上执行 SET 命令,加锁成功
- 此时,主库异常宕机,SET 命令还未同步到从库上(主从复制是异步的)
- 从库被哨兵提升为新主库,这个锁在新的主库上,丢失了!

因此主从集群还是没办法导致容错,由于Redis的复制是异步的,锁的信息可能没有的同步到从节点,可能会使得互斥资源被多个线程共享。
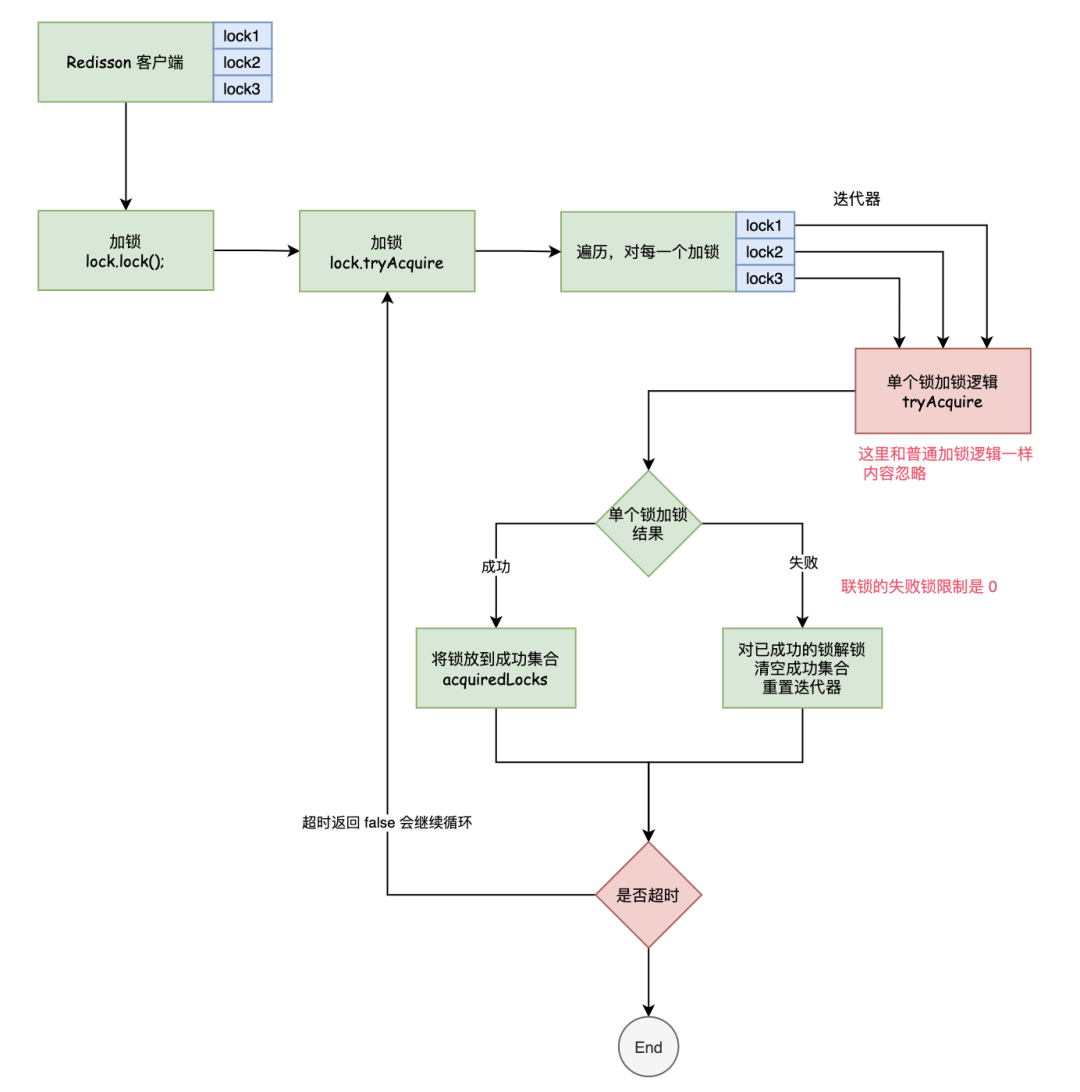
那么如果每台节点都当做主节点呢(MultiLock)?
假设五台Redis节点都当做主节点呢?
也就是要五台节点都加锁成功,才算加锁成功,这样就能够解决这个问题了。
一旦有一台加锁失败,则对所有节点执行释放锁的操作
但是考虑两种情况:
- 但是问题是如果一个节点挂掉了
- 线程1加了1-4号节点 线程2加了5号节点
以上两种情况分布式锁加锁失败了。
尤其是情况1,在一台节点的故障,就导致整个Redis分布式锁不可用了。
因此这个方案问题主要是分布式锁的可用性不高。
这个做法类似于2PC 会有单点故障导致的性能问题。
因此可以放松加锁节点的数量引入quoram机制

Redlock
为此,Redis 的作者提出一种解决方案,就是我们经常听到的 Redlock(红锁)。
它真的可以解决上面这个问题吗?
Redis 作者提出的 Redlock 方案,是如何解决主从切换后,锁失效问题的。
Redlock 的方案基于 2 个前提:
- 不再需要部署从库和哨兵实例,只部署主库
- 但主库要部署多个,官方推荐至少 5 个实例
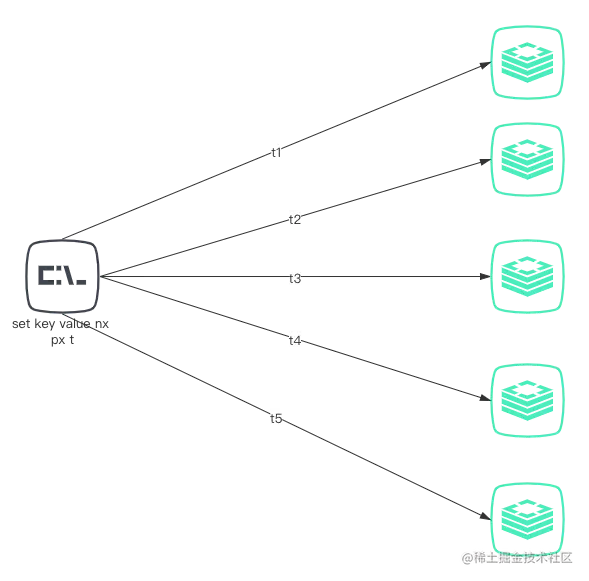
还是上述的5个Redis实例
Redlock 具体如何使用呢?
整体的流程是这样的,一共分为 5 步:
1.获取当前时间
2.按顺序尝试在5个Redis节点上获取锁,使用相同的key 作为键,随机数作为值(随机值在5个节点上是一样的)。在尝试在每个Redis节点上获取锁时,设置一个超时时间,这个超时时间需要比总的锁的自动超时时间小。例如,自动释放时间为10秒,那么连接超时的时间可以设置为5-50毫秒。这样可以防止客户端长时间与处于故障状态的Redis节点通信时保持阻塞状态:如果一个Redis节点处于故障状态,我们需要尽快与下一个节点进行通信。
3.客户端计算获取锁时消耗的时间,用当前时间,减去在第1步中得到的时间。只用当客户端可以在多数节点上能够获取到锁,并且获取锁消耗的总时间小于锁的有效时间,那么这个锁被认为是获取成功了。
4.如果锁获取成功了,锁的有效时间是初始的有效时间减掉申请锁消耗的总时间。
5.如果客户端申请锁失败了(例如不满足多数节点或第4步中获取到的锁有效期为负数),客户端需要在所有节点上解除锁(即使是认为已经无法提供服务的节点)。
还是以Redisson为例,简单看一下是如何实现的
/**
* RedLock locking algorithm implementation for multiple locks.
* It manages all locks as one.
*
* @see <a href="http://redis.io/topics/distlock">http://redis.io/topics/distlock</a>
*
* @author Nikita Koksharov
*
*/
public class RedissonRedLock extends RedissonMultiLock {
/**
* Creates instance with multiple {@link RLock} objects.
* Each RLock object could be created by own Redisson instance.
*
* @param locks - array of locks
*/
public RedissonRedLock(RLock... locks) {
super(locks);
}
@Override
protected int failedLocksLimit() {
return locks.size() - minLocksAmount(locks);
}
protected int minLocksAmount(final List<RLock> locks) {
return locks.size()/2 + 1;
}
@Override
protected long calcLockWaitTime(long remainTime) {
return Math.max(remainTime / locks.size(), 1);
}
@Override
public void unlock() {
unlockInner(locks);
}
}
RedissonRedLock完全的按照上文我们介绍的Redlock的算法来实现的,通过在三个不同节点上分别获取锁,来构造一个Redlock,我们再来分析一下具体的tryLock的实现,这个方法是在RedissonRedLock的父类RedissonMultiLock实现的:
`/**
*
* @param waitTime the maximum time to acquire the lock
* @param leaseTime lease time
* @param unit time unit
* @return
* @throws InterruptedException
*/
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long newLeaseTime = -1;
if (leaseTime != -1) {
if (waitTime == -1) {
newLeaseTime = unit.toMillis(leaseTime);
} else {
//等待时间和加锁时间都不为-1时,newLeaseTime为waitTime时间的两倍
newLeaseTime = unit.toMillis(waitTime)*2;
}
}
long time = System.currentTimeMillis();
long remainTime = -1;
if (waitTime != -1) {
remainTime = unit.toMillis(waitTime);
}
//子类重写的方法,Math.max(remainTime / locks.size(), 1),waitTime除以节点的个数,与1取较大值
//Math.max(等待时间的毫秒数/节点个数,1)
long lockWaitTime = calcLockWaitTime(remainTime);
//调用子类重写方法,locks.size() - minLocksAmount(locks)
//minLocksAmount(locks) => locks.size()/2 + 1
//failedLocksLimit = 锁的个数 -(锁的个数/2 + 1)
//即为Redis节点个数的少数(N/2-1),获取锁允许失败个数的最大阀值为N/2-1,超过这个值,就认定Redlock加锁失败
int failedLocksLimit = failedLocksLimit();
List<RLock> acquiredLocks = new ArrayList<>(locks.size());
for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {
RLock lock = iterator.next();
boolean lockAcquired;
try {
if (waitTime == -1 && leaseTime == -1) {
lockAcquired = lock.tryLock();
} else {
//加锁尝试的等待时间为:等待时长的毫秒数 与 Math.max(等待时长的毫秒数/节点个数,1)之间的较小值
long awaitTime = Math.min(lockWaitTime, remainTime);
//挨个尝试加锁,锁的有效期为等待时长的2倍
lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);
}
} catch (RedisResponseTimeoutException e) {
//申请锁超时就尝试解锁
unlockInner(Arrays.asList(lock));
lockAcquired = false;
} catch (Exception e) {
lockAcquired = false;
}
if (lockAcquired) {
//加锁成功的节点就放到acquiredLocks这个list中
acquiredLocks.add(lock);
} else {
//加锁失败,需要判断失败的个数是否已经达到了N/2-1个,达到了的话,再来一个失败的,那么这个
//redlock就加锁失败了,后面的就可以不用再试了
if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {
break;
}
if (failedLocksLimit == 0) {
unlockInner(acquiredLocks);
if (waitTime == -1) {
return false;
}
failedLocksLimit = failedLocksLimit();
acquiredLocks.clear();
// reset iterator
while (iterator.hasPrevious()) {
iterator.previous();
}
} else {
failedLocksLimit--;
}
}
if (remainTime != -1) {
remainTime -= System.currentTimeMillis() - time;
time = System.currentTimeMillis();
if (remainTime <= 0) {
unlockInner(acquiredLocks);
return false;
}
}
}
//redLock申请成功,为每个节点上的锁设置过期时间
if (leaseTime != -1) {
List<RFuture<Boolean>> futures = new ArrayList<>(acquiredLocks.size());
for (RLock rLock : acquiredLocks) {
RFuture<Boolean> future = ((RedissonLock) rLock).expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS);
futures.add(future);
}
for (RFuture<Boolean> rFuture : futures) {
rFuture.syncUninterruptibly();
}
}
return true;
}
接下来再看一下解锁:
protected RFuture<Void> unlockInnerAsync(Collection<RLock> locks, long threadId) {
if (locks.isEmpty()) {
return RedissonPromise.newSucceededFuture(null);
}
RPromise<Void> result = new RedissonPromise<Void>();
AtomicInteger counter = new AtomicInteger(locks.size());
for (RLock lock : locks) {
lock.unlockAsync(threadId).onComplete((res, e) -> {
if (e != null) {
result.tryFailure(e);
return;
}
//在所有Redis节点上都完成解锁动作后
if (counter.decrementAndGet() == 0) {
result.trySuccess(null);
}
});
}
return result;
}
1) 为什么要在多个实例上加锁?
本质上是为了「容错」,部分实例异常宕机,剩余的实例加锁成功,整个锁服务依旧可用。
2) 为什么大多数加锁成功,才算成功?
多个 Redis 实例一起来用,其实就组成了一个「分布式系统」。
在分布式系统中,总会出现「异常节点」,所以,在谈论分布式系统问题时,需要考虑异常节点达到多少个,也依旧不会影响整个系统的「正确性」。
这是一个分布式系统「容错」问题,这个问题的结论是:如果只存在「故障」节点,只要大多数节点正常,那么整个系统依旧是可以提供正确服务的。
这个问题的模型,就是我们经常听到的「拜占庭将军」问题,感兴趣可以去看算法的推演过程。
3) 为什么步骤 3 加锁成功后,还要计算加锁的累计耗时?
因为操作的是多个节点,所以耗时肯定会比操作单个实例耗时更久,而且,因为是网络请求,网络情况是复杂的,有可能存在延迟、丢包、超时等情况发生,网络请求越多,异常发生的概率就越大。
所以,即使大多数节点加锁成功,但如果加锁的累计耗时已经「超过」了锁的过期时间,那此时有些实例上的锁可能已经失效了,这个锁就没有意义了。
4) 为什么释放锁,要操作所有节点?
在某一个 Redis 节点加锁时,可能因为「网络原因」导致加锁失败。
例如,客户端在一个 Redis 实例上加锁成功,但在读取响应结果时,网络问题导致读取失败,那这把锁其实已经在 Redis 上加锁成功了。
所以,释放锁时,不管之前有没有加锁成功,需要释放「所有节点」的锁,以保证清理节点上「残留」的锁。
好了,明白了 Redlock 的流程和相关问题,看似 Redlock 确实解决了 Redis 节点异常宕机锁失效的问题,保证了锁的「安全性」。
但事实真的如此吗?
关于Redlock 的争论谁对谁错?
DDIA的坐者Martin Kleppmann批判Redlock的文章
前半部分讲述分布式锁的目的以及完美模型,后半部分对RedLock进行了批判
1) 分布式锁的目的是什么?
Martin 表示,你必须先清楚你在使用分布式锁的目的是什么?
他认为有两个目的。
第一,效率。
使用分布式锁的互斥能力,是避免不必要地做同样的两次工作(例如一些昂贵的计算任务)。如果锁失效,并不会带来「恶性」的后果,例如发了 2 次邮件等,无伤大雅。
第二,正确性。
使用锁用来防止并发进程互相干扰。如果锁失效,会造成多个进程同时操作同一条数据,产生的后果是数据严重错误、永久性不一致、数据丢失等恶性问题,就像给患者服用重复剂量的药物一样,后果严重。
他认为,如果你是为了前者——效率,那么使用单机版 Redis 就可以了,即使偶尔发生锁失效(宕机、主从切换),都不会产生严重的后果。而使用 Redlock 太重了,没必要。
而如果是为了正确性,Martin 认为 Redlock 根本达不到安全性的要求,也依旧存在锁失效的问题!
2) 锁在分布式系统中会遇到的问题
Martin 表示,一个分布式系统,更像一个复杂的「野兽」,存在着你想不到的各种异常情况。
这些异常场景主要包括三大块,这也是分布式系统会遇到的三座大山:NPC。
- N:NetWork Delay网络延迟
- P:Process Pause 进程暂停(GC)
- C:Clock Drift 时钟漂移
Martin 用一个进程暂停(GC)的例子,指出了 Redlock 安全性问题:
- 客户端 1 请求锁定节点 A、B、C、D、E
- 客户端 1 的拿到锁后,进入 GC(时间比较久)
- 所有 Redis 节点上的锁都过期了
- 客户端 2 获取到了 A、B、C、D、E 上的锁
- 客户端 1 GC 结束,认为成功获取锁
- 客户端 2 也认为获取到了锁,发生「冲突」
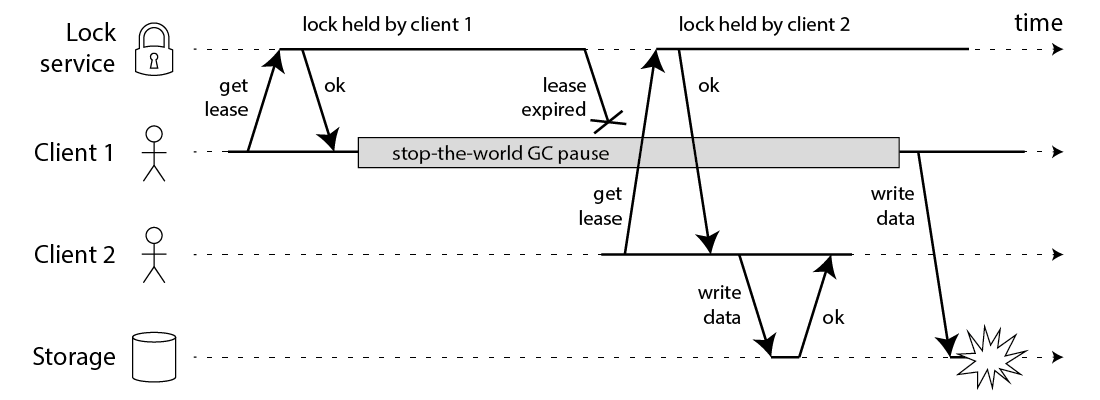
Martin 认为,GC 可能发生在程序的任意时刻,而且执行时间是不可控的。
注:当然,即使是使用没有 GC 的编程语言,在发生网络延迟、时钟漂移时,也都有可能导致 Redlock 出现问题,这里 Martin 只是拿 GC 举例。
3) 假设时钟正确的是不合理的
又或者,当多个 Redis 节点**「时钟」**发生问题时,也会导致 Redlock 锁失效。
- 客户端 1 获取节点 A、B、C 上的锁,但由于网络问题,无法访问 D 和 E
- 节点 C 上的时钟「向前跳跃」,导致锁到期
- 客户端 2 获取节点 C、D、E 上的锁,由于网络问题,无法访问 A 和 B
- 客户端 1 和 2 现在都相信它们持有了锁(冲突)
Martin 觉得,Redlock 必须「强依赖」多个节点的时钟是保持同步的,一旦有节点时钟发生错误,那这个算法模型就失效了。
即使 C 不是时钟跳跃,而是「崩溃后立即重启」,也会发生类似的问题。
Martin 继续阐述,机器的时钟发生错误,是很有可能发生的:
- 系统管理员「手动修改」了机器时钟
- 机器时钟在同步 NTP 时间时,发生了大的「跳跃」
总之,Martin 认为,Redlock 的算法是建立在「同步模型」基础上的,有大量资料研究表明,同步模型的假设,在分布式系统中是有问题的。
在混乱的分布式系统的中,你不能假设系统时钟就是对的,所以,你必须非常小心你的假设。
4) 提出 fencing token 的方案,保证正确性
相对应的,Martin 提出一种被叫作 fencing token 的方案,保证分布式锁的正确性。
这个模型流程如下:
- 客户端在获取锁时,锁服务可以提供一个「递增」的 token
- 客户端拿着这个 token 去操作共享资源
- 共享资源可以根据 token 拒绝「后来者」的请求

例如上图当客户端1发生gc,锁被客户端2抢到并发生写入(token34)的时候,客户端1gc结束再写(token33)就被拒绝了。
在讨论中,有人提出客户端1和客户端2都发生了GC pause,两个fencing token都延迟了,它们几乎同时到达了文件服务器,而且保持了顺序。那么,我们新加入的判断逻辑,即判断fencing token的合理性,应该对两个请求都会放过,而放过之后它们几乎同时在操作文件,还是冲突了。(这种情况过于极端了)
而 Redlock 无法提供类似 fencing token 的方案,所以它无法保证安全性。
他还表示,一个好的分布式锁,无论 NPC 怎么发生,可以不在规定时间内给出结果,但并不会给出一个错误的结果。也就是只会影响到锁的「性能」(或称之为活性),而不会影响它的「正确性」。
Martin 的结论:
1、Redlock 不伦不类:它对于效率来讲,Redlock 比较重,没必要这么做,而对于正确性来说,Redlock 是不够安全的。
2、时钟假设不合理:该算法对系统时钟做出了危险的假设(假设多个节点机器时钟都是一致的),如果不满足这些假设,锁就会失效。
3、无法保证正确性:Redlock 不能提供类似 fencing token 的方案,所以解决不了正确性的问题。为了正确性,请使用有「共识系统」的软件,例如 Zookeeper。
Redis 作者 Antirez 的反驳
在 Redis 作者的文章中,重点有 3 个:
1) 解释时钟问题
首先,Redis 作者一眼就看穿了对方提出的最为核心的问题:时钟问题。
Redis 作者表示,Redlock 并不需要完全一致的时钟,只需要大体一致就可以了,允许有「误差」。
例如要计时 5s,但实际可能记了 4.5s,之后又记了 5.5s,有一定误差,但只要不超过「误差范围」锁失效时间即可,这种对于时钟的精度的要求并不是很高,而且这也符合现实环境。
对于对方提到的「时钟修改」问题,Redis 作者反驳到:
- 手动修改时钟:不要这么做就好了,否则你直接修改 Raft 日志,那 Raft 也会无法工作…
- 时钟跳跃:通过「恰当的运维」,保证机器时钟不会大幅度跳跃(每次通过微小的调整来完成),实际上这是可以做到的
为什么 Redis 作者优先解释时钟问题?因为在后面的反驳过程中,需要依赖这个基础做进一步解释。
2) 解释网络延迟、GC 问题
之后,Redis 作者对于对方提出的,网络延迟wan、进程 GC 可能导致 Redlock 失效的问题,也做了反驳:
我们重新回顾一下,Martin 提出的问题假设:
- 客户端 1 请求锁定节点 A、B、C、D、E
- 客户端 1 的拿到锁后,进入 GC
- 所有 Redis 节点上的锁都过期了
- 客户端 2 获取节点 A、B、C、D、E 上的锁
- 客户端 1 GC 结束,认为成功获取锁
- 客户端 2 也认为获取到锁,发生「冲突」
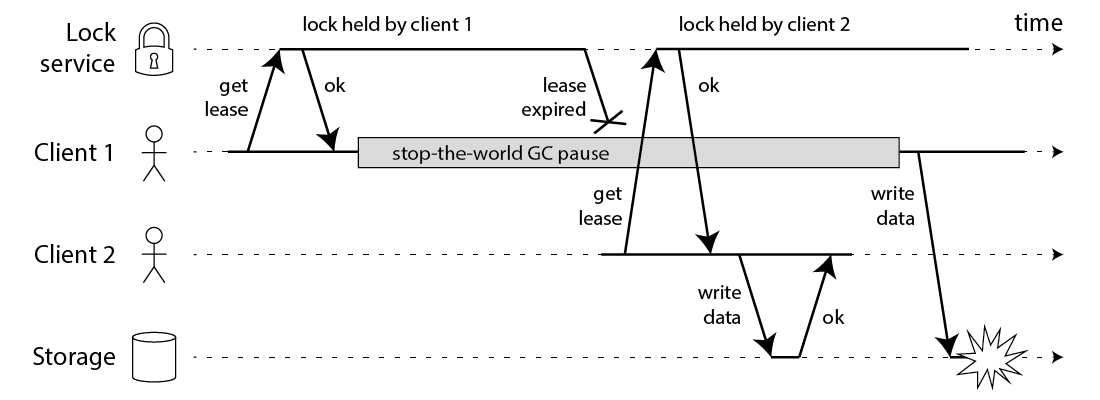
Redis 作者反驳到,这个假设其实是有问题的,Redlock 是可以保证锁安全的。
这是怎么回事呢?
还记得前面介绍 Redlock 流程的那 5 步吗?这里我再拿过来让你复习一下。
- 客户端先获取「当前时间戳T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 如果客户端从 3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
- 加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
- 加锁失败,向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
注意,重点是 1-3,在步骤 3,加锁成功后为什么要重新获取「当前时间戳T2」?还用 T2 - T1 的时间,与锁的过期时间做比较?
Redis 作者强调:如果在 1-3 发生了网络延迟、进程 GC 等耗时长的异常情况,那在第 3 步 T2 - T1,是可以检测出来的,如果超出了锁设置的过期时间,那这时就认为加锁会失败,之后释放所有节点的锁就好了!
Redis 作者继续论述,如果对方认为,发生网络延迟、进程 GC 是在步骤 3 之后,也就是客户端确认拿到了锁,去操作共享资源的途中发生了问题,导致锁失效,那这不止是 Redlock 的问题,任何其它锁服务例如 Zookeeper,都有类似的问题,这不在讨论范畴内。
这里我举个例子解释一下这个问题:
- 客户端通过 Redlock 成功获取到锁(通过了大多数节点加锁成功、加锁耗时检查逻辑)
- 客户端开始操作共享资源,此时发生网络延迟、进程 GC 等耗时很长的情况
- 此时,锁过期自动释放
- 客户端开始操作 MySQL(此时的锁可能会被别人拿到,锁失效)
Redis 作者这里的结论就是:
- 客户端在拿到锁之前,无论经历什么耗时长问题,Redlock 都能够在第 3 步检测出来
- 客户端在拿到锁之后,发生 NPC,那 Redlock、Zookeeper 都无能为力
所以,Redis 作者认为 Redlock 在保证时钟正确的基础上,是可以保证正确性的。
3) 质疑 fencing token 机制
Redis 作者对于对方提出的 fencing token 机制,也提出了质疑,主要分为 2 个问题,这里最不宜理解,请跟紧我的思路。
第一,这个方案必须要求要操作的「共享资源服务器」有拒绝「旧 token」的能力。
例如,要操作 MySQL,从锁服务拿到一个递增数字的 token,然后客户端要带着这个 token 去改 MySQL 的某一行,这就需要利用 MySQL 的「事物隔离性」来做。
// 两个客户端必须利用事物和隔离性达到目的
// 注意 token 的判断条件
UPDATE table T SET val = $new_val, current_token = $token WHERE id = $id AND current_token < $token
但如果操作的不是 MySQL 呢?例如向磁盘上写一个文件,或发起一个 HTTP 请求,那这个方案就无能为力了,这对要操作的资源服务器,提出了更高的要求。
也就是说,大部分要操作的资源服务器,都是没有这种互斥能力的。
再者,既然资源服务器都有了「互斥」能力,那还要分布式锁干什么?
所以,Redis 作者认为这个方案是站不住脚的。
第二,退一步讲,即使 Redlock 没有提供 fencing token 的能力,但 Redlock 已经提供了随机值(就是前面讲的 UUID),利用这个随机值,也可以达到与 fencing token 同样的效果。
如何做呢?
- 客户端使用 Redlock 拿到锁
- 客户端在操作共享资源之前,先把这个锁的 VALUE,在要操作的共享资源上做标记
- 客户端处理业务逻辑,最后,在修改共享资源时,判断这个标记是否与之前一样,一样才修改(类似 CAS 的思路)
UPDATE table T SET val = $new_val WHERE id = $id AND current_token = $redlock_value
可见,这种方案依赖 MySQL 的事物机制,也达到对方提到的 fencing token 一样的效果。
但这里还有个小问题,是网友参与问题讨论时提出的:两个客户端通过这种方案,先「标记」再「检查+修改」共享资源,那这两个客户端的操作顺序无法保证啊?
而用 Martin 提到的 fencing token,因为这个 token 是单调递增的数字,资源服务器可以拒绝小的 token 请求,保证了操作的「顺序性」!
Redis 作者对于这个问题做了不同的解释,我觉得很有道理,他解释道:分布式锁的本质,是为了「互斥」,只要能保证两个客户端在并发时,一个成功,一个失败就好了,不需要关心「顺序性」。
综上,Redis 作者的结论:
1、作者同意对方关于「时钟跳跃」对 Redlock 的影响,但认为时钟跳跃是可以避免的,取决于基础设施和运维。
2、Redlock 在设计时,充分考虑了 NPC 问题,在 Redlock 步骤 3 之前出现 NPC,可以保证锁的正确性,但在步骤 3 之后发生 NPC,不止是 Redlock 有问题,其它分布式锁服务同样也有问题,所以不在讨论范畴内。
Martin 在他的文章中,推荐使用 Zookeeper 实现分布式锁,认为它更安全,确实如此吗?
Zookeeper实现分布式锁呢?
Flavio Junqueira是ZooKeeper的作者之一,他的这篇blog就写在Martin和antirez发生争论的那几天。他在文中给出了一个基于ZooKeeper构建分布式锁的描述(当然这不是唯一的方式):
- 客户端尝试创建一个znode节点,比如
/lock。那么第一个客户端就创建成功了,相当于拿到了锁;而其它的客户端会创建失败(znode已存在),获取锁失败。 - 持有锁的客户端访问共享资源完成后,将znode删掉,这样其它客户端接下来就能来获取锁了。
- znode应该被创建成ephemeral的。这是znode的一个特性,它保证如果创建znode的那个客户端崩溃了,那么相应的znode会被自动删除。这保证了锁一定会被释放。
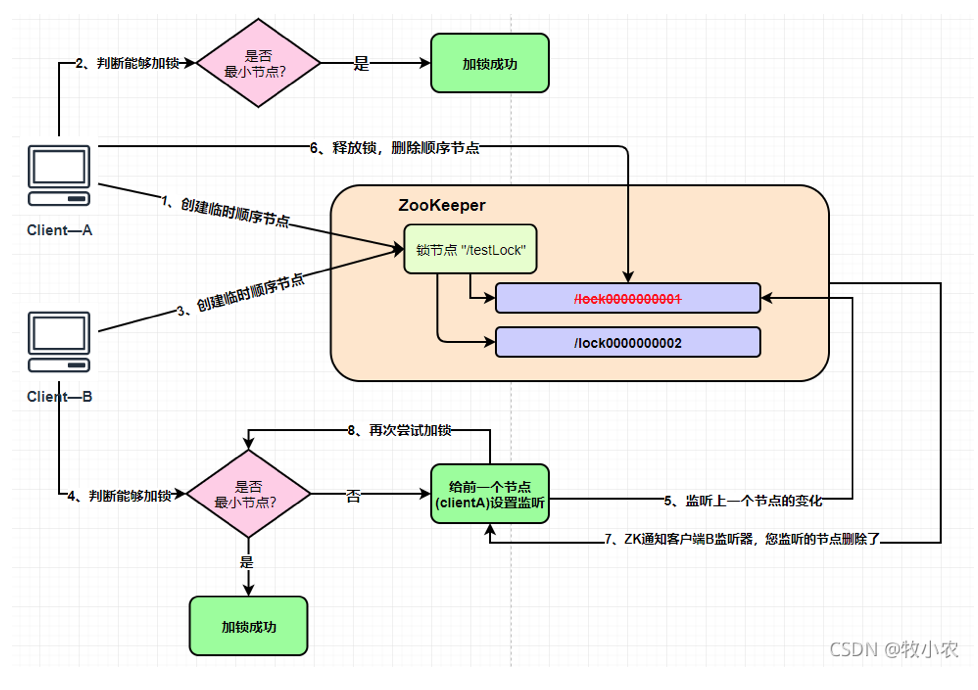
使用代码实现一下,zk实现分布式锁:
实现Lock接口,重写lock()方法,tryLock()方法,unLock()核心方法,作为分布式锁的加锁、解锁方法
使用apache.ZooKeeper原生客户端api操作Zookeeper
在zk的"/LOCK"节点下创建"zk_"开头的临时顺序节点,通过节点序号大小判断自己能否获得锁
使用ThreadLocal存储节点的名称,保证线程安全。其中存储了节点自己的名字,作为判断自己是否最小节点的依据
如果没有获取到锁,则使用Watcher监控自己的前一个节点。因为Watcher是异步操作,使用CountDownLatch进行阻塞,当前一个节点被删除时才被唤醒
public class ZkLock implements Lock {
//存储zk客户端
private ThreadLocal<ZooKeeper> zk = new ThreadLocal<>();
private String LOCK_NAME="/LOCK";
//存储节点自己的名字
private ThreadLocal<String> CURRENT_NODE = new ThreadLocal<>();
public void init(){
if (zk.get()==null){
try {
zk.set(new ZooKeeper("localhost:2181", 300, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("watch event");
}
}));
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void lock(){
init();
if(tryLock()){
System.out.println(Thread.currentThread().getName()+"已经获取到锁了");
}
}
public boolean tryLock(){
//前缀
String nodeName=LOCK_NAME+"/zk_";
try {
//临时顺序节点
CURRENT_NODE.set( zk.get().create(nodeName, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL));
List<String> list = zk.get().getChildren(LOCK_NAME, false);
//排序
Collections.sort(list);
String minNodeName = list.get(0);
//如果当前自己是最小的节点 获取到锁
if (CURRENT_NODE.get().equals(LOCK_NAME+"/"+minNodeName)){
return true;
}else{
//没获取到锁,就监听前一个节点
String currentNodeSimpleName=CURRENT_NODE.get().substring(CURRENT_NODE.get().lastIndexOf("/") + 1);
int currentNodeIndex= list.indexOf(currentNodeSimpleName);
String preNodeSimpleName = list.get(currentNodeIndex - 1);
System.out.println(Thread.currentThread().getName()+"-监听节点:"+preNodeSimpleName);
CountDownLatch countDownLatch = new CountDownLatch(1);
zk.get().exists(LOCK_NAME + "/" + preNodeSimpleName, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (Event.EventType.NodeDeleted.equals(event.getType())){
countDownLatch.countDown();
System.out.println(Thread.currentThread().getName()+"被唤醒");
}
}
});
System.out.println(Thread.currentThread().getName()+"阻塞住");
countDownLatch.await();
return true;
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return false;
}
public void unlock(){
try {
//-1表示忽略版本号,强制删除
zk.get().delete(CURRENT_NODE.get(),-1);
System.out.println(Thread.currentThread().getName()+"-删除节点");
CURRENT_NODE.set(null);
zk.get().close();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return false;
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public Condition newCondition() {
return null;
}
}
看起来这个锁相当完美,没有Redlock过期时间的问题,而且能在需要的时候让锁自动释放。但仔细考察的话,并不尽然。
ZooKeeper是怎么检测出某个客户端已经崩溃了呢?实际上,每个客户端都与ZooKeeper的某台服务器维护着一个Session,这个Session依赖定期的**心跳(heartbeat)**来维持。如果ZooKeeper长时间收不到客户端的心跳(这个时间称为Sesion的过期时间),那么它就认为Session过期了,通过这个Session所创建的所有的ephemeral类型的znode节点都会被自动删除。
设想如下的执行序列:
- 客户端1创建了znode节点
/lock,获得了锁。 - 客户端1进入了长时间的GC pause。
- 客户端1连接到ZooKeeper的Session过期了。znode节点
/lock被自动删除。 - 客户端2创建了znode节点
/lock,从而获得了锁。 - 客户端1从GC pause中恢复过来,它仍然认为自己持有锁。
最后,客户端1和客户端2都认为自己持有了锁,冲突了。这与之前Martin在文章中描述的由于GC pause导致的分布式锁失效的情况类似。
看起来,用ZooKeeper实现的分布式锁也不一定就是安全的。该有的问题它还是有。但是,ZooKeeper作为一个专门为分布式应用提供方案的框架,它提供了一些非常好的特性,是Redis之类的方案所没有的。像前面提到的ephemeral类型的znode自动删除的功能就是一个例子。
还有一个很有用的特性是ZooKeeper的watch机制。这个机制可以这样来使用,比如当客户端试图创建/lock的时候,发现它已经存在了,这时候创建失败,但客户端不一定就此对外宣告获取锁失败。客户端可以进入一种等待状态,等待当/lock节点被删除的时候,ZooKeeper通过watch机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。这样的特性Redlock就无法实现。
小结一下,基于ZooKeeper的锁和基于Redis的锁(主从和RedLock)相比在实现特性上有三个不同:
- 对于锁资源占用时长。在正常情况下,客户端可以持有锁任意长的时间,这可以确保它做完所有需要的资源访问操作之后再释放锁。这避免了基于Redis的锁对于有效时间(lock validity time)到底设置多长的两难问题。实际上,基于ZooKeeper的锁是依靠Session(心跳)来维持锁的持有状态的,而Redis不支持Session。
- 锁的灵活度:基于ZooKeeper的锁支持在获取锁失败之后等待锁重新释放的事件。这让客户端对锁的使用更加灵活。
- 主从模式更安全:Zookeeper利用ZAB协议能解决主从情况下,因为主从切换导致加锁情况没有同步,而使得两个线程同时进入的情况;
- 与RedLock对比 NPC问题:可以解决对于时钟依赖的困境,毕竟依赖于Session心跳去释放锁,而不需要像RedLock.也就是GC导致心跳响应不及时导致的锁错误释放的情况依旧没办法解决
总结
1) 到底要不要用 Redlock?
前面也分析了,Redlock 只有建立在「时钟正确」的前提下,才能正常工作,如果你可以保证这个前提,那么可以拿来使用。
但保证时钟正确,我认为并不是你想的那么简单就能做到的。
所以,我对 Redlock 的个人看法是,尽量不用它,而且它的性能不如单机版 Redis,部署成本也高,我还是会优先考虑使用 Redis「主从+哨兵」的模式,实现分布式锁。而且Redisson的RedLock使用起来还需要自己去分配key散落的节点,非常复杂,当前已经被Redisson启用了,可见其部署成本之高。
那正确性如何保证呢?第二点给你答案。
2) 如何正确使用分布式锁?
在分析 Martin 观点时,它提到了 fencing token 的方案,给我了很大的启发,虽然这种方案有很大的局限性,但对于保证「正确性」的场景,是一个非常好的思路。
所以,我们可以把这两者结合起来用:
1、使用分布式锁,在上层完成「互斥」目的,虽然极端情况下锁会失效,但它可以最大程度把并发请求阻挡在最上层,减轻操作资源层的压力。
2、但对于要求数据绝对正确的业务,在资源层一定要做好「兜底」,设计思路可以借鉴 fencing token 的方案来做。
两种思路结合,我认为对于大多数业务场景,已经可以满足要求了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









