







1.概况
截至目前,Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0。前者主要有如下几种实现方式:1)社区版本基于Secondary namenode机制来定时备份HDFS metadata元数据信息;2)Avatar在Secondarynamenode的基础上实现了基于NFS共享存储方式的热备方案。3)Backup Node通过提供备用节点同步Namenode中的Matadata数据实现。后者基于NFS或者Journalnode实现HA同步两个namenode节点之间的数据。
2.各版本实现原理:
2.1 Hadoop1.0之社区版
Hadoop1.0的社区版是通过Secondary Namenode通过辅助Namenode进行镜像文件和日志文件的定期合并实现的。Namenode中有两个很重要的文件:(1)fsimage:元数据镜像文件(保存文件系统的目录树)(2)edits:元数据操作日志(针对目录树的修改操作)。首先必须明确Secondary NameNode并非NameNode的热备,只是辅助NameNode,分担其工作量,在紧急情况下,可辅助恢复NameNode。
SecondaryNameNode有两个作用,一是镜像备份,二是日志与镜像的定期合并。两个过程同时进行,称为checkpoint。前者主要将NameNode的元数据进行备份,防止丢失;后者将NameNode中edits日志和fsimage合并,并推送给NameNode,防止因日志文件过大导致NameNode重启速度慢。原理图如下:
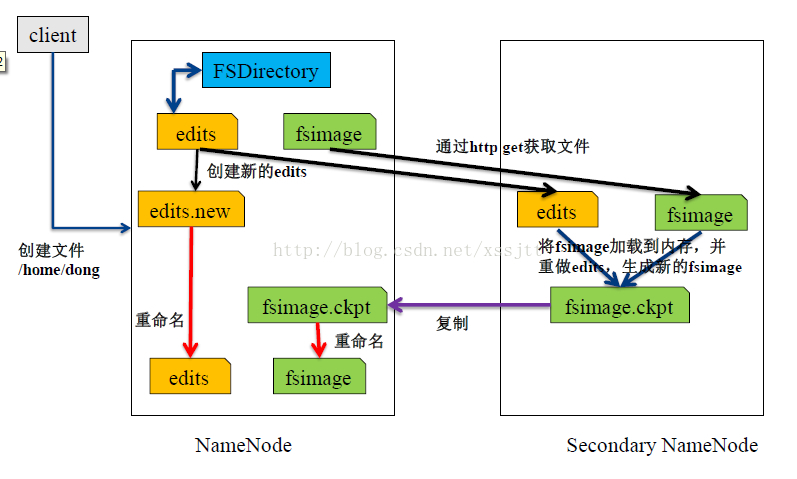
缺陷分析:有图中可以看出,Secondary NameNode并不是NameNode的热备,而只是每次checkpoint的时候才合并NameNode中的fsimage和edits,备份并推送给NameNode。Secondarynamenode的备份数据并不能时刻保持与namenode同步,也就是说在namenode宕机的时候secondarynamenode可能会丢失一段时间的数据,这段时间取决于checkpoint的周期。当然可以通过减小checkpoint的周期来减少数据的丢失量,但由于每次checkpoint很耗性能,而且这种方案也不能从根本上解决数据丢失的问题。当NameNode节点宕机时,Secondary NameNode不能自动切换为NameNode参与集群的调度,此时集群处于崩溃状态,正是基于此,为了解决NameNode的单点故障,催生了一些解决方案,如backup Node和AvatarNode就是其中之二。
2.2 Hadoop1.0之Avatar方案
Facebook的AvatarNode是业界较早的Namenode HA方案,它是基于HDFS 0.20实现的。由于采用的是人工切换,所以实现相对简单。AvatarNode对Namenode进行了封装,处于工作状态的叫 Primary Avatar,处于热备状态的叫Standby Avatar(封装了Namenode和SecondaryNameNode),两者通过NFS共享EditLog所在目录。在工作状态下,Primary Avatar中的Namenode实例接收Client的请求并进行处理,Datanode会向Primary和Standby两个同时发送 blockReport和心跳,Standby Avatar不断地从共享的EditLog中持续写入的新事务,并推送给它的Namenode实例,此时Standby Avatar内部的Namenode处于安全模式状态,不对外提供服务,但是状态与Primary Avatar中的保持一致。一旦Primary发生故障,管理员进行Failover切换:首先将原来的Primary进程杀死(避免了“Split Brain/脑裂”和“IO Fencing/IO隔离”问题),然后将原来的Standby设置为Primary,新的Primary会保证完成所有的EditLog事务,然后退出安全模式,对外接收服务请求。为了实现对客户端透明,AvatarNode主从采用相同的虚拟IP,切换时将新的Primary设置为该虚拟IP即可。整个流程可在秒~分钟级别完成。
缺陷分析: Avatar存在转换限制,只能由Standby转换成Primary,故一次故障后,由Standby上升为Primary的节点并不能重新降级为Standby,故不能实现像Master/Slave那种自由切换。
2.3 Hadoop1.0之Backup Node方案
利用新版本Hadoop自身的Failover措施,配置一个Backup Node,Backup Node在内存和本地磁盘均保存了HDFS系统最新的名字空间元数据信息。如果NameNode发生故障,可用使用Backup Node中最新的元数据信息。Backup Node的内存中对当前最新元数据信息进行了备份(Namespace),避免了通过NFS挂载进行备份所带来的风险。Backup Node可以直接利用内存中的元数据信息进行Checkpoint,保存到本地,与从NameNode下载元数据进行Checkpoint的方式相比效率更高。
NameNode 会将元数据操作的日志记录同步到Backup Node,Backup Node会将收到的日志记录在内存中更新元数据状态,同时更新磁盘上的edits,只有当两者操作成功,整个操作才成功。这样即便NameNode上的元数据发生损坏,Backup Node的磁盘上也保存了HDFS最新的元数据,从而保证了一致性。
缺陷分析:当NameNode无法工作时,Backup Node目前还无法直接接替NameNode提供服务,因此当前版本的Backup Node还不具有热备功能,也就是说,当NameNode发生故障,目前还只能通过重启NameNode的方式来恢复服务。Backup Node的内存中未保存Block的位置信息,仍然需要等待下面的DataNode进行上报,因此,即便在后续的版本中实现了热备,仍然需要一定的切换时间。当前版本只允许1个Backup Node连接到NameNode。
2.4 Hadoop2.0
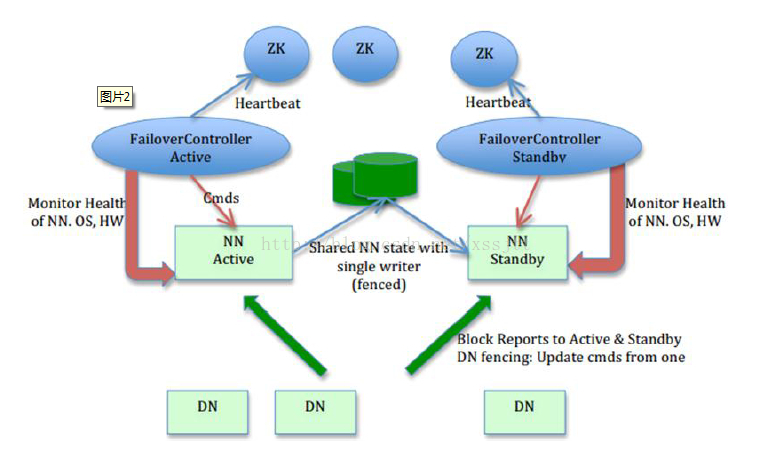
在HDFS(HA)集群中,使用两台单独的机器配置为NameNode。在任何时间点,确保NameNode中只有一个处于Active状态,另一个处在Standby状态。其中Active NameNode负责集群中的所有客户端操作,StandbyNameNode仅仅充当热备的作用,保证一旦ActiveNameNode出现问题能够快速切换。而Namenode的快速切换是以ZKFC机制实现的,每台NameNode所在的节点上均存在ZKFC进程,该进程会通过心跳通信检测NameNode状态是否发生变化,如若发生变化,会根据Zookeeper集群中的状态信息自动进行切换。目前hadoop支持2种hdfs ha的实现方式,分别为:journalnode和NFS,NameNode自动切换的原理图如下所示:
2.2.1 Journalnode的方式实现HA的原理图如下:
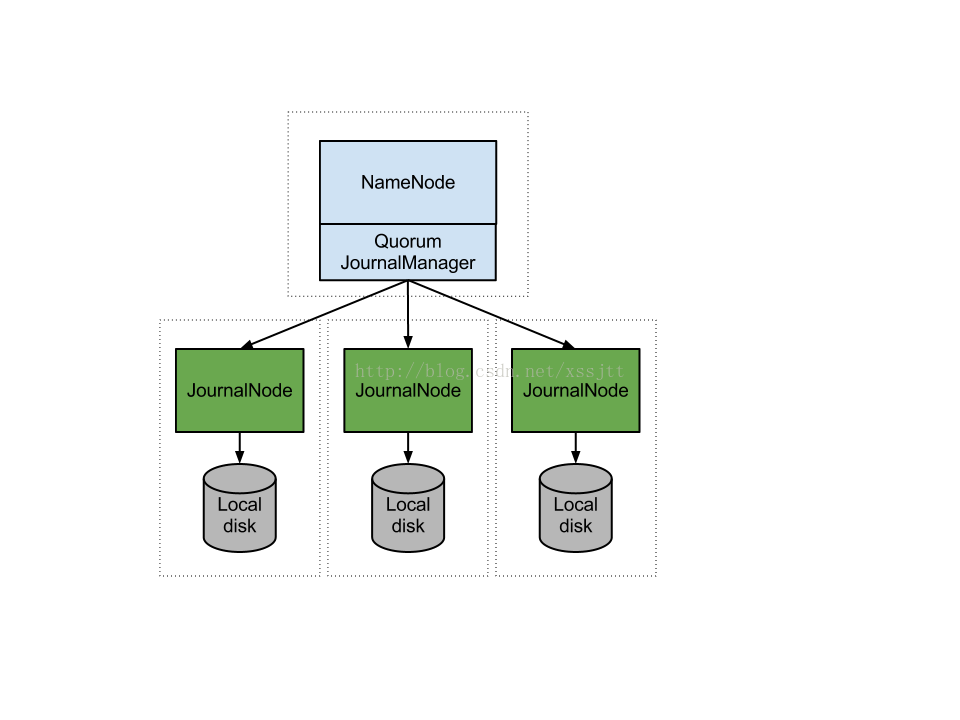
原理简介:JournalNode集群以Local disk作为存储介质,保存Active NN和Standby NN的共享元数据信息,由QJM(QuorumJournalManager)统一调度维护Journalnode集群,Active NN把EditLog写到journalNode集群中,Standby NN去读取日志然后执行,这样Active和Standby NN内存中的HDFS元数据保持着同步。一旦发生主从切换Standby NN可以尽快接管Active NN的工作。
2.2.2 NFS方式实现HA:
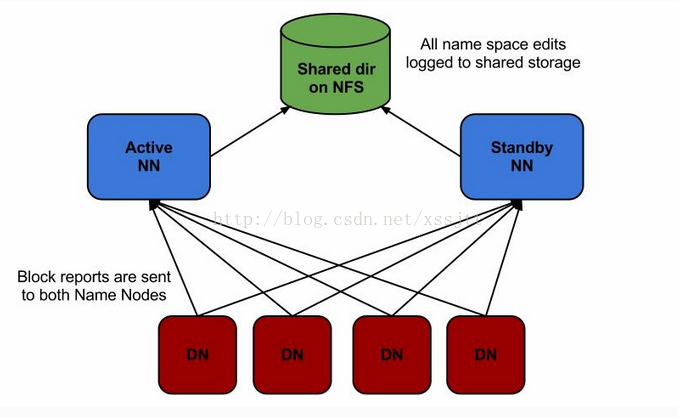
原理:NFS的方式的HA的配置与启动,和QJM方式基本上是一样,唯一不同的地方就是active namenode和standby namenode共享edits文件的方式,QJM方式是采用journalnode来共享edits文件,而NFS方式则是采用NFS远程共享目录来共享edits文件,原理图如下所示:















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









