







一、.决策树原理
def CreatTree(dataset, featureLabels):
#递归终止条件1:所有数据集中的类别相同
classList=[data[-1] for data in dataset]
if classList.count(classList[0])==len(classList):
return classList[0]
#递归终止条件2:使用完了所有特征
if len(featureLabels)==1:
return MajorClass(classList)
#找到最好的数据集划分方式
bestFeature=BestFeature(dataset)#特征的下标
bestFeatureLabel=featureLabels[bestFeature]#特征的名称
myTree={bestFeatureLabel:{}}
del(featureLabels[bestFeature])
bestFeatureValue=[data[bestFeature] for data in dataset]#该特征对应的不同值
uniqueFeaVal=set(bestFeatureValue)
for value in uniqueFeaVal:
subFeatureLabels=featureLabels[:]#函数参数为列表时,参数是按照引用方式传递,为了防止下一步调用时改变原始列表的内容
myTree[bestFeatureLabel][value]=CreatTree(SplitData(dataset,bestFeature,value),\
subFeatureLabels)
return myTree推荐博文http://blog.csdn.net/suipingsp/article/details/41927247,http://www.cnblogs.com/bourneli/archive/2013/03/15/2961568.html
以下是我总结的笔记。
1.分类原理

决策树分类器就像判断模块和终止块组成的流程图,终止块表示分类结果(也就是树的叶子)。判断模块表示对一个特征取值的判断(该特征有几个值,判断模块就有几个分支)
实际上,样本所有特征中有一些特征在分类时起到决定性作用,决策树的构造过程就是找到这些具有决定性作用的特征,根据其决定性程度来构造一个倒立的树--决定性作用最大的那个特征作为根节点,然后递归找到各分支下子数据集中次大的决定性特征,直至子数据集中所有数据都属于同一类。所以,构造决策树的过程本质上就是根据数据特征将数据集分类的递归过程,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时起决定性作用。
2.决策树的学习过程
a)特征选择-----找到当前数据集中决定性作用最大的特征
b)决策树生成------按照所选特征对当前数据集分类,然后由上到下递归生成子节点
c)剪枝-----决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种
3.什么样的特征“决定性作用最大”?
1)ID3算法------选信息增益最大的特征
信息熵:
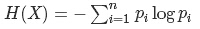
条件熵:
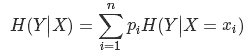
信息增益:
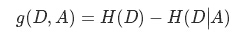
结合决策树:
分类系统信息熵
假设一个分类系统的样本空间(D,Y),D表示样本(有m个特征),Y表示n个类别,可能的取值是C1,C2,...,Cn。每一个类别出现的概率是P(C1),P(C2),...,P(Cn)。该分类系统的熵为:
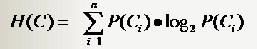
离散分布中,类别Ci出现的概率P(Ci),通过该类别出现的次数除去样本总数即可得到。对于连续分布,常需要分块做离散化处理获得。
条件熵
根据条件熵的定义,分类系统中的条件熵指的是当样本的某一特征X固定时的信息熵。由于该特征X可能的取值会有(x1,x2,……,xn),当计算条件熵而需要把它固定的时候,每一种可能都要固定一下,然后求统计期望。
因此样本特征X取值为xi的概率是Pi,该特征被固定为值xi时的条件信息熵就是H(C|X=xi),那么
H(C|X)就是分类系统中特征X被固定时的条件熵(X=(x1,x2,……,xn)):
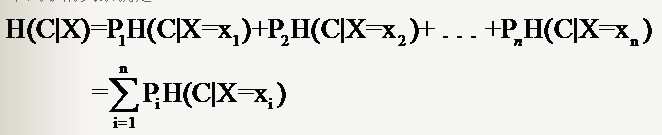
若是样本的该特征只有两个值(x1 = 0,x2=1)对应(出现,不出现),如文本分类中某一个单词的出现与否。那么对于特征二值的情况,我们用T代表特征,用t代表T出现,表示该特征出现。那么:
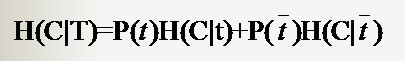
与前面条件熵的公式对比一下,P(t)就是T出现的概率,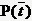
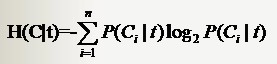
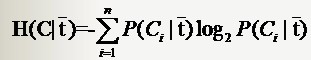
特征T出现的概率P(t),只要用出现过T的样本数除以总样本数就可以了;P(Ci|t)表示出现T的时候,类别Ci出现的概率,只要用出现了T并且属于类别Ci的样本数除以出现了T的样本数就得到了。
信息增益
根据信息增益的公式,分类系统中特征X的信息增益就是:Gain(D, X) = H(C)-H(C|X)
信息增益是针对一个一个的特征而言的,就是看一个特征X,系统有它和没它的时候信息量各是多少,两者的差值就是这个特征给系统带来的信息增益。每次选取特征的过程都是通过计算每个特征值划分数据集后的信息增益,然后选取信息增益最高的特征。
对于特征取值为二值的情况,特征T给系统带来的信息增益就可以写成系统原本的熵与固定特征T后的条件熵之差:
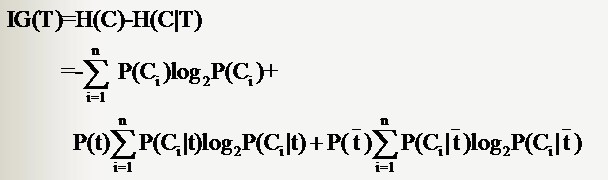
(4)经过上述一轮信息增益计算后会得到一个特征作为决策树的根节点,该特征有几个取值,根节点就会有几个分支,每一个分支都会产生一个新的数据子集Dk,余下的递归过程就是对每个Dk再重复上述过程,直至子数据集都属于同一类。
缺点:可用于划分标称型数据集(离散值),不能处理连续分布的数据特征
偏向于具有大量值的属性–就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的
2)C4.5------选信息增益率最大的特征
信息增益率=信息增益 / 分裂信息度量
SplitInformation(D,X) = -P1 log2(P1)-P2 log2(P)-,...,-Pn log2(Pn) (特征X区不同值得到的熵,取值为x1,x2,……,xn,各自的概率为P1,P2,...,Pn)
GainRatio(D,X) = Gain(D,X)/SplitInformation(D,X)
离散型属性
C4.5的处理方法与ID3相同
连续型属性
先把连续属性转换为离散属性再进行处理
a)
b)
c)选择修正后信息增益(InforGain)最大的分裂点作为该特征的最佳分裂点
d)
优点:克服了用信息增益选择属性时偏向选择取值多的属性的不足在树构造过程中进行剪枝
能够完成对连续属性的离散化处理
能够对不完整数据进行处理。
缺点:效率低,因树构造过程中,需要对数据集进行多次的顺序扫描和排序。
因为必须多次数据集扫描,C4.5只适合于能够驻留于内存的数据集。
3)CART算法------选Gini指数最小的特征

优点:简化了决策树的规模,提高了生成决策树的效率
4.什么时候停止分类
1)得到的子数据集属于同一类别
2)所有特征都作为分裂特征用光了,但子集还不是纯净集(集合内的元素不属于同一类别)。由于没有更多信息可以使用了,一般对这些子集进行“多数表决”,即使用此子集中出现次数最多的类别作为此节点类别,然后将此节点作为叶子节点。
5.决策树的优缺点
优点:计算复杂度不高,输出结果易于理解,可处理具有不相关特征的数据、可很容易地构造出易于理解的规则
缺点:处理缺失数据时的困难
过度拟合
忽略数据集中属性之间的相关性
6.过度拟合
原因:
噪音数据:训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。
缺少代表性数据:训练数据没有包含所有具有代表性的数据,导致某一类数据无法很好的匹配,这一点可以通过观察混淆矩阵(Confusion Matrix)得知
多重比较(Mulitple Comparition):举个列子,股票分析师预测股票涨或跌。假设分析师都是靠随机猜测,也就是他们正确的概率是0.5。每一个人预测10次,那么预测正确的次数在8次或8次以上的概率为 ![]() ,只有5%左右,比较低。但是如果50个分析师,每个人预测10次,选择至少一个人得到8次或以上的人作为代表,那么概率为
,只有5%左右,比较低。但是如果50个分析师,每个人预测10次,选择至少一个人得到8次或以上的人作为代表,那么概率为 ![]() ,概率十分大,随着分析师人数的增加,概率无限接近1。但是,选出来的分析师其实是打酱油的,他对未来的预测不能做任何保证。上面这个例子就是多重比较。这一情况和决策树选取分割点类似,需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的。
,概率十分大,随着分析师人数的增加,概率无限接近1。但是,选出来的分析师其实是打酱油的,他对未来的预测不能做任何保证。上面这个例子就是多重比较。这一情况和决策树选取分割点类似,需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的。
应对策略:
方案1:修剪枝叶
决策树过渡拟合往往是因为太过“茂盛”,也就是节点过多,所以需要裁剪(Prune Tree)枝叶。裁剪枝叶的策略对决策树正确率的影响很大。主要有两种裁剪策略。
前置裁剪 在构建决策树的过程时,提前停止。那么,会将切分节点的条件设置的很苛刻,导致决策树很短小。结果就是决策树无法达到最优。实践证明这中策略无法得到较好的结果。
后置裁剪 决策树构建好后,然后才开始裁剪。采用两种方法:1)用单一叶节点代替整个子树,叶节点的分类采用子树中最主要的分类;2)将一个字数完全替代另外一颗子树。后置裁剪有个问题就是计算效率,有些节点计算后就被裁剪了,导致有点浪费。
方案2:K-Fold Cross Validation
首先计算出整体的决策树T,叶节点个数记作N,设i属于[1,N]。对每个i,使用K-Fold Validataion方法计算决策树,并裁剪到i个节点,计算错误率,最后求出平均错误率。这样可以用具有最小错误率对应的i作为最终决策树的大小,对原始决策树进行裁剪,得到最优决策树。
方案3:Random Forest
Random Forest是用训练数据随机的计算出许多决策树,形成了一个森林。然后用这个森林对未知数据进行预测,选取投票最多的分类。实践证明,此算法的错误率得到了经一步的降低。这种方法背后的原理可以用“三个臭皮匠定一个诸葛亮”这句谚语来概括。一颗树预测正确的概率可能不高,但是集体预测正确的概率却很高。
二、实例操作(ID3算法)----预测隐形眼镜类型
#decision_tree.py
from math import log
import operator
#计算熵
def CalEnt(dataset):
size=len(dataset)
Labels={}
for data in dataset:
lab=data[-1];
if lab not in Labels.keys():
Labels[lab]=1;
else:
Labels[lab]+=1;
entropy=0.0
for key in Labels:
prob=float(Labels[key])/size
entropy-=prob*log(prob,2)
return entropy
#按照给定特征划分数据集,并返回不包含给定特征值的新数据集
def SplitData(dataset,index,value):
retset=[]
for data in dataset:
if data[index]==value:
temp=data[:index]
temp.extend(data[index+1:])
retset.append(temp)
return retset
#选择最好的数据集划分方式--即信息增益最大的特征
def BestFeature(dataset):
featureSize=len(dataset[0])-1
baseEnt=CalEnt(dataset)
bestGain=0.0
bestFeature=-1
for i in range(featureSize):
feaset=[data[i] for data in dataset]
feakind=set(feaset)
nowEnt=0.0
for fea in feakind:
subset=SplitData(dataset,i,fea)
prob=float(len(subset))/len(dataset)
nowEnt+=prob*CalEnt(subset)
gain=baseEnt-nowEnt
if gain>bestGain:
bestGain=gain
bestFeature=i
return bestFeature #返回的是特征的下标
#若属性遍历完得到的数据集仍有多个类别,取数目最多的类别作为该数据集类别
def MajorClass(classList):
classCount={}
for item in classList:
if item not in classCount.keys():
classCount[item]=0
classCount[item]+=1
return max(classCount) #比书上得到最大值的方法简单
#创建树
def CreatTree(dataset, featureLabels):
#递归终止条件1:所有数据集中的类别相同
classList=[data[-1] for data in dataset]
if classList.count(classList[0])==len(classList):
return classList[0]
#递归终止条件2:使用完了所有特征
if len(featureLabels)==1:
return MajorClass(classList)
#找到最好的数据集划分方式
bestFeature=BestFeature(dataset)#特征的下标
bestFeatureLabel=featureLabels[bestFeature]#特征的名称
myTree={bestFeatureLabel:{}}
del(featureLabels[bestFeature])
bestFeatureValue=[data[bestFeature] for data in dataset]#该特征对应的不同值
uniqueFeaVal=set(bestFeatureValue)
for value in uniqueFeaVal:
subFeatureLabels=featureLabels[:]#函数参数为列表时,参数是按照引用方式传递,
#为了防止下一步调用时改变原始列表的内容
myTree[bestFeatureLabel][value]=CreatTree(SplitData(dataset,bestFeature,value),\
subFeatureLabels)
return myTree
#测试算法--遍历整棵树,比较test的值和节点数的值
def Classify(myTree,featureLabels,test):
firstFea=list(myTree.keys())[0]#先和树根比
secondDict=myTree[firstFea]#树根特征的取值
feaIndex=featureLabels.index(firstFea)#树根特征在featureLabels的下标
for key in secondDict.keys():
if(test[feaIndex]==key):
if type(secondDict[key]).__name__=='dict':
Classify(secondDict[key],featureLabels,test)
else:
classLabel=secondDict[key]
return classLabel
#存储决策树
def StoreTree(myTree,filename):
import pickle
fw=open(filename,'w')
pickle.dump(mytree,filename)
f.close()
#取出决策树
def getTree(filename):
import pickle
fr=open(filename)
return pickle.load(f)
if __name__=='__main__':
#使用决策树预测眼镜类型
import decision_tree
fr=open('G:\\程序\\python\\2.决策树\\lenses.txt')
lenses=[line.strip().split('\t') for line in fr.readlines()]
lensesLabels=['age','prescript','astigmatic','tearRate']
lensesTree=decision_tree.CreatTree(lenses,lensesLabels)
print(lensesTree)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









