






1.1基本概念:
本篇笔记是本人通过在b站学习黑马程序员的spark课程,而后自己练习并整理的笔记,希望通过写笔记的方式将知识梳理的更加清楚!!!通过代码,能够让我们对相关算子的应用以及其算子的功能有更加清晰地认识。同时,在代码当中,也对相应代码进行了注释,这就减轻了阅读代码地压力,当然,我也很相信各位的实力!!!
定义:transformation算子:即转换算子,是RDD的算子,对RDD进行转换,返回值仍然是RDD类型;
特征:transformation算子是lazy懒加载的,如果没有action算子,transformation算子是不会工作的;
接下来就将常见的transformation算子通过代码进行举例并阐述;
1.2常见transformation算子
1)map算子:是将RDD的数据一条条处理,(处理的逻辑,是基于map算子中接收的处理函数),返回新的RDD;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
# 构建sparkcontext对象
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 创建rdd
rdd=sc.parallelize([1,2,3,4,5,6],3)
# 定义方法,作为算子的传入函数体
def add(data):
return data*10
rdd2=rdd.map(add)
print(rdd2.collect())
# 方式二:定义lambda表达式来写匿名函数
print(rdd.map(lambda data:data*10).collect())
"""
对于算子的接收函数来说,两种方法都可以
lambda表达式 适用于一行代码就搞定的函数体,如果是多行,需要定义独立的方法
"""运行结果:

2)flatMap算子:先是对RDD执行map操作,而后进行解除嵌套操作;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
# 创建的rdd
rdd=sc.parallelize(["hadoop spark flink","spark hadoop hdfs","hdfs spark hive"])
# 为展示flatmap过程中的map过程,调用map对结果进行输出,更有助于理解
print("执行map之后的结果:")
print(rdd.map(lambda line:line.split(" ")).collect())
# flatmap是先对rdd进行map,而后对map之后的新的rdd进行解嵌套操作
rdd1=rdd.flatMap(lambda line:line.split(" "))
print("执行flatmap之后的结果:")
print(rdd1.collect())运行结果:

3) reduceByKey算子:是针对kv型RDD,自动按照key进行分组,然后根据所提供的聚合逻辑,完成组内数据(组内的value)的聚合操作;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([('hadoop',2),('spark',1),('flink',3),('hadoop',1),('spark',1),('flink',1)])
# reducebykey算子,在这里对key进行自动分组,传入的函数是对value进行相加
rdd2=rdd.reduceByKey(lambda a,b:a+b)
print(rdd2.collect())运行结果:

4)mapValues算子:针对kv型RDD,对其内部的二元元组的value执行map操作;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([('hadoop',2),('spark',1),('flink',3),('hadoop',1),('spark',1),('flink',1)])
# mapvalues算子 对key进行操作,在这里,我对key*10
rdd2=rdd.mapValues(lambda value:value*10)
print(rdd2.collect())运行结果:
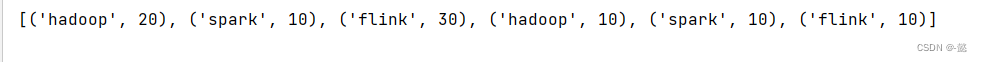
5)groupby算子:将RDD的数据进行分组;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([('a',1),('b',1),('a',1),('b',1),('a',1),('b',1)])
# groupbu传入的函数 通过这个函数,确定按照谁来分组(返回谁即可)
rdd1=rdd.groupBy(lambda x:x[0])
print(rdd1.collect())
# 强制转换为list.map算子对数据一条一条的处理
rdd2=rdd1.map(lambda x:(x[0],list(x[1])))
print(f"强制转换后的结果为{rdd2.collect()}")运行结果:
 6)groupByKey算子:针对kv型RDD,自动按照key进行分组操作;
6)groupByKey算子:针对kv型RDD,自动按照key进行分组操作;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([('hadoop',1),('spark',2),('hadoop',3),('spark',2)])
rdd1=rdd.groupByKey()
# 对rdd进行按照key自动分组
print(f"分组之后的数据{rdd1.collect()}")
# 对数据进行强制转换
print("强制转换之后的数据")
print(rdd1.map(lambda x:(x[0],list(x[1]))).collect())
运行结果:

7)filter算子:对RDD中的数据进行过滤,根据传入函数,保留自己想要的函数;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([1,2,3,4,5,6])
# 通过过滤保留奇数 x%2==0表示偶数,则x%2==1表示为奇数
rdd1=rdd.filter(lambda x:x%2==1)
print(f"奇数为:{rdd1.collect()}")运行结果:

8)distinct算子:对RDD中的数据进行去重操作,返回新的RDD;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([1,2,3,4,1,2,1])
rdd1=rdd.distinct()
print(f"去重之后的结果为:{rdd1.collect()}")
rdd2=sc.parallelize([('hadoop',1),('spark',1),('hadoop',3),('spark',2),('hadoop',1),('spark',1)])
rdd3=rdd2.distinct()
print(f"元组去重之后的结果为:{rdd3.collect()}")运行结果:

9) union算子:将两个RDD合并成为一个新的RDD,只是合并操作,不会对合并的RDD进行去重操作;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([1,2,3,4,5,6])
# 通过读取hdfs当中的数据创建rdd
rdd1=sc.textFile('hdfs://node1:8020/input/words.txt')
# 使用union对两个rdd进行合并
rdd3=rdd.union(rdd1)
print(f"合并之后的rdd{rdd3.collect()}")
"""
不会对数据进行去重
不同的数据类型可以进行合并
"""运行结果:

10)join算子:对两个RDD执行join操作,join算子只能用于二元元组,关联规则是按照二元元组的key进行关联;
join算子分为:内连接、左外连接、右外连接
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([(1001,'zhangsan'),(1002,'wangwu'),(1003,'hanmeimei'),(1001,'xiaoxiao'),(1004,'zhasan')])
rdd1=sc.parallelize([(1001,'销售部'),(1002,'协商部'),(1003,'仓库部')])
# 进行关联两个rdd 内连接
rdd2=rdd.join(rdd1)
print(f"内连接的结果:{rdd2.collect()}")
# 左外连接,与sql当中的左外连接规则一致,左外连接是将左边的作为主表,如果左表与连接的表出现对不上key的时候,就会出现value为空的情况
rdd3=rdd.leftOuterJoin(rdd1)
print(f"左外连接的结果为:{rdd3.collect()}")
# 右外连接
rdd4=rdd.rightOuterJoin(rdd1)
print(f"右外连接的结果为:{rdd4.collect()}")运行结果:

11)intersection算子:得到两个RDD的交集,返回新的RDD;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([1,2,3,4,90])
rdd1=sc.parallelize([1,3,5,4,60])
# 取两个rdd之间的交集
rdd2=rdd.intersection(rdd1)
print(f"两个rdd的交集为:{rdd2.collect()}")
运行结果:

12)glom算子:将rdd的数据,按照分区加上嵌套,主要是用来对分区的数据进行区分;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([1,2,3,4,90],2)
rdd2=rdd.glom()
print(rdd2.collect())
# 对rdd2进行解嵌套 传入的函数:什么事情也不做,将数据直接返回,使用flatMap对嵌套的数据进行解嵌套
rdd3=rdd.glom().flatMap(lambda x:x)
print(f"解嵌套之后的数据:{rdd3.collect()}")
运行结果:

13)sortby:对RDD中的数据进行排序;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([('h',1),('s',4),('a',3),('k',2)])
# 按照value进行排序
print("按照value进行升序排序")
# 传入的函数表示按照元组中下标为1的进行排序,也就会按照数字(value)进行排序 ascending=True表示升序,False表示降序 numPartitions表示用多少分区排序
rdd1=rdd.sortBy(lambda x:x[1],ascending=True,numPartitions=1)
print(rdd1.collect())
# 按照key进行排序
print("按照key进行降序排序")
rdd2=rdd.sortBy(lambda x:x[0],ascending=False,numPartitions=1)
print(rdd2.collect())运行结果:
 14)sortByKey:针对kv型,自动按照key进行排序;
14)sortByKey:针对kv型,自动按照key进行排序;
from pyspark import SparkConf,SparkContext
import os
os.environ['JAVA_HOME']="/export/server/jdk1.8.0_241"
if __name__ == '__main__':
conf=SparkConf().setAppName("test").setMaster("local[*]")
sc=SparkContext(conf=conf)
rdd=sc.parallelize([('h',1),('s',4),('a',3),('k',2),('A',1),('B',4),('Y',3),('y',2)])
# lower()表示将key中的所有大写的字母转换为小写
rdd1=rdd.sortByKey(ascending=True,numPartitions=1,keyfunc=lambda x:str(x).lower())
print(f"将大写转换为小写之后并进行排序:{rdd1.collect()}")运行结果:

总结:在这14个常用transformation算子当中,有很多算子的功能和用法都和sql当中的语句类似,相信接触过sql的家人,已经发现了,我也是之前学过了sql语句,在学习这些算子的时候,才发现好多类似,所以,学习起来还是轻松一些。同时,大家一定要多多敲代码,在实践当中提升的更快,肯定也要提醒大家要好好利用暑假辣!!!
特别声明:若有错误之处,还请多多指教!!!















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









