







Hive加载数据操作
一、load data
语法结构:
load data [local] inpath 'filepath' [overwrite] into table table_name [partition(part1=val1,part2=val2)]说明:
1、Load
操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置
2、filepath:
相对路径,例如:project/data1
绝对路径,例如:/user/hive/project/data1
包含模式的完整 URI,如:hdfs://namenode:9000/user/hive/project/data1
3、local关键字
如果指定了local,load命令会去查找本地文件系统中的filepath。如果没有指定local关键字,则根据inpath中的uri查找文件
4、overwrite 关键字
如果使用了overwrite关键字,则目标表(或者分区)中的内容会被删除,然后再将filepath指向的文件/目录中的内容添加到表/分区中。
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。1.1 加载本地数据
# 创建表
create table tb_load1(id int,name string)
row format delimited fields terminated by ',';
# 加载本地数据
load data local inpath '/home/hadoop/load1.txt' into table tb_load1;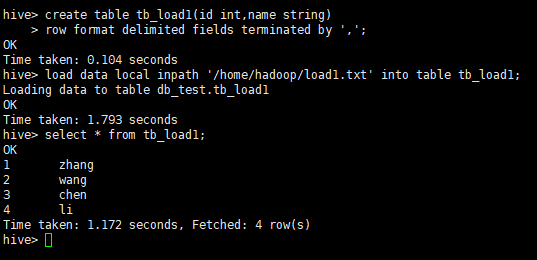
1.2 加载hdfs数据
load data inpath '/hive/test/load2.txt' into table tb_load1;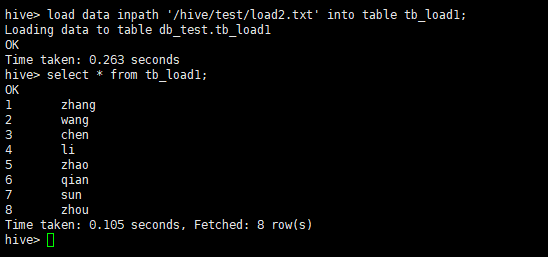
从hdfs加载数据成功后,数据会删除。
1.3 加载数据到分区表
# 创建分区表
create table tb_load2(id int ,name string)
partitioned by (sex string)
row format delimited fields terminated by ',';
# 加载数据,数据本身要是分区的数据
load data inpath '/hive/test/load_part_male.txt' into table tb_load2 partition (sex='male');
load data inpath '/hive/test/load_part_female.txt' into table tb_load2 partition (sex='female');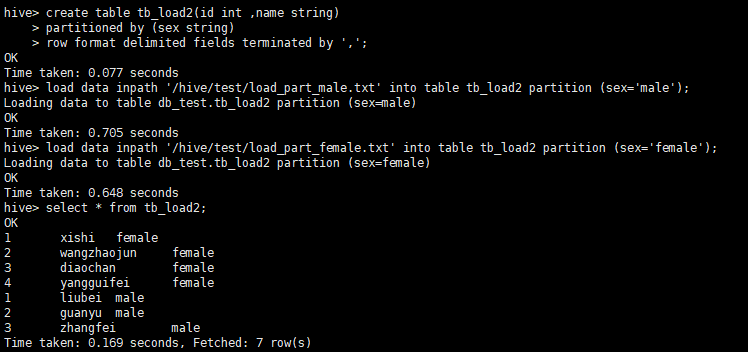
1.4 使用overwrite关键字
load data local inpath '/home/hadoop/load3.txt' overwrite into table tb_load1;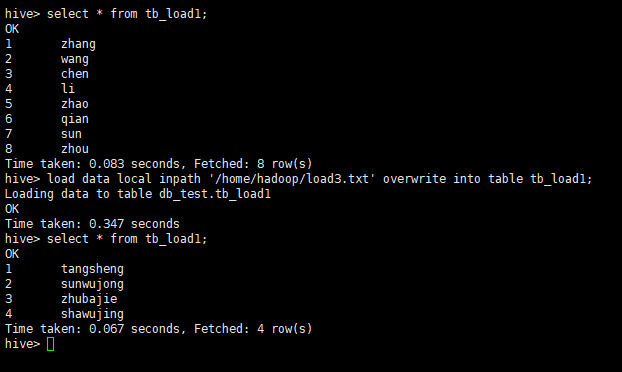
overwrite会覆盖之前的数据
二、insert语句插入数据
语法结构:
# 重其他表查询结果,插入并覆盖新表
insert overwrite/into table table_name
[partition(part=val,part2=val2,...)]
select fileds,... from tb_other;多个insert语句插入语法结构:
from table_name t
insert overwrite table tb1 [partition(col=val,...)]
select 语句
insert overwrite table tb2 [partition(col=val,...)]
select 语句
...;2.1 简单使用insert语句
create table tb_select1 (id int,name string,sex string)
row format delimited fields terminated by ',';
create table tb_insert1(id int,name string);
insert overwrite table tb_insert1 select id,name from tb_select1;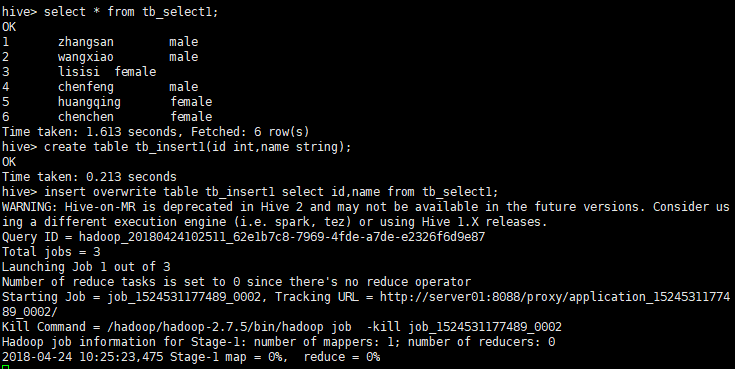
查看下tb_insert1表数据
select * from tb_insert1;
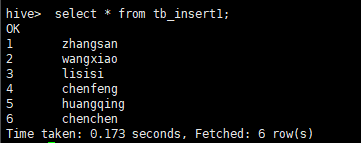
使用 insert into进行插入
insert into table tb_insert1 select id,name from tb_select1 limit 2;查询结果:
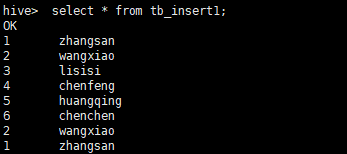
2.2 使用insert语句分区插入
create table tb_insert_part(id int,name string)
partitioned by(sex string);
insert overwrite table tb_insert_part partition(sex = 'male')
select id,name from tb_select1 where sex='male';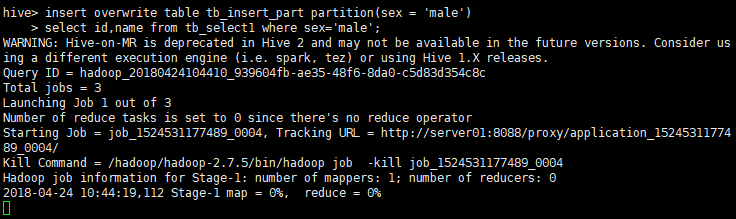
查询结果:
select * from tb_insert_part;
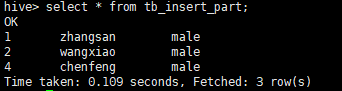
2.3 多个insert插入
create table tb_mutil_insert1(id int,name string)
partitioned by(sex string);
create table tb_mutil_insert2(id int,name string)
partitioned by(sex string);
from tb_select1 t
insert overwrite table tb_mutil_insert1 partition (sex='male')
select t.id,t.name where t.sex='male'
insert overwrite table tb_mutil_insert2 partition (sex='female')
select t.id,t.name where t.sex='female';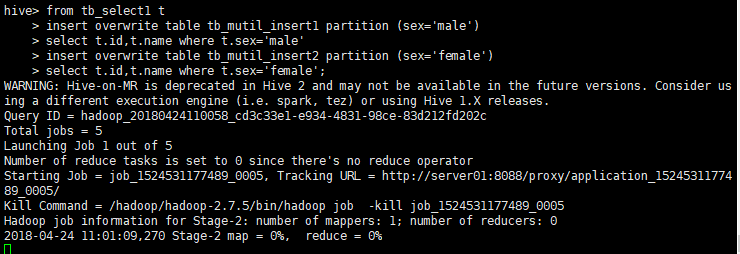
查询结果:
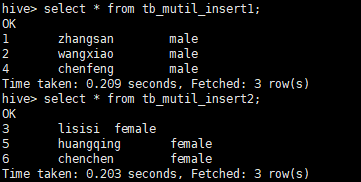
2.4 动态分区插入
create table tb_dy_part(id int,name string) partitioned by(sex string);
insert overwrite table tb_dy_part partition(sex)
select id,name,sex from tb_select1;
要使用动态分区,默认是使用严格模式,需要使用分区才行,或者将动态分区模式设置为非严格模式。
FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict设置动态分区模式为非严格模式
set hive.exec.dynamic.partition.mode=nonstrict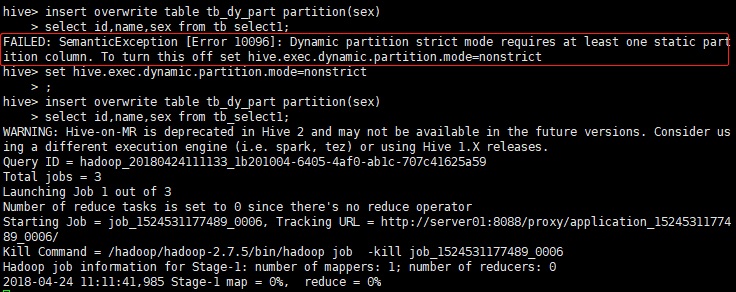
三、使用create table的方式,将查询数据插入表中
create table tb_create_mode as
select id,name from tb_select1;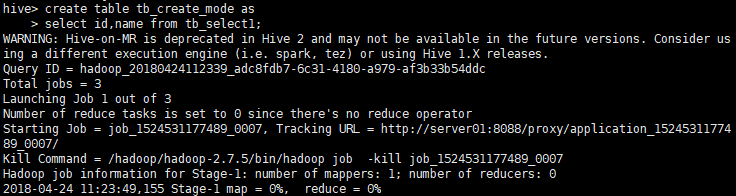
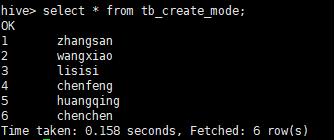
结果:
四、导出数据
4.1 单条数据导出到本地
insert overwrite local directory '/home/hadoop/'
select id,name from tb_select1;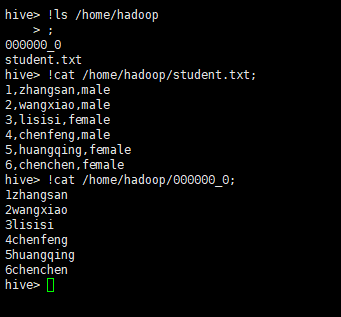
4.2 多条数据导出到hdfs
from tb_select1 t
insert overwrite directory '/hive/test/male'
select t.id,t.name,t.sex where t.sex='male'
insert overwrite directory '/hive/test/female'
select t.id,t.name,t.sex where t.sex='female';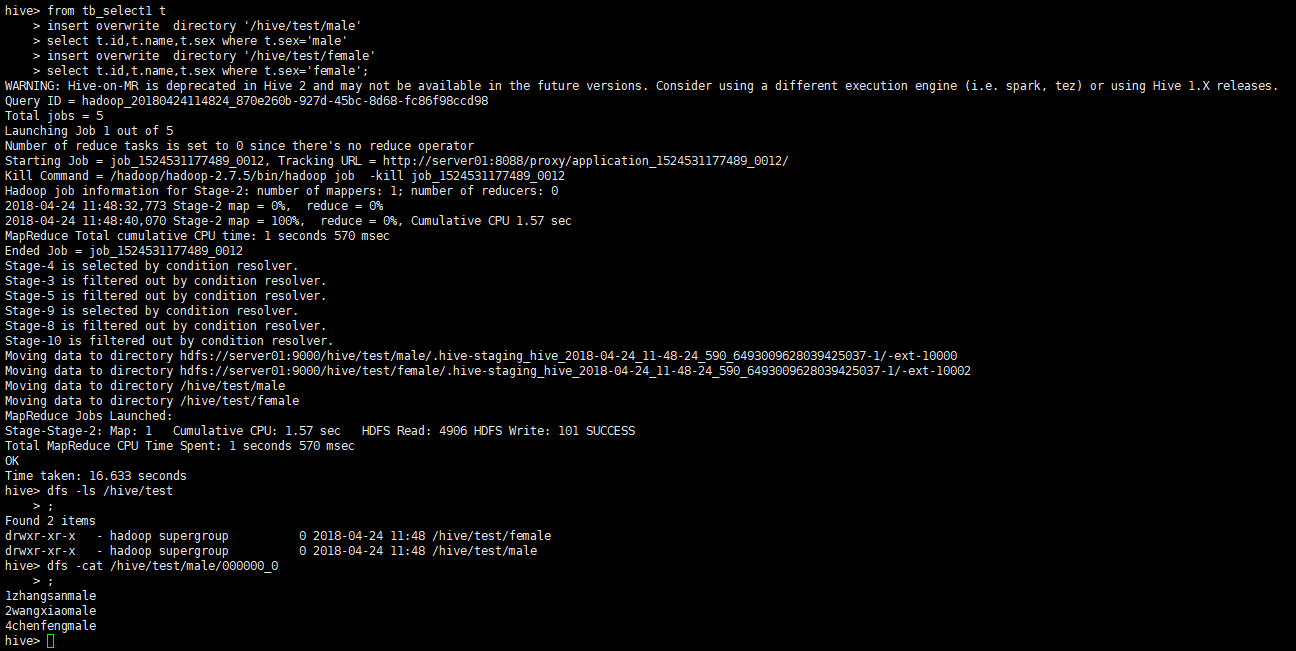















 3029
3029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









