







关于自适应哈夫曼编码,常用的有FGK和Vitter。这里讲的是FGK,先放上一个关于FGK的网页,以便于理解过程。
Visual FGK
FGK算法的原理
夫曼树每一个结点有且仅有两个分支,必须总是保持其兄弟性质,也就是所有的结点都是按照从左到右、从下到上计数递增的顺序排列的。如果违反了兄弟性质,则将触发一个交换过程对节点进行重新排列。当前计数为N的节点要寻找最远的既有计数N的且顺序更前的节点进行交换(包括节点的子树),然后自身次数再更新加一。要对整棵树进行遍历,直到不能更新为止。具体例子请看上方链接。
编码
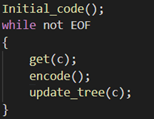
解码
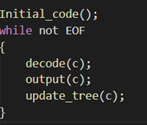
①编码器和解码器要用完全相同的Initial_code()和update_tree()。 ②Initial_code为字符分配初始化编码,我采用的就是ASCII码。
③update_tree是构造自适应赫夫曼编码的过程,把读取到的字符次数加一并且更新树。
核心代码
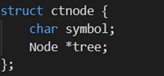
结构体
节点结构体

字符结构体
encode
create_tree():初始化赫夫曼树
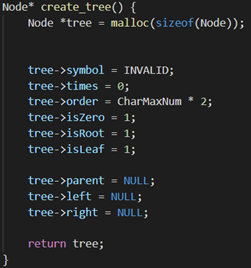
每次读取一个字符,判断该字符是否出现过,如果已经出现过则输出该字符在树中的编码,在更新节点的次数以及更新树。如果是一个新字符,则先输出树中当前NEW的编码,NEW再分为一个NEW节点和新字符节点,最后更新树。

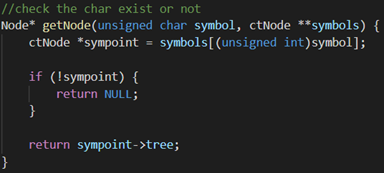
getNode():判断字符是否出现过,在symbols数组中查看是否出现过该字符,如果有则返回该字符节点指针。
codeOfNode():返回该字符节点在树中的编码,左分支为0,右分支为1,以此类推。由于我是从当前节点往根节点方向得到编码,所以最后要倒转编码。

addCodeToBuffer():把字符编码写入输出文件。

update_tree():更新赫夫曼树,从当前节点逆着到根节点,更新每个节点的位置和次数和。

decode
解压文件其实就是压缩文件的逆过程,对读入的每一个bit判断是0还是1,重新构建赫夫曼树,再根据编码把bit转换成ASCII码,得到真正的字符。每一次得到一个字符后都要更新赫夫曼树,注意处理最后一个字节一共有多少位。
源代码
见我的下载















 1889
1889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









