









一、单链表简介
-
概念介绍
链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) + 指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
以“结点的序列”表示线性表称作线性链表(单链表),单链表是链式存取的结构。 -
链接存储方法
链接方式存储的线性表简称为链表(Linked List)。链表的具体存储表示为:
① 用一组任意的存储单元来存放线性表的结点(这组存储单元既可以是连续的,也可以是不连续的)
② 链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址(或位置)信息(称为指针(pointer)或链(link))
链式存储是最常用的存储方式之一,它不仅可用来表示线性表,而且可用来表示各种非线性的数据结构。 -
结点结构
┌───┬───┐
│data │next │
└───┴───┘
data域--存放结点值的数据域
next域--存放结点的直接后继的地址的指针域(链域)
链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起的,每个结点只有一个链域的链表称为单链表(Single Linked List)。 -
头指针head和终端结点
单链表中每个结点的存储地址是存放在其前趋结点next域中,而开始结点无前趋,故应设头指针head指向开始结点。链表由头指针唯一确定,单链表可以用头指针的名字来命名。
终端结点无后继,故终端结点的指针域为空,即NULL。

单链表
二、实现单链表
1、创建单链表
// 结点类
public class Node<T> {
// 存储的数据
T data;
// 下一个结点的内存地址
Node<T> next;
public Node() {
}
public Node(T data) {
this.data = data;
this.next = null;
}
}
// 单链表
public class SingleLinkedList<T> {
// 头结点
private Node<T> head;
private int size = 0;
public int getSize(){
return this.size;
}
public SingleLinkedList() {
}
}2、链表简单操作
-
头部插入结点
实现思路:如果链表没有头结点,新结点直接成为头结点;否则新结点的next直接指向当前头结点,并让新结点成为新的头结点。
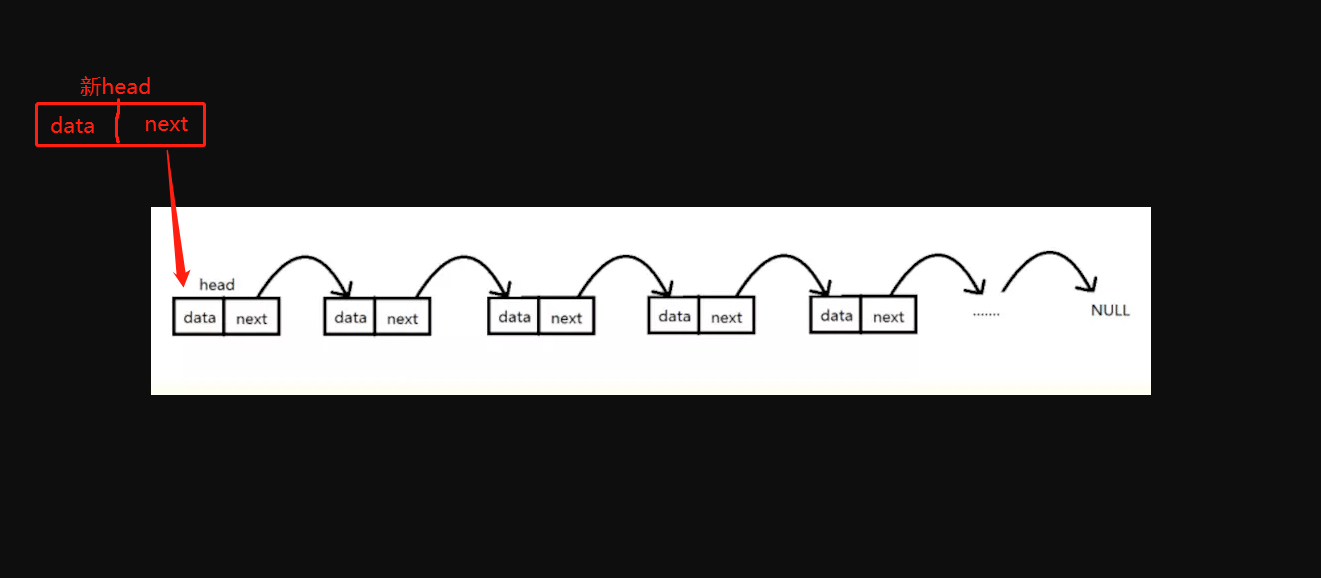
头部插入节点
/**
* 添加结点到链表头部
* @param data
*/
public void addHead(T data){
Node<T> newNode = new Node<>(data);
size++;
//头结点不存在,新结点成为头结点
if(null == head){
head = newNode;
return;
}
//新结点next直接指向当前头结点
newNode.next = head;
//新结点成为新的头结点
head = newNode;
}- 尾部插入结点
实现思路:如果链表没有头结点,新结点直接成为头结点;否则需要先找到链表当前的尾结点,并将新结点插入到链表尾部。
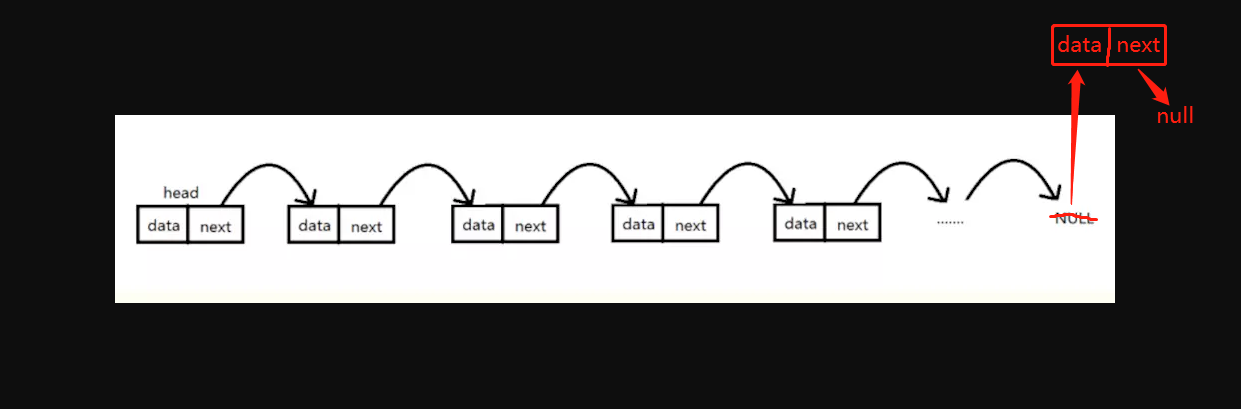
尾部插入节点
/**
* 添加结点到链表尾部
* @param data
*/
public void addLast(T data){
Node<T> newNode = new Node<>(data);
size++;
//头结点不存在,新结点成为头结点
if(null == head){
head = newNode;
return;
}
//查找最后一个结点
Node<T> last = head;
while (last.next != null){
last = last.next;
}
//新结点插入到链表尾部
last.next = newNode;
}
// 默认增加,在链表结尾添加新的结点,调用上面方法即可
public void add(T data){
addLast(data);
}-
指定位置插入结点
实现思路:先判断插入位置为头尾两端的情况,即index == 0插入到头部,index == size()插入到尾部;如果插入位置不是头尾两端,则先找出当前index位置的结点cur以及前一个结点 pre,然后cur成为新结点的下一个结点,新结点成为pre的后一个结点,这样就成功插入到index位置。
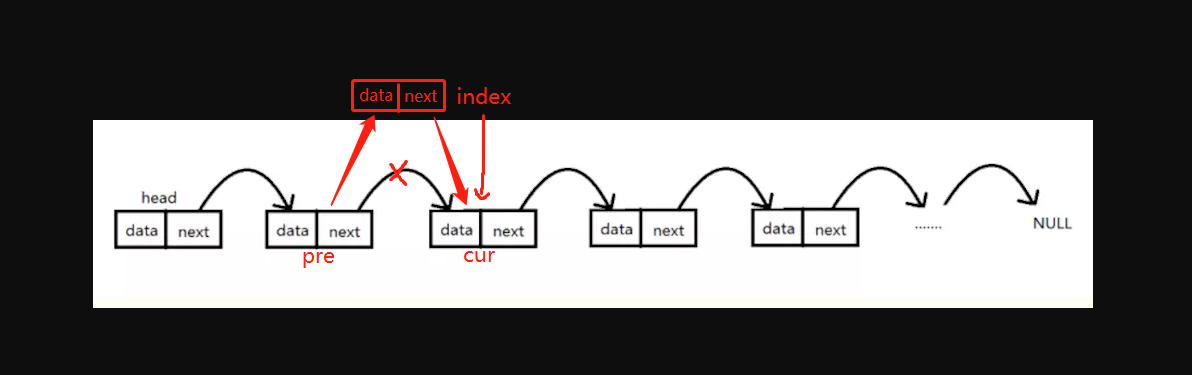
指定位置插入结点
/**
* 添加节点到链表中间的某个位置
* @param index 插入的索引位置
* @param data
*/
public void add(int index, T data){
if (index<0 || index > getSize()){
throw new IndexOutOfBoundsException("超出可添加的范围!");
}
if(index == 0){ //插入到头部
addHead(data);
}else if(index == getSize()) { //插入到尾部
addLast(data);
}else{ //插到某个中间位置
Node<T> newNode = new Node<>(data);
int position = 0;
Node<T> cur = head; //标记当前结点
Node<T> pre = null; //标记前置结点
while(cur!=null){
if(position == index){
newNode.next = cur;
pre.next = newNode;
size++;
return;
}
pre = cur;
cur = cur.next;
position++;
}
}
}
-
删除指定位置结点
实现思路:找出当前index位置的结点cur以及前一个结点 pre,pre.next直接指向cur.next即可删除cur结点。
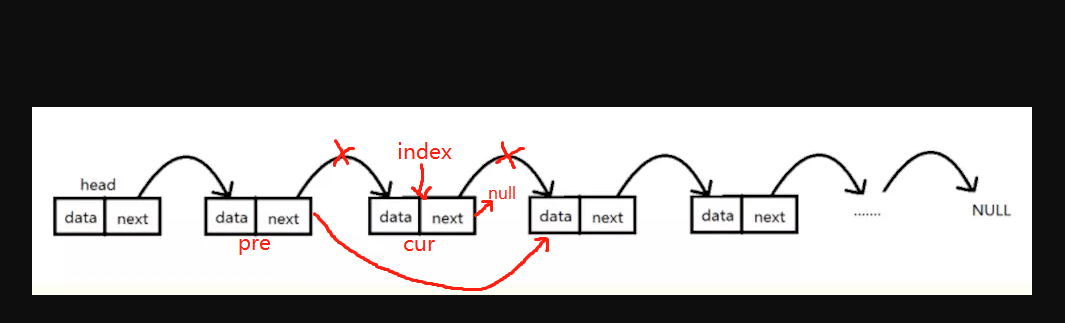
删除指定位置结点
/**
* 删除指定位置的数据
* @param index
*/
public void remove(int index){
if (index<0 || index > getSize()-1){
throw new IndexOutOfBoundsException("超出可添加的范围!");
}
if (index == 0) { //删除头
head = head.next;
size--;
return;
}
int position =0; //记录当前位置
Node<T> cur = head;
Node<T> pre = null;
while(cur!=null){
if(position == index){
pre.next = cur.next;
cur.next = null; //断开cur与链表的连接
size--;
}
pre = cur;
cur = cur.next;
position++;
}
}
/**
* 按data删除数据,从头遍历,遇到的第一个相同的删除
* @param data
* @return
*/
public boolean remove(T data){
Node<T> cur = head;
Node<T> pre = null;
while(cur != null){
if(cur.data.equals(data)){
pre.next = cur.next;
cur.next = null;
size--;
return true;
}
pre = cur;
cur = cur.next;
}
return false;
}
- 修改数据
实现思路:根据index找到对应的位置,然后修改data内容,其他不用改动
/**
* 修改数据的方法
* @param index
* @param data
*/
public void modify(int index,T data){
if (index<0 || index > getSize()){
throw new IndexOutOfBoundsException("超出可修改的范围!");
}
int position = 0;
Node<T> cur = head;
while(cur!=null){
if(position == index){
cur.data = data;
return;
}
cur = cur.next;
position++;
}
}- 查找数据
// 查找数据的方法
public T get(int index){
if (index<0 || index > getSize()){
throw new IndexOutOfBoundsException("超出可添加的范围!");
}
int position = 0;
Node<T> cur = head;
while(cur!=null){
if(position == index){
return cur.data;
}
cur = cur.next;
position++;
}
return null;
}-
链表反转
实现思路:在链表遍历的过程中将指针顺序置换,即每遍历一次链表就让cur.next指向pre,最后一个结点成为新的头结点。反转之后指针入下图红线所示。
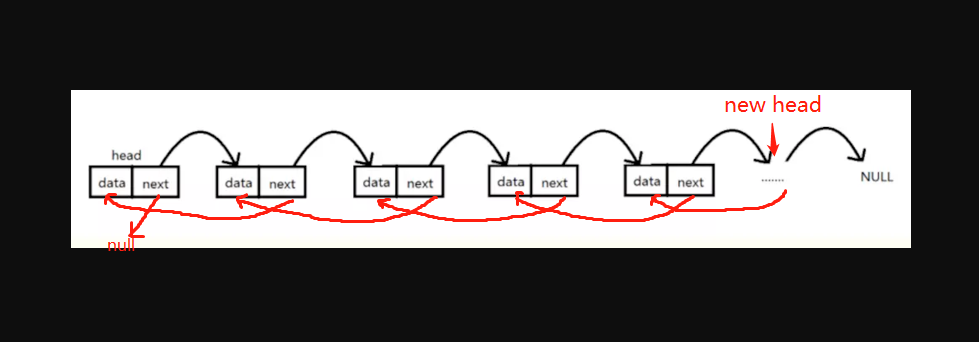
链表反转
/**
* 链表反转
*/
public void reverse(){
Node<T> cur = head; //标记当前结点
Node<T> pre = null; //标记当前结点的前一个结点
while(cur!=null){
Node<T> tmp = cur.next; //保存当前结点的下一个结点
cur.next = pre; //cur.next指向pre,指针顺序置换
//pre、cur继续后移
pre = cur;
cur = tmp;
}
head = pre;
}-
求倒数第k个结点
实现思路:倒数第k个结点就是第size - k + 1个结点,cur结点向后移动size- k次就是倒数第k个结点。
/**
* 倒数第k个结点
*
* @param k
* @return
*/
public T getLastK(int k) {
if (k < 0 || k > getSize()) { //注意index是可以等于size()的
throw new IndexOutOfBoundsException("IndexOutOfBoundsException");
}
Node<T> cur = head;
for (int i = 1; i < getSize() - k + 1; i++) {
cur = cur.next;
}
return cur.data;
}转载:https://www.jianshu.com/p/5495f22fbb53,增加部分内容















 3170
3170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









