







概述
Base64编码将一个8位子节序列拆散为6位的片段,而且这每个6位的片段都会被分配一个字符,那这个是个什么字符呢?其实它是base64字母表中的64个字符之一,所以顾名思义base64了。而这64个字符可是有讲究的,是选择了最常用而且兼容性最好的64个字符。所以可以算出base64编码后的字符串大约比编码前大了33%,因为用8位来表示6位。下面的详细的例子,大家来感受下。
Base64的几个规则
- 3字符变为4字符。
- 每76个字符增加一个换行符。
- 结束符也要编码。
转换流程
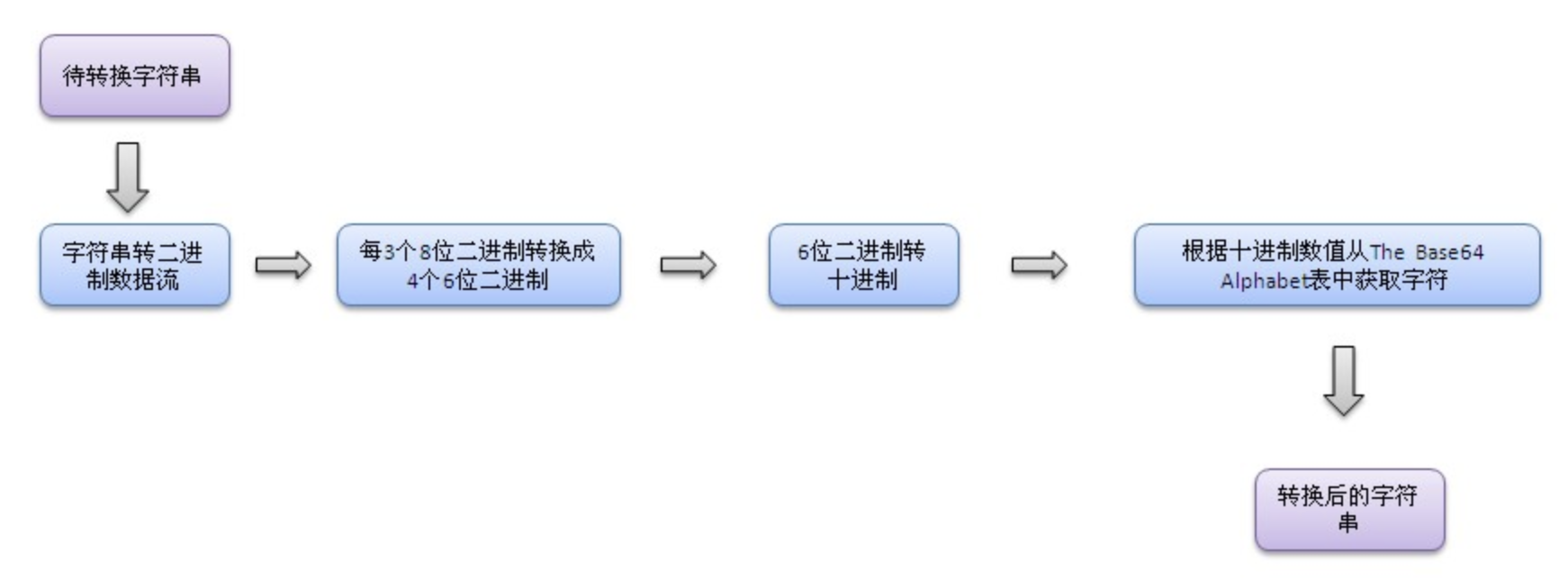

通俗易懂的示例
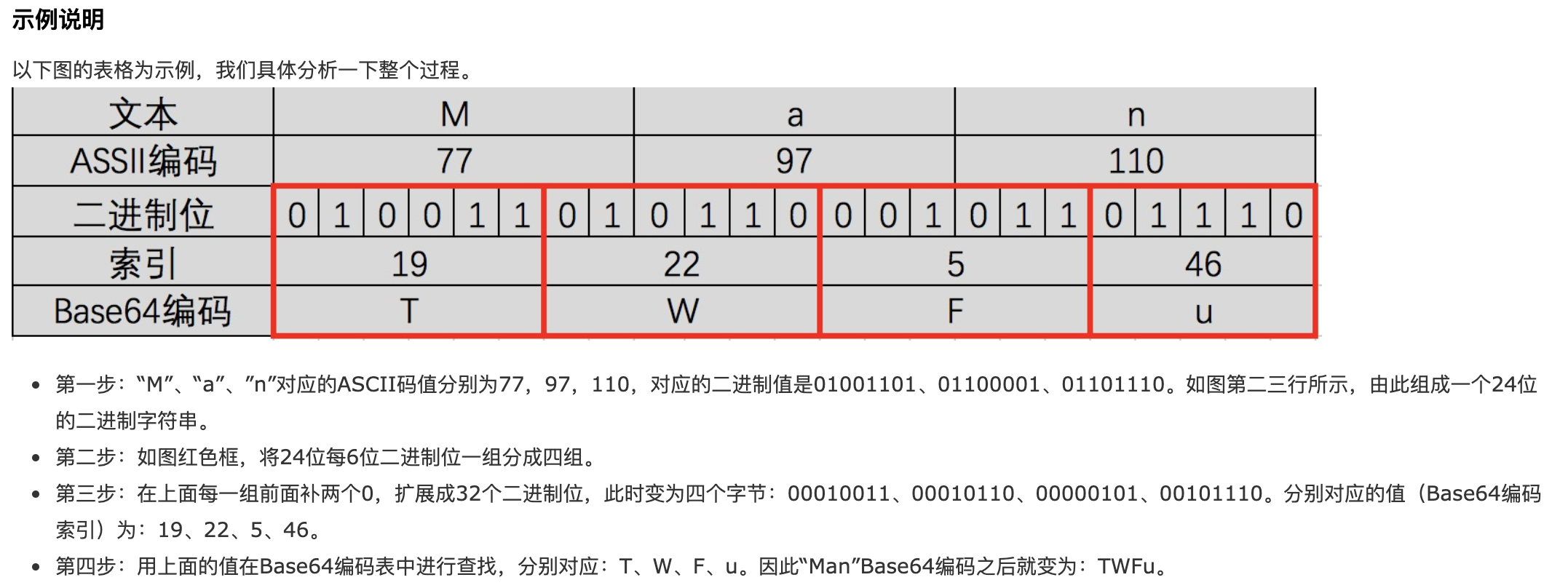
加入编码前的数据是“Ow!”,那编码之后是4个字符的base64编码值“T3ch”。下面是具体的转换过程。



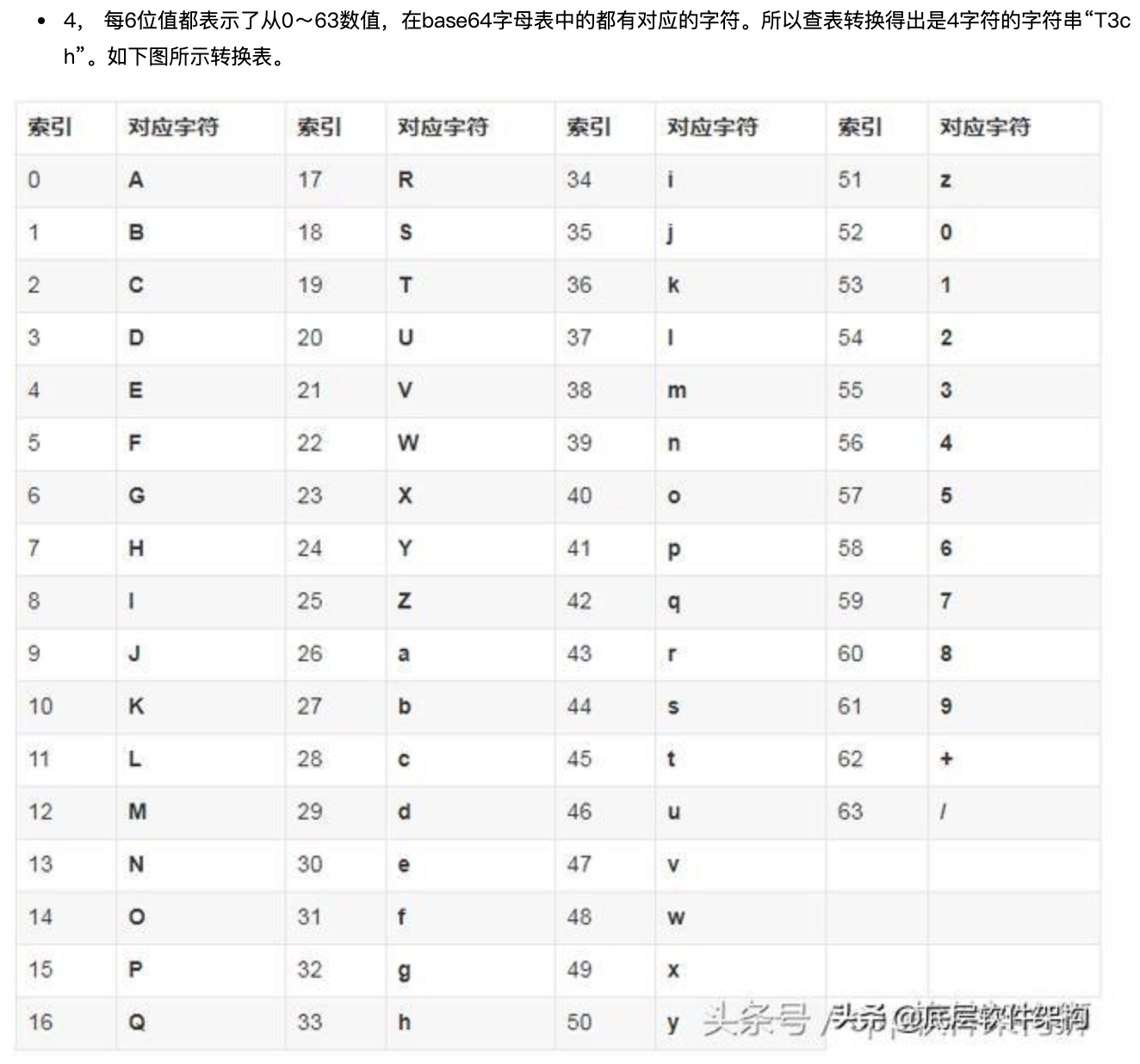
上面转换的是英文字母,中文GBK用两个字节表示,UTF-8用三个字节表示。原理一样,只是被拆成了多份
总结
- 大多数编码都是由字符串转化成二进制的过程,而Base64的编码则是从二进制转换为字符串。与常规恰恰相反。
- Base64编码主要用在传输、存储、表示二进制领域,不能算得上加密,只是无法直接看到明文。也可以通过打乱Base64编码来进行加密。
- 中文有多种编码(比如:utf-8、gb2312、gbk等),不同编码对应Base64编码结果都不一样。















 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









