







1.冒泡排序
- 算法思想:a:比较相邻的元素。如果第一个比第二个大,就交换他们两个。
-
b:对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
-
c:针对所有的元素重复以上的步骤,除了最后一个。
-
d:持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
图解:
实现代码:
2.快速排序
for (j = 0; j < n - 1; j++)
for (i = 0; i < n - 1 - j; i++)
{
if(a[i] > a[i + 1])
{
temp = a[i];
a[i] = a[i + 1];
a[i + 1] = temp;
}
}
算法思想:

设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。值得注意的是,快速排序不是一种稳定的排序算法,也就是说,多个相同的值的相对位置也许会在算法结束时产生变动。
一趟快速排序的算法是:
1)设置两个变量i、j,排序开始的时候:i=0,j=N-1;
2)以第一个数组元素作为关键数据,赋值给key,即key=A[0];
3)从j开始向前搜索,即由后开始向前搜索(j--),找到第一个小于key的值A[j],将A[j]和A[i]互换;
4)从i开始向后搜索,即由前开始向后搜索(i++),找到第一个大于key的A[i],将A[i]和A[j]互换;
5)重复第3、4步,直到i=j; (3,4步中,没找到符合条件的值,即3中A[j]不小于key,4中A[i]不大于key的时候改变j、i的值,使得j=j-1,i=i+1,直至找到为止。找到符合条件的值,进行交换的时候i, j指针位置不变。另外,i==j这一过程一定正好是i+或j-完成的时候,此时令循环结束)。
图解:
代码实现:
void sort(int *a, int left, int right)
{
if(left >= right)/*如果左边索引大于或者等于右边的索引就代表已经整理完成一个组了*/
{
return ;
}
int i = left;
int j = right;
int key = a[left];
while(i < j) /*控制在当组内寻找一遍*/
{
while(i < j && key <= a[j])
/*而寻找结束的条件就是,1,找到一个小于或者大于key的数(大于或小于取决于你想升
序还是降序)2,没有符合条件1的,并且i与j的大小没有反转*/
{
j--;/*向前寻找*/
}
a[i] = a[j];
/*找到一个这样的数后就把它赋给前面的被拿走的i的值(如果第一次循环且key是
a[left],那么就是给key)*/
while(i < j && key >= a[i])
/*这是i在当组内向前寻找,同上,不过注意与key的大小关系停止循环和上面相反,
因为排序思想是把数往两边扔,所以左右两边的数大小与key的关系相反*/
{
i++;
}
a[j] = a[i];
}
a[i] = key;/*当在当组内找完一遍以后就把中间数key回归*/
sort(a, left, i - 1);/*最后用同样的方式对分出来的左边的小组进行同上的做法*/
sort(a, i + 1, right);/*用同样的方式对分出来的右边的小组进行同上的做法*/
/*当然最后可能会出现很多分左右,直到每一组的i = j 为止*/
}
图解:
代码:
int I,j;
Redtype temp;
for (i=1;i<n;i++)
{
temp = r[i];
j=i-1;
while (j>-1 &&temp.key<r[j].key)
{
r[j+1]=r[j];
j--;
}
r[j+1]=temp;
}
4.希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率。
-
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。(别如数据逆序,我们就要将该数据一位以一位的移动,浪费时间)
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。 -
算法步骤:
1)选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
2)按增量序列个数k,对序列进行k 趟排序;
3)每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
图解:
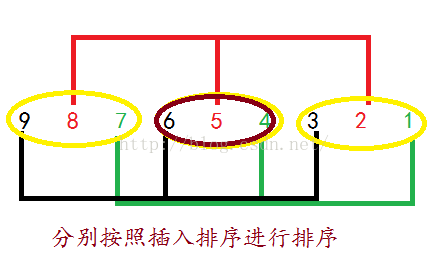
代码:
void shellInsert(int array[],int n,int dk)
{
int i,j,temp;
for(i=dk;i<n;i++)//分别向每组的有序区域插入
{
temp=array[i];
for(j=i-dk;(j>=i%dk)&&array[j]>temp;j-=dk)//比较与记录后移同时进行
array[j+dk]=array[j];
if(j!=i-dk)
array[j+dk]=temp;//插入
}
}
5.堆排序
算法思想:堆思想
图解:
代码:
/array是待调整的堆数组,i是待调整的数组元素的位置,nlength是数组的长度
//本函数功能是:根据数组array构建大根堆
void HeapAdjust(int array[],int i,int nLength)
{
int nChild;
int nTemp;
for(;2*i+1<nLength;i=nChild)
{
//子结点的位置=2*(父结点位置)+1
nChild=2*i+1;
//得到子结点中较大的结点
if(nChild<nLength-1&&array[nChild+1]>array[nChild])++nChild;
//如果较大的子结点大于父结点那么把较大的子结点往上移动,替换它的父结点
if(array[i]<array[nChild])
{
nTemp=array[i];
array[i]=array[nChild];
array[nChild]=nTemp;
}
else break; //否则退出循环
}
}














 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









