







 本文记录了一位初学者使用Python爬取熊猫直播用户信息的过程。最初尝试使用Scrapy框架,但发现直接处理返回的JSON串更简单。通过Httpfox工具抓取数据,发现获取数据的主要难点在于时间戳的生成。分享了初步的代码实现,但遇到使用format和range混合设置URL参数时的报错问题,期待读者的帮助。最后,作者将项目上传至GitHub,邀请大家关注其后续的直播爬虫系列。
本文记录了一位初学者使用Python爬取熊猫直播用户信息的过程。最初尝试使用Scrapy框架,但发现直接处理返回的JSON串更简单。通过Httpfox工具抓取数据,发现获取数据的主要难点在于时间戳的生成。分享了初步的代码实现,但遇到使用format和range混合设置URL参数时的报错问题,期待读者的帮助。最后,作者将项目上传至GitHub,邀请大家关注其后续的直播爬虫系列。
爬取国内各大直播平台直播信息是以后要做的一个功课,还必须是做成一个系列的,可能远没有其他大神那么厉害,毕竟自己经历过的就是有用的,在此做个记录一下
首先我们需要爬取的内容:
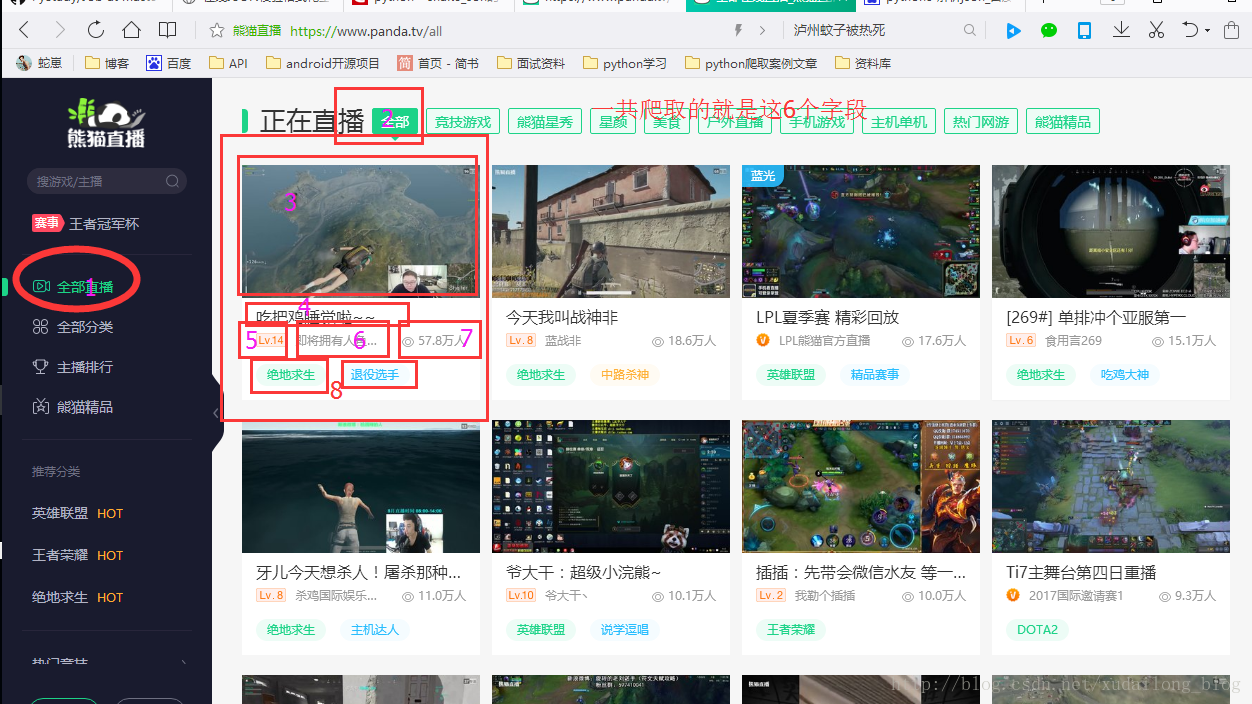
这里我们要爬取的有
直播房间名称,直播主播,直播等级,直播第一截屏(这个是动态的图片,要想获取最新的,必须重新进行爬取),直播人数,直播标签,直播类型(分类),暂且就提取了这些,这些内容都可以进行提取。
本来一开始是用scrapy框架进行提取的,也可以进行提取,后来发现有点大才了,直接找到返回的json 串就可以了 。
第一次使用Httpfox 感觉真吊,挺爽的,也不用一个一个的标签下面进行解析去了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









