







大家好,我是郝炎峰,目前负责新一代数字化企业云平台 “The Platform” 中的基础服务与数据相关领域系统的设计和开发,很荣幸有这次机会和大家分享交流,今天分享的主题是《DevOps之应用自动化发布与资源管理》。

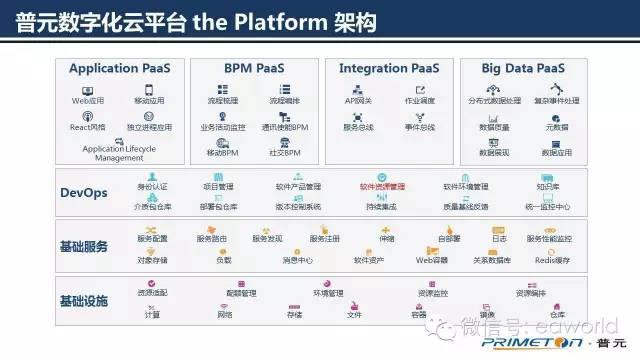
按照惯例,为了照顾新同学,我们先来看一张普元数字化企业云平台的整体架构图,图中的第四与第三层,分别是传统的IaaS基础设施和PaaS基础服务,这里的内容大家都耳熟能详了,不多说。
最上面第一层,是在传统的PaaS基础服务之上,再按技术领域进一步划分的各种类型的PaaS服务,如数据类、集成类、流程类以及多种常见的细分应用类型。
第二层的DevOps,则是基于IaaS与PaaS之上的一条用以打造顶层各种类型微应用的生产线,生产线中提供了各式工具,用以对产线中的应用进行全生命周期的管理。
SRM系统就属于DevOps生产线中的一个重要组件,下面我们将对SRM进行介绍和说明。

我们为什么需要SRM系统,它能解决什么问题?SRM系统的定义是啥?

传统应用开发过程中参与的各个角色均有很多痛点,比如:
· 开发人员功能开发和单元测试完成后,就不再喜欢写一些编译打包脚本,尤其是编写动辄上百页的投产流程文档想想都头疼。
· 测试人员通常会反复搭建多种测试环境,尤其是中间件产品的测试人员,要验证和维护各种操作系统、应用服务器、数据库排列组合出的环境,大量时间和精力都消耗在了搭环境上面。
· 运维人员更是无趣,长期通宵加班,朦胧的睡眼盯着开发写的投产流水账,无脑操作,健康状况每况愈下,连跳槽都没有面试的时间和精力。
· 管理者无法看到自己负责的领域和系统的进展和运行状态,只能日常听汇报,边听边猜汇报的内容是不是真的。实在心里没底又无处使力,只能逼着手下的人员继续写文档汇报。一百页不够!至少要写七百页!!!
这些事说起来好像是有些夸张,但实际每个对应角色中的人可能都会感受到以上部分痛点。遇到不情愿做的事请和无能为力的事情都不应该去妥协,应该想想怎么去改进,总想靠干几碗鸡汤,再坚持一下是无法进步的。实际上,在目前的技术背景下,以上这些大家不愿意干和干不了的烦心事,都是可以由计算机代劳的,而SRM系统,在DevOps平台中就是为解决这些痛点而设计的。

SRM系统的定义定义如下:
· SRM 是Software Resource Management的简称,即软件资源管理,在DevOps平台中负责提供软件产品发布与运行时资源管理能力。
· 作为DevOps平台中的中央枢纽型系统,依据产品规格编排部署流程,将持续继承CI、环境管理SEM等系统的能力进行组合封装,最终提供便捷的自动化编译、打包、部署服务,将繁杂的安装部署等重复手工劳动交给计算机完成,让工程师能够更专注于业务创新,工作更高效;让应用能够快速变更和发布,跟上互联网快速变化的节奏。
· 对于DevOps平台中已经部署的应用,SRM提供运行时的资源管理能力,系统内维护整个企业中软件资源与环境的关系。是运维人员进行资源管控的数据入口,也为管理者提供了整个企业的应用资源使用全景视图。

接下来,我们看一下SRM系统的设计思路。
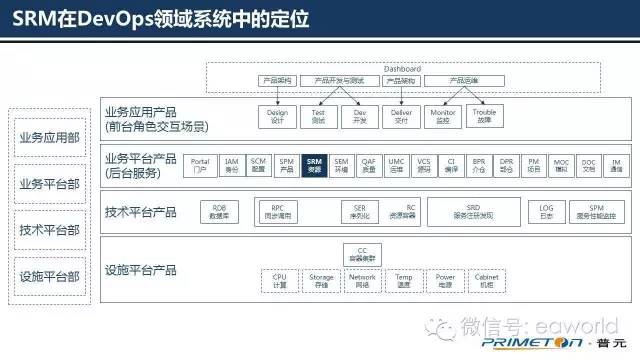
图中,蓝色部分就是SRM,属于DevOps后台服务中的一个领域系统。DevOps本身是采用微服务架构模式设计的,SRM就是其中的一个微服务。
在DevOps最初的规划中,SRM功能范围较窄,系统名称为Software。
Release Management即软件发布管理。后来经过讨论发现,只有发布管理是不够的,应用发布后的资源管理如果仅靠后端“软件环境管理系统SEM”中的K8S来处理的话,有些业务因素影响的应用版本切换、升级降级、伸缩等能力不太好做,这部分能力加到SEM中有些混乱。
因此最终确定SRM系统要既要管理软件的发布过程,又要对软件发布后的资源进行调度管控。最终系统名称变更为现在的Software
Resource Management。
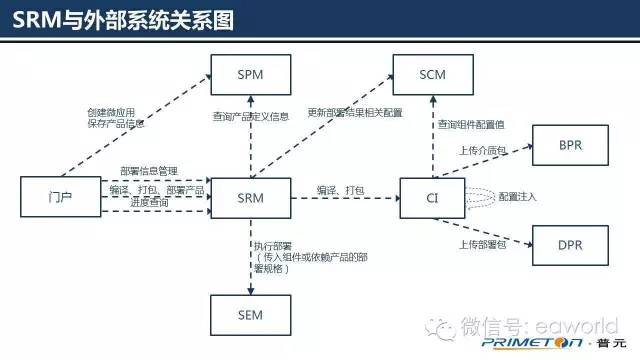
下面我们看一下SRM与外部系统的关系图与概念模型。
首先,先对外部关系图中的另外几个领域系统进行简单说明:
门户: DevOps Portal , 是平台提供给用户使用的统一操作门户,包括用户管理、产品看板、产品全生命周期(设计、开发、测试、预发、生产、监控、故障处理)管理等。
SPM:全称Software Product Management即软件产品管理,提供产品、组件的基准定义和管理能力,包括产品类型、产品管理、组件管理、依赖产品管理及产品投放市场等功能
SEM:全称Software Environment Management即软件环境管理,提供环境资源、负载均衡,以及运行容器的的创建、销毁、调度、复制以及持久化卷管理等能力;
SCM:全称Software Configuration Management即软件配置管理,提供产品、组件配置管理能力,包括配置项的定义和在各个环境下的配置信息的管理
CI:全称Continuous Integration即持续集成,提供持续集成任务调度和执行的能力,包括集成任务管理、编译、打包等
BPR:全称Binary Package Repository 即持二进制包仓库,提供二进制包仓库的管理能力,包括二进制包、文档等编译产物的上传、下载和存储访问等
DPR:全称Deployed Package Repository即部署包仓库,提供部署包仓库的管理能力,包括部署包的上传、下载和存储访问等
外部关系图说明:
1.SRM目前向DevOps门户开放了编译、打包、部署以及数据升级和初始化等功能服务;
2.SRM根据“软件产品管理系统SPM”中的产品与组件关系构造部署拓扑,之后根据部署拓扑生成调度流程;
3.调度流程中的不同活动分别协调其他领域系统完成对应的任务,如协调“持续集成系统CI”进行产品与组件的有序介质编译和镜像打包;协调“软件环境管理系统SEM”将打包好的镜像根据部署模型部署到运行容器环境中;
4.整个编译、打包、部署等过程均是异步的,门户可以通过进度查询服务轮询 操作进度。
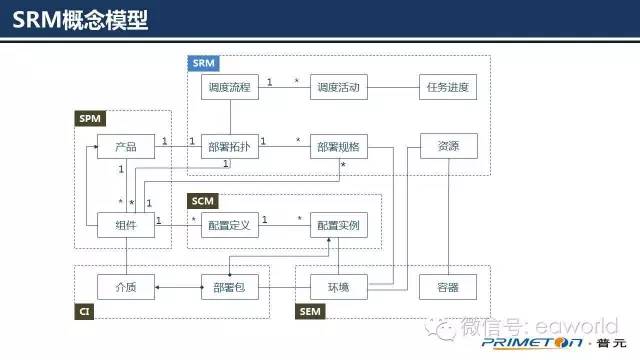
• 部署拓扑:针对产品规格定义中的描述的产品类别和组件依赖关系确定的组件编译和部署顺序。
• 部署规格:即一个组件支持的部署形态。通常在部署到特定环境时由用户选择指定,比如开发环境中组件部署单实例,生产环境部署多实例高可用集群。部署规格是在SRM系统上线时预置好的。
• 资源:产品与组件部署到运行环境之后即可称之为资源,软件程序成为资源即运行时可以对外提供服务或完成某些业务活动。


我们再看看SRM系统提供的能力与核心流程。
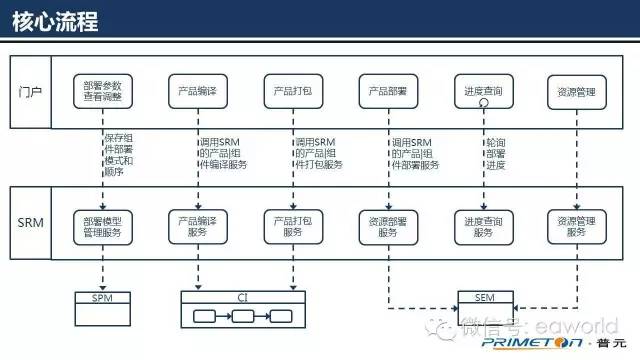
上图为目前SRM系统已经提供的核心能力流程图。
SRM系统主要为DevOps门户提供的服务,主要能力包括:部署参数调整、编译、打包、部署、进度查询以及资源管理。
后续将分别对几个主要的动作进行流程细化说明:
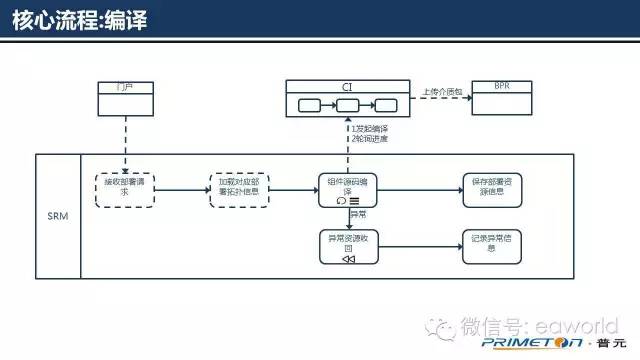
上图为SRM系统中的编译流程,收到门户发起的编译请求后,SRM会加载产品与组件的依赖顺序信息,这部分信息一般存储在部署拓扑数据结构中。
获取到部署拓扑后,根据组件的依赖逆序向“持续集成系统CI”发起编译请求,CI执行编译的过程中,SRM会以定时轮询的方式,像CI查询进度并提供给门户展示。CI编译成功后会将介质包上传到介质仓库(nexus)中。
图中的异常资源回收目前在编译过程中没有对应的实现动作,在编译失败后,只会记录异常信息并反馈给门户。
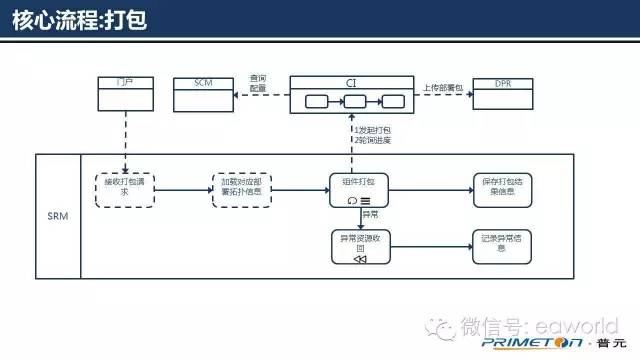
上图为SRM系统中的打包流程,收到门户发起的打包请求后,SRM会加载产品与组件部署拓扑数据。然后根据组件的依赖逆序向“持续集成系统CI”发起打包请求,CI执行打包的过程中,SRM会以定时轮询的方式,从CI查询进度并提供给门户展示。CI最终会将介质包打成镜像并上传到部署包仓库DPR中。
图中的异常资源回收目前在打包过程中没有具体的实现,在打包失败后,只会记录异常信息并反馈给门户。
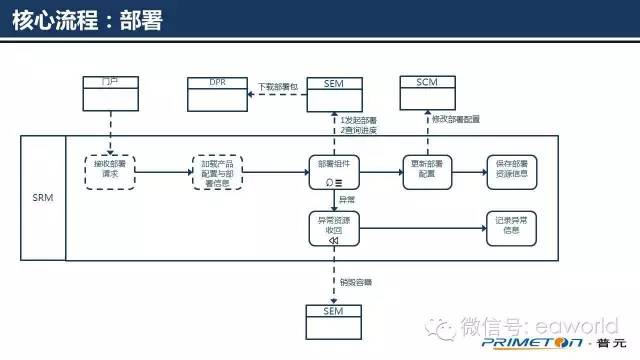
上图为SRM系统中的部署流程,收到部署请求后,SRM会加载产品与组件部署拓扑数据。然后根据组件的依赖逆序向“软件环境管理系统SEM”发起部署请求,对于单个组件部署,SRM将用户指定的部署规格传递到SEM系统中,SEM系统根据部署规格进行组件的部署,部署规格目前采用yaml文件格式描述,主要包含的内容包括镜像地址、部署类型、部署参数等数据。实际上SRM中的部署规格主要是对SEM系统内K8S的服务部署能力的体现。
部署动作同样也是异步执行的,SRM会有部署进度查询轮询操作。
部署成功后,可能会有一些输出的信息需要设置到“软件配置管理系统SCM”中,供其他组件使用。
当部署发生异常时,SRM的部署流程会调用SEM的服务销毁能力,将之前成功部署组件对应的容器全部销毁,并记录失败原因信息反馈到门户。
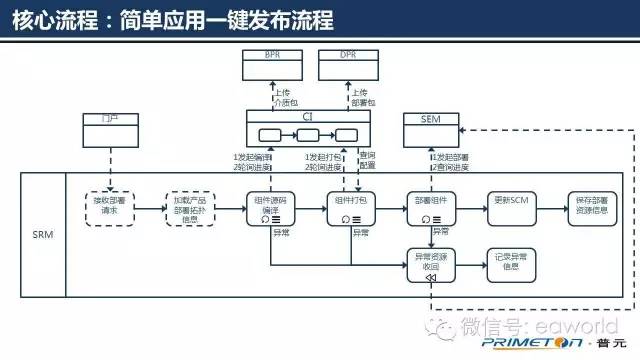
对于一些简单的微服务和组件,SRM可以提供一键发布的功能,流程参见上图,示例场景:当开发人员完成功能开发后,搭建集成开发环境时,到DevOps门户中点击一键发布按钮,就可以全自动的进行编译、打包和部署动作。这个一键发布流程对于某些特定类型应用的发布是非常便捷易用的。本质上还是由前面的几个原子流程操作的组合来实现。
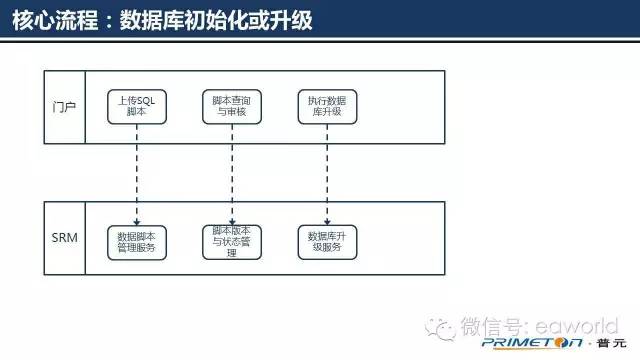
前面的核心流程中,编译、打包、部署都自动化了,肯定有人会觉得哪有那么简单,投产上线不是部署个程序包那么容易,数据库升级怎么办?
关于数据库初始化和升级我们的方案如下:
1.由开发人员上传数据库升级脚本到SRM进行保存和管理
2.部署前,DBA以及相关人员到门户中对数据库升级脚本进行审核,审核通过 后,更新脚本的状态为允许发布
3.部署前,运维人员在门户中执行审核通过的数据库脚本
4.数据库升级脚本存在不同的类别,如:初始化脚本、升级脚本、数据备份脚本 、数据恢复脚本 。
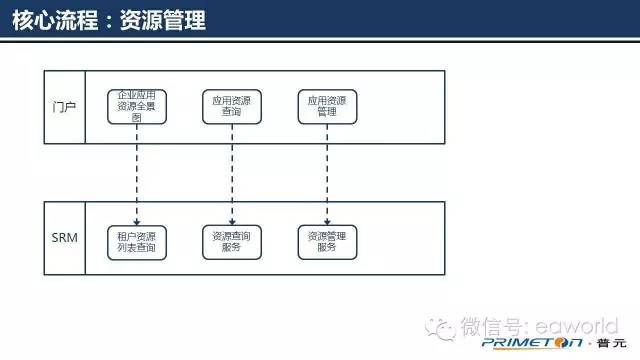
目前SRM的资源管理功能相对简单,当前版本中提供如下能力:
1.按租户查询应用资源信息
2.按产品或组件查询应用资源信息
3.资源管理操作,启动、停止、销毁、重启
后续版本中,对于运行时资源管理方面会进行加强。

关于SRM的后续规划,暂时想到的有如下几点:
•完善审批流程,对测试、预发、投产等几个重要环节通过审批流程进行控制。
•完善发布调度流程,实现应用版本切换、回退、灰度发布、定时割接等流程。
•逐步增加基于业务规则的资源伸缩能力,资源伸缩能力CaaS层的K8S已经提供,SRM需要在此基础上进行进一步的能力增强,提供业务规则的定义和执行能力。
场景如:双11前,对部分电商类应用进行扩容等。•提供部署编排工具,对产品的部署拓扑和部署规格进行编排与调整。
最后再来张上了DevOps(SRM)后的众生相,请大家感受一下:


敬请关注:
普元云计算专区:http://primeton.csdn.net/m/zone/primeton/index#
普元公众号:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









