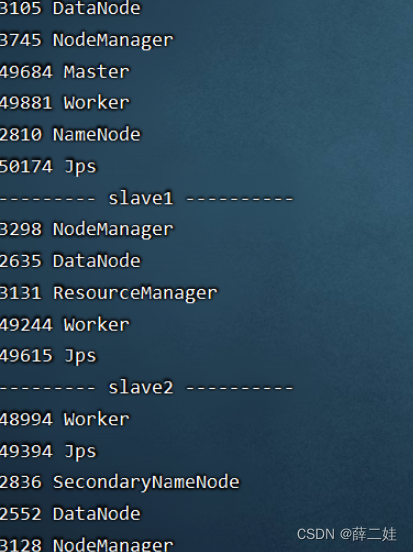
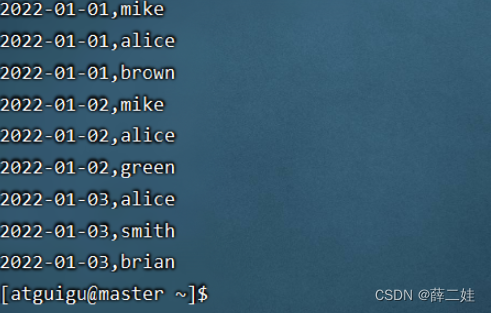
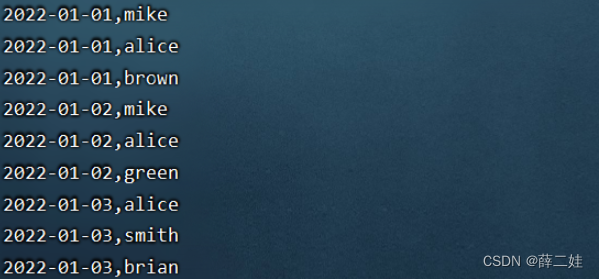
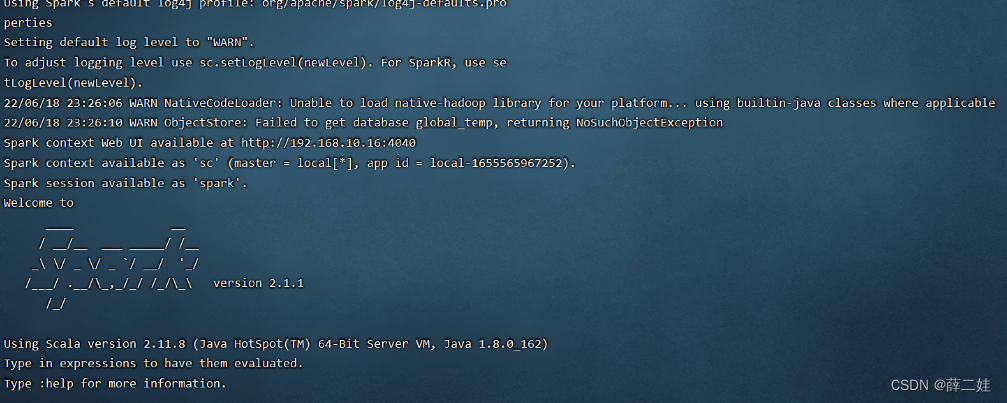
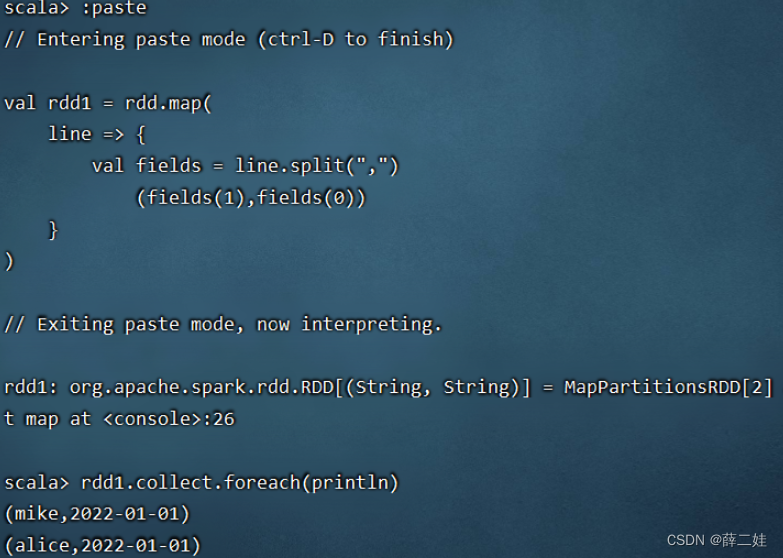
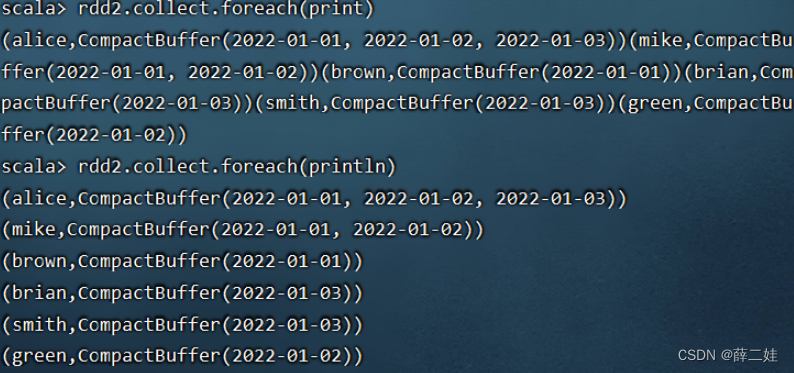
一、提出任务 已知有以下用户访问历史数据,第一列为用户访问网站的日期,第二列为用户名预备工作:启动集群的HDFS与Spark在虚拟机创建user.txt文件 将user.txt上传到HDFS/input目录下 执行spark-shell命令 二、完成任务 (一)读取文件,得到RDD 执行命令:val rdd = sc.textFile(“hdfs://master:9000/input/user.txt”) (二)倒排,互换RDD中元组的元素顺序 (三)倒排后的RDD按键分组 执行命令: rdd2.collect.foreach(println)






















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






