







冷启动问题(新产品,新用户)
一.推荐系统需要根据用户的历史行为和兴趣来预测用户未来的行为和兴趣,如何在没有大量用户数据的情况下设计个性化推荐系统并让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动问题。
二.分类:
- 用户冷启动:如何给新用户做个性化推荐
- 物品冷启动:如何将新物品推荐给可能对其感兴趣的用户。在新闻网站等时效性很强的网站中非常重要。
- 系统冷启动:如何在一个新开发的网站上设计个性化推荐,从而在网站刚发布时就让用户体验到个性化推荐服务。新网站没有用户,没有用户行为,只有一些物品信息。
三.解决办法
1.提供非个性化的推荐:
- 提供热门排行榜:最简单的就是给用户推荐热门排行榜,等到用户数据收集到一定的时候,再切换为个性化推荐;
- 推荐随机的热门内容:推荐随机的热门内容,再通过评估用户的点击来快速调整;
- 提供具有很高覆盖率的启动物品集合:在冷启动时,我们不知道用户的兴趣,而用户兴趣的可能性非常多,我们需要提供具有很高覆盖率的启动物品集合,这些物品能覆盖几乎所有主流的用户兴趣。
2.利用用户注册信息:
- 人口统计学信息:年龄、性别、职业、民族、学历和居住地等;
- 用户兴趣的描述:部分网站会让用户用文字来描述兴趣;
- 从其他网站导入的用户站外行为:比如用户利用社交网站账号登录,就可以在获得用户授权的情况下导入用户在该社交网站的部分行为数据和社交网络数据。
3.利用内容特征的相似度:
- 如果是要对一个新内容推荐相关的其他内容,那么可以多多利用内容特征的相似度。
稀疏性问题
现实生活中,电子商务推荐系统中用户和项目的数量是非常庞大的,而且随着时间的推移而越来越多。由此而言,用户对项目的评价数据也越来越多。但是对于如此庞大的项目数量,每个用户不可能对每个项目进行评价。据统计,一般用户购买商品的总数仅占网站商品总数的1%-2%,用户对项目的评价数据也是如此,造成用户——项目评价矩阵非常稀疏。显然,基于这样的稀疏矩阵计算得来的用户相似性是不准确的。
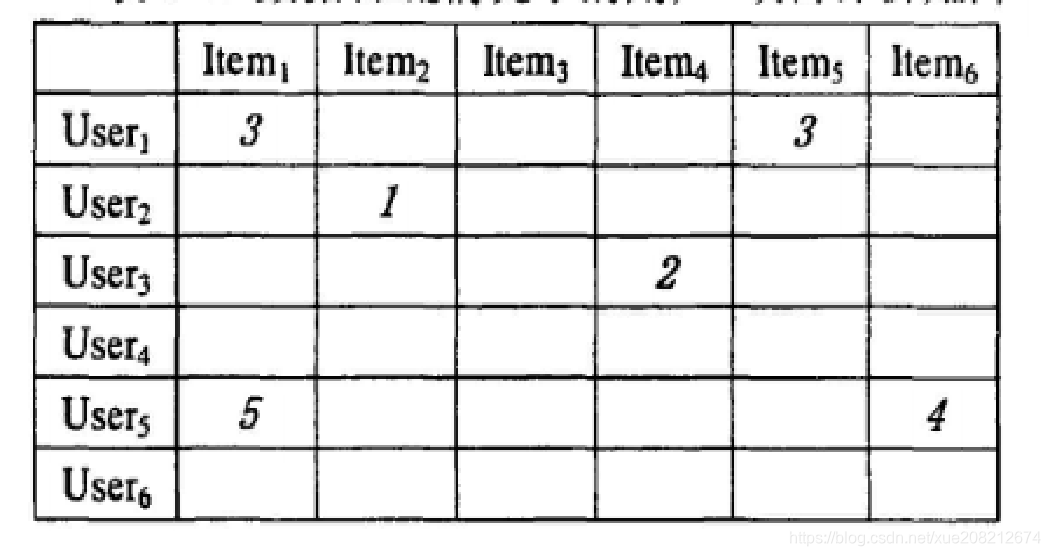
数据稀疏情况下用户-项目评价矩阵
数据稠密情况下用户-项目评价矩阵
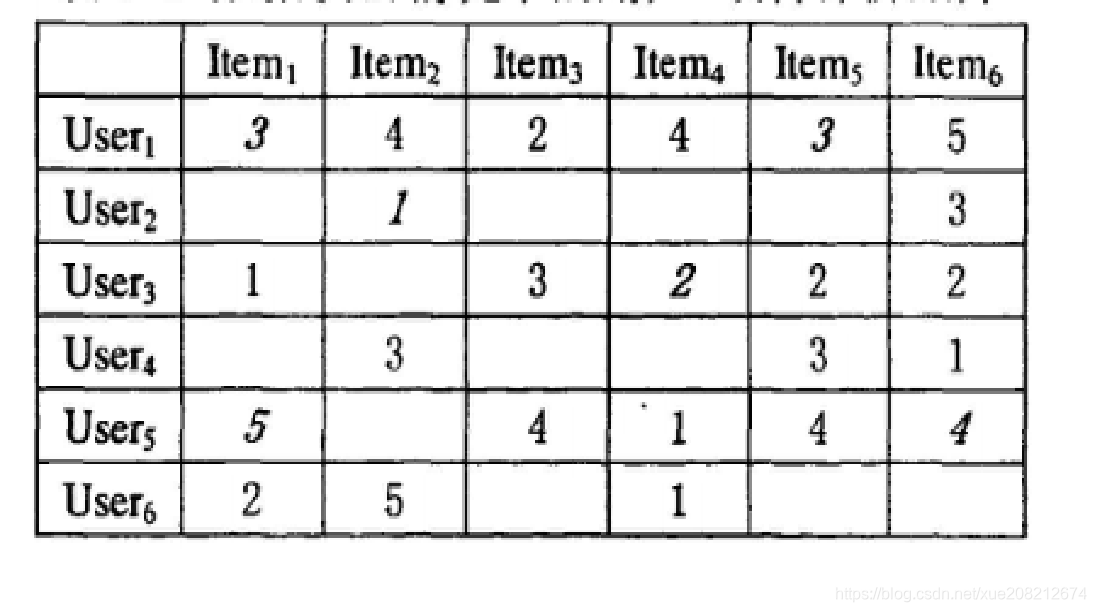
- 传统的协同过滤推荐算法是通过计算用户之间的相似性, 寻找与目标用户兴趣相似的一组用户, 作为目标用户的最近邻居。然而, 由于数据的极端稀疏性, 两个用户共同评分的产品非常少, 得到用户之间的相似性很有可能为 0。因此, 出现了基于项目的协同过滤推荐技术。
- 基于项目的协同过滤推荐算法 , 从产品角度进行分析, 寻找与目标产品相似的产品集合, 然后进行预测和推荐。它基于一个假设, 即用户对与其感兴趣产品相似的产品也感兴 趣。由于项目间的相似性相对稳定, 而通常项目的数量比用户数量少, 这样可以减少计算量, 降低数据稀疏性。
降低矩阵维数的技术
- 降低矩阵维数的技术可对原始稀疏数据直接进行数据处理, 降低数据稀疏性。
算法可扩展性(适应系统规模不断扩大的问题)
电子商务的不断快发展带动用户数量的不断增加,同时加入到电子商务网站中的项目数量也在成指数上升,因此也会加重推荐系统的计算负担。数据量一定的时候可能是高效的算法,但当数据量增加时不仅会出现计算时间的增加,同时对于推荐系统的准确度也会造成一定的影响。算法的扩展性问题是制约推荐系统发展的一个重要因素。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









