







1、dwd事实表
事务型快照事实表,每天一个分区,每天递增,di
周期型快照事实表,每天一个分区,每天全量,df
累积型快照事实表,每天一个分区,每天更新历史数据,每天全量,df
insert overwrite table dwd_fact_coupon_use_df partition(dt)
select
if(new.id is null,old.id,new.id),
if(new.coupon_id is null,old.coupon_id,new.coupon_id),
if(new.user_id is null,old.user_id,new.user_id),
if(new.order_id is null,old.order_id,new.order_id),
if(new.coupon_status is null,old.coupon_status,new.coupon_status),
if(new.get_time is null,old.get_time,new.get_time),
if(new.using_time is null,old.using_time,new.using_time),
if(new.used_time is null,old.used_time,new.used_time),
date_format(if(new.get_time is null,old.get_time,new.get_time),'yyyy-MM-dd')
from
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from dwd_fact_coupon_use_df
where dt='2020-03-28'
)old
full outer join
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from ods_coupon_use
where dt='2020-03-29'
)new
on old.id=new.id;
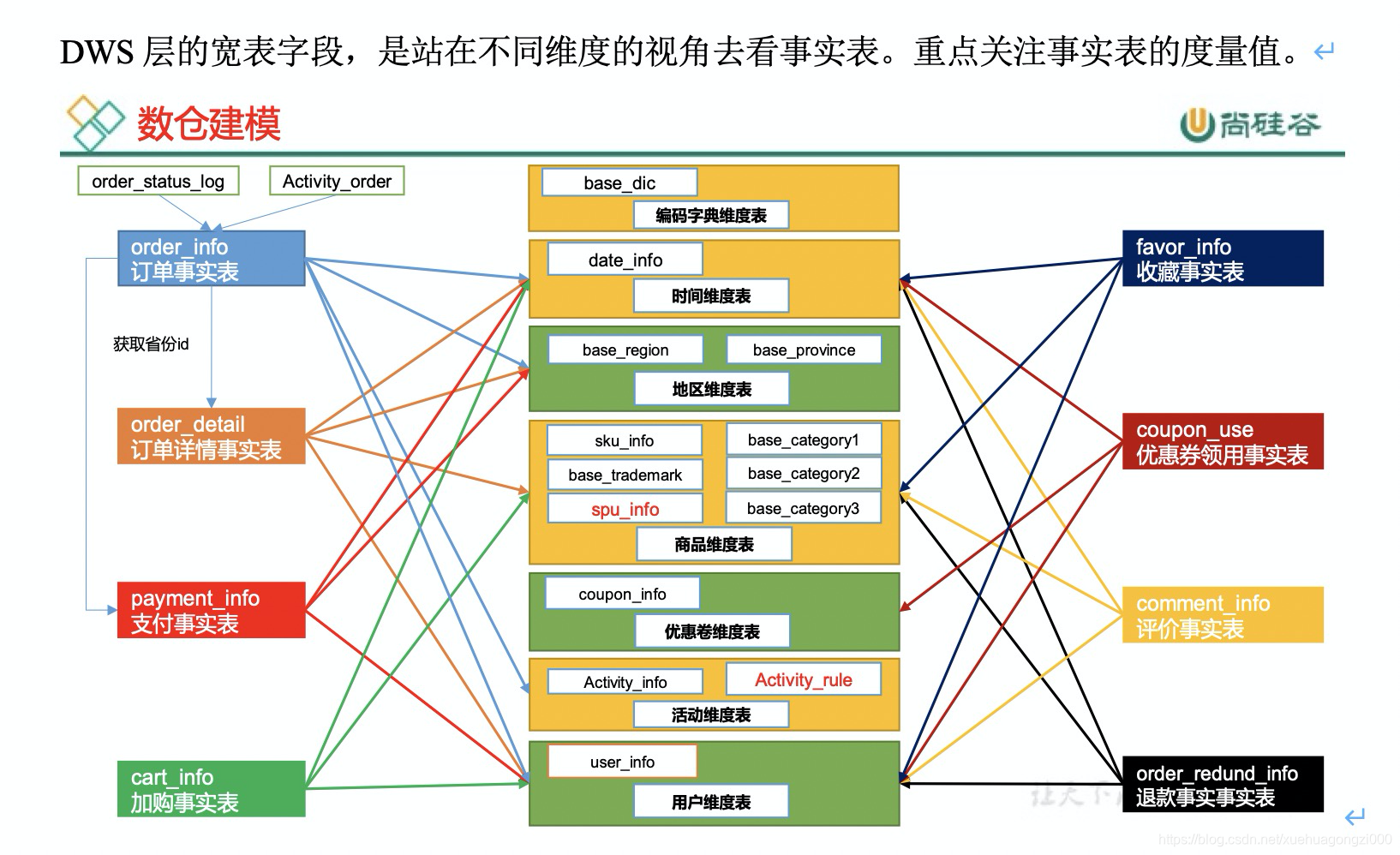
2、dws事实表
案例一:
create external table dws_sku_action_daycount
(
sku_id string comment 'sku_id',
order_count bigint comment '被下单次数',
order_num bigint comment '被下单件数',
order_amount decimal(16,2) comment '被下单金额',
payment_count bigint comment '被支付次数',
payment_num bigint comment '被支付件数',
payment_amount decimal(16,2) comment '被支付金额',
refund_count bigint comment '被退款次数',
refund_num bigint comment '被退款件数',
refund_amount decimal(16,2) comment '被退款金额',
cart_count bigint comment '被加入购物车次数',
cart_num bigint comment '被加入购物车件数',
favor_count bigint comment '被收藏次数',
appraise_good_count bigint comment '好评数',
appraise_mid_count bigint comment '中评数',
appraise_bad_count bigint comment '差评数',
appraise_default_count bigint comment '默认评价数'
) COMMENT '每日商品行为'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dws/dws_sku_action_daycount/'
tblproperties ("parquet.compression"="lzo");
with
tmp_order as
(
select
sku_id,
count(*) order_count,
sum(sku_num) order_num,
sum(total_amount) order_amount
from dwd_fact_order_detail
where dt='2020-03-29'
group by sku_id
),
tmp_refund as
(
select
sku_id,
count(*) refund_count,
sum(refund_num) refund_num,
sum(refund_amount) refund_amount
from dwd_fact_order_refund_info
where dt='2020-03-29'
group by sku_id
),
tmp_cart as
(
select
sku_id,
count(*) cart_count,
sum(sku_num) cart_num
from dwd_fact_cart_info
where dt='2020-03-29'
and date_format(create_time,'yyyy-MM-dd')='2020-03-29'
group by sku_id
),
tmp_favor as
(
select
sku_id,
count(*) favor_count
from dwd_fact_favor_info
where dt='2020-03-29'
and date_format(create_time,'yyyy-MM-dd')='2020-03-29'
group by sku_id
),
tmp_appraise as
(
select
sku_id,
sum(if(appraise='1201',1,0)) appraise_good_count,
sum(if(appraise='1202',1,0)) appraise_mid_count,
sum(if(appraise='1203',1,0)) appraise_bad_count,
sum(if(appraise='1204',1,0)) appraise_default_count
from dwd_fact_comment_info
where dt='2020-03-29'
group by sku_id
)
案例二:dws表不同视角形成的不同粒度的表


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









