HashMap的数据结构
哈希表-拉链法,我们可以理解为“链表的数组” ,如图:
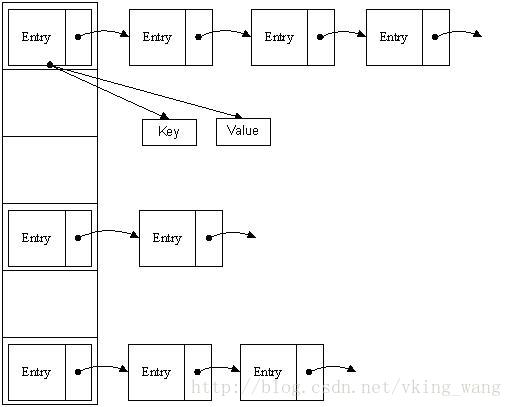
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next
HashMap的存取实现
初始:table初始大小是的2的初始容量次幂
public HashMap(
int initialCapacity,
float loadFactor) {
.....
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1; //左移代表乘2,右移代表除2
this.
loadFactor = loadFactor;
threshold = (
int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
put
public V put(K key, V value) {
if (key ==
null)
return putForNullKey(value);
//null总是放在数组的第一个链表中
int hash =
hash(key.hashCode());
int i =
indexFor(hash,
table.
length);//找到在数组中的位置
//遍历数组右侧链表
for (Entry<K,V> e =
table[i]; e !=
null; e = e.
next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.
hash == hash && ((k = e.
key) == key || key.equals(k))) {
V oldValue = e.
value;
e.
value = value;
e.recordAccess(
this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return
null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e =
table[bucketIndex];
table[bucketIndex] =
new Entry<K,V>(hash, key, value,
e);
//参数e, 是Entry.next
//如果table数组的size超过threshold,则扩充table大小。再散列
if (
size++ >=
threshold)
resize(2 *
table.
length);
}
HashMap里面设置一个因子,随着map的存储的size越来越大,Entry[]会以一定的规则加长长度。
get
public V get(Object key) {
if (key ==
null)
return getForNullKey();
int hash =
hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e =
table[
indexFor(hash,
table.
length)];
e !=
null;
e = e.
next) {
Object k;
if (e.
hash == hash && ((k = e.
key) == key || key.equals(k)))
return e.
value;
}
return
null;
}
null key的存取
null key总是存放在Entry[]数组的第一个元素。HashMap是泛型类,key和value可以为任何类型,包括null类型。key为null的键值对永远都放在以table[0]为头结点的链表中,当然不一定是存放在头结点table[0]中。
private V
putForNullKey(V value) {
for (Entry<K,V> e =
table[0]; e !=
null; e = e.
next) {
if (e.
key ==
null) {
V oldValue = e.
value;
e.
value = value;
e.recordAccess(
this);
return oldValue;
}
}
modCount++;
addEntry(0,
null, value, 0);
return
null;
}
private V
getForNullKey() {
for (Entry<K,V> e =
table[0]; e !=
null; e = e.
next) {
if (e.
key ==
null)
return e.
value;
}
return
null;
}
hashMap为什么存储2的n次幂个空间?
确定数组index:hashcode % table.length取模,HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标;算法如下:
/**
* Returns index for hashcode h.
*/
static
int
indexFor(
int
hashcode,
int length) {
return
hashcode
& (length-1);
}
只有全是1,
hashcode
进行按位与才是最均匀的
HashMap是根据key的hash值决定key放到哪个桶中,通过hash&(length-1)公式计算得出,2的n次方一定是最高位1其它低位是0,这样减1的时候才能得到01111这样都是1的二进制。这样(n - 1) & hash的值是均匀分布的,可以减少hash冲突。

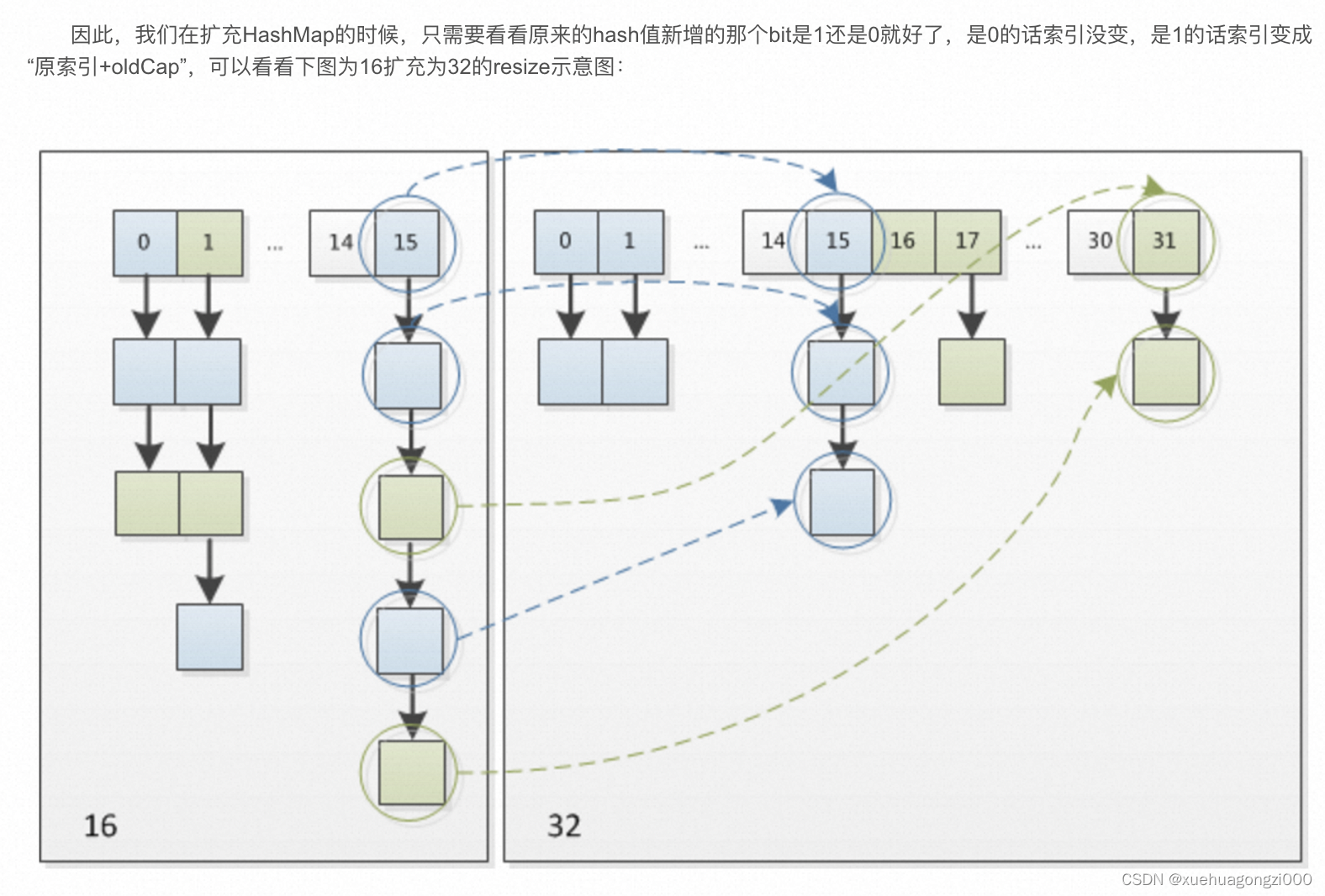
扩容
当hash数组中的元素个数超出了最大加载因子和容量的乘积时,要对hashMap进行扩容,扩容过程存在于hashmap的put方法中,
扩容过程始终以2次方增长
。
3. 解决hash冲突的办法
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
- 再哈希法
- 链地址法
- 建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
java8的性能改善
当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能
put方法
table变量:HashMap的底层数据结构,是Node类的实体数组,用于保存key-value对;
capacity:并不是一个成员变量,但却是一个必须要知道的概念,表示容量;
size变量:表示已存储的HashMap的key-value对的数量;
loadFactor变量:装载因子,用于衡量满的程度;
threshold变量:临界值,当超出该值时,表示table表示该扩容了;
threshold=capacity*loadFactor(默认是0.75)
当size>threshold则扩容
一. put方法
HashMap使用哈希算法得到数组中保存的位置,然后调用put方法将key-value对保存到table变量中。我们通过图来演示一下存储的过程。
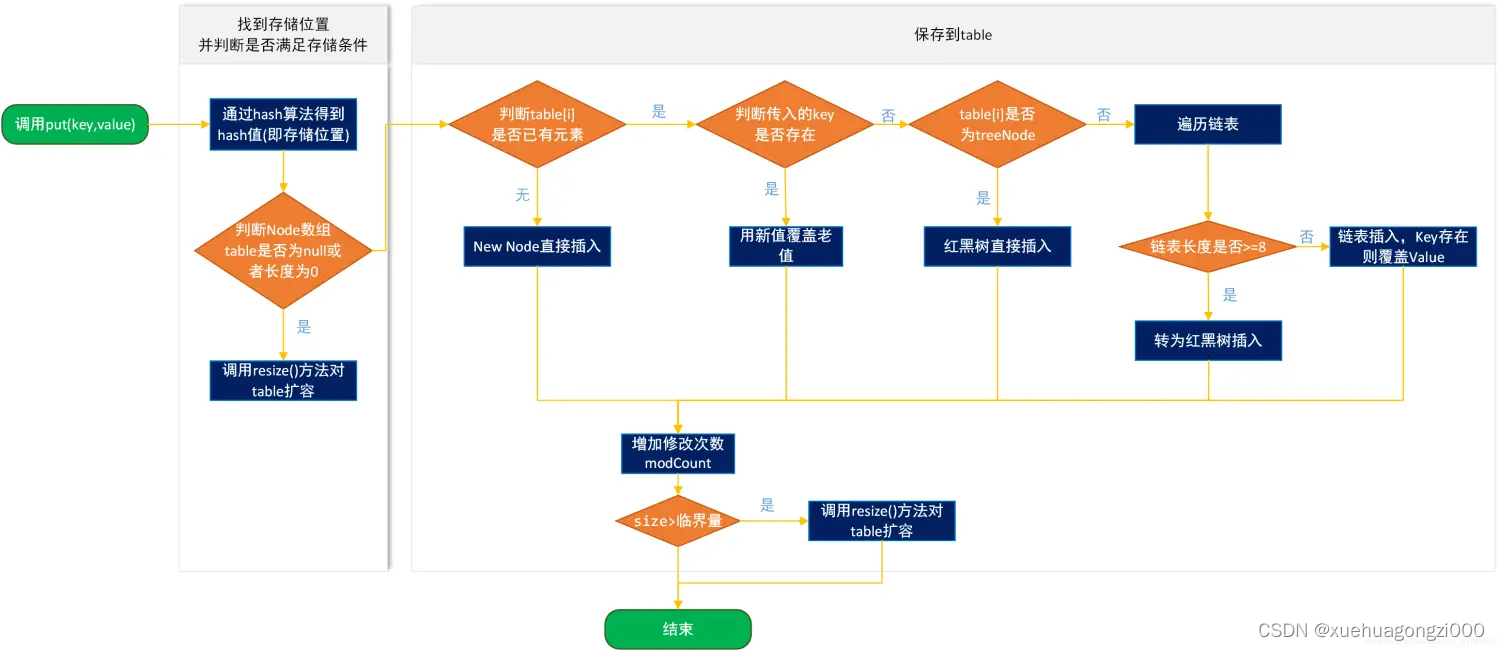
resize原理


hashmap线程不安全的会导致什么问题?
JDK1.7 HashMap线程不安全体现在:死循环、数据丢失
JDK1.8 HashMap线程不安全体现在:数据覆盖
HashMap为什么线程不安全-CSDN博客
























 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









