







声明:
1,本篇为个人对《2012.李航.统计学习方法.pdf》的学习总结,不得用作商用,欢迎转载,但请注明出处(即:本帖地址)。
2,由于本人在学习初始时有很多数学知识都已忘记,所以为了弄懂其中的内容查阅了很多资料,所以里面应该会有引用其他帖子的小部分内容,如果原作者看到可以私信我,我会将您的帖子的地址付到下面。
3,如果有内容错误或不准确欢迎大家指正。
4,如果能帮到你,那真是太好了。
描述
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,若这K个实例的多数属于某个类,就把输入实例分入这个类。
K值得选择
K值得选择会对K近邻算法的结果产生重大影响:
若K值较小:
预测结果会对近邻实例点十分敏感,若近邻点恰巧为噪声,那预测就会出错。
若K值较大:
优点是可减少估计误差,但近似误差会增大,因为与输入实例较远(不相似的)训练实例会起作用。
若K = N:
那无论输入什么,都将预为测训练实例中最多的那个类,不可取。
在应用中,K一般取一个较小的值,通常采用交叉验证法来选取最优的K值。
KD树
Kd树是存储K维空间数据的树结构。
PS:这里的K和K近邻算法的K意义不同。
1,KD树构造方法的描述:
a, 构造根节点,使根节点对应用于K维空间中包含所有实例点的超矩形区域。
b, 通过下面的递归方法,不断切分K维空间,生成子节点:
B.1,在超矩形区域上选择一个坐标轴和该坐标上中位数作为该坐标轴的切分点。
B.2,以经过该点且垂直于该坐标轴做一个超平面,该超平面将当前的超矩形区域切分成左右两个子区域(此时:2个子区域对应2个子节点,其父节点就是刚才的切分点)
c,该过程直到子区域内无实例时终止(终止时的节点为子节点)
在上述过程中将实例集合保存在相应的节点上。
2,例子:构造KD树
描述
输入:
K维空间数据集T = {x1,x2, …, xn},其中,xi = (xi(1), xi(2),…, xi(k)),i = 1, 2, …, n
输出:
KD树
解:
1, 构造根节点(根节点对应于包含T的K维空间的超矩形区域)
选择x(1)为坐标轴,以T中所有实例的x(1)坐标的中位数为切分点,这样,经过该切分点且垂直与x(1)的超平面就将超矩形区域切分成2个子区域。
而该切分点就是根节点。
2, 重复如下步骤直到两个子区域无实例时停止:
对深度为J的节点选择x(l)为切分的坐标轴,l = j(modk) + 1,以该节点区域中所有实例的x(l)坐标的中位数为切分点,将该节点对应的超平面切分成两个子区域。
而该切分点就是节点。
例子
题目:构造T={(2, 3),(5, 4), (9, 6), (4, 7), (8, 1), (7, 2)}的平衡KD树.
解:

1, 在X轴上选X坐标是所有点中位数的点:(7,2)
用经过(7, 2)且垂直于X轴的超平面(图中的①)将矩形区域切分成两部分,这时(7, 2)即为根节点
2, 因为上一步是在X轴上选中位数,所以(7,2)把T分成了两部分:
左节点:(2, 3) (4, 7) (5, 4)
右节点:(8, 1) (9, 6)
而上一步既然在X轴上选中位数,那这一步就以Y轴为标准在刚才的节点上选中位数。
于是左节点选取(5, 4)为中位数,那么就做经过(5,4)且垂直于Y轴的超平面②。
同理右节点选取(9, 6)为中位数,然后就做经过(9,6)且垂直于Y轴的超平面②。
这时(5, 4)和(9, 6)就是(7, 2)的左右节点:
(7,2)
/ \
(5, 4) (9, 6)
3, 同理,循环回X轴,以X轴为准为(5, 4)和(9, 6)的左右节点选取中位数,并将其作为(5, 4)和(9, 6)的子节点
4, 循环上面的步骤,直至无实例。(当然,对于本例在第三步时就有结果了)
5, 最后KD树如下:
(7,2)
/ \
(5, 4) (9, 6)
/ \ /
(2, 3)(4, 7)(8, 1)
使用KD树—用KD树做近邻搜索
描述
输入:
已知的KD树,目标点X
输出:
X的最近邻
解:
1, 在KD树中找出包含X的叶子节点
从根节点出发,递归向下访问KD树,若X小于节点坐标,则移动到左子节点,反之移动到右子节点,直到节点为叶子节点。
2, 以此叶子节点为“当前最近邻点”。
3, 递归向上回退,在每个节点上做以下操作:
A) 若该节点比刚才的“当前最近邻点”距离X更近,则更新此节点为“当前最近邻点”
B) “当前最近邻点”一定存在于该节点的一个子节点的对应区域。于是检查该子节点的父节点的另外一个节点对应的区域,看是否有更近的点。
即:
检查父节点的另一个节点对应的区域中是否与“以X为球心,以X与‘当前最近邻点’的距离为半径的超球体”相交。
C) 若相交:
可能在另一个子节点对应的区域内存在距离X更近的点,于是移动到另一个子节点,并递归的进行最近邻查找。
若不想交:
向上回退。
D) 当回退到根节点时,查找结束,最后的“当前最近邻点”就是X的最近邻点。
例子:
对下面的KD树,求S点的最近邻
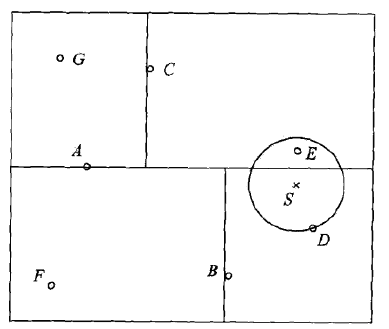
解:
1, 找到包含S的叶子节点D,以D作为“当前最近邻点”。
以S为圆心,S到D的距离为半径画圆。
2, 返回父节点B,在B的另一个子节点F的区域内做最近邻查找,而F的区域与圆不想交,所以不可能有最近邻点。
3, 继续返回上一级父节点A,在A的另一子节点C的区域内查找,发现该区域与圆相交。
4, 在该区域内遍历点,发现E点在圆内(比S到D更近)。
5, 更新E为“当前最近邻点”。
6, 重复上述过程直至返回根节点。
7, 最终得到点E为最近邻点。
时间复杂度
若实例点随机分布,则KD树搜索的时间复杂度为O(logN),N为训练实例数。
K近邻算法更适用于
KD树更适用于训练实例数远大于空间维度的K近邻搜索。
若空间维数接近训练实例数时,它的效率会迅速下降,几乎接近线性扫描。
代码示例:
<pre name="code" class="python">#-*-coding:utf-8-*-
# LANG=en_US.UTF-8
# k 近邻算法
# 文件名:k_nearest_neighbour.py
import sys
import math
list_T = [
( 2, 3 ),
( 5, 4 ),
( 9, 6 ),
( 4, 7 ),
( 8, 1 ),
( 7, 2 ),
]
# 二叉树结点
class BinaryTreeNode( object ):
def __init__( self, data=None, left=None, right=None, father=None ):
self.data = data
self.left = left
self.right = left
self.father = father
# 二叉树遍历
class BTree(object):
def __init__(self,root=0):
self.root = root
# 中序遍历
def inOrder(self,treenode):
if treenode is None:
return
self.inOrder(treenode.left)
print treenode.data
self.inOrder(treenode.right)
# 快速排序算法
# 1,取当前元素集的第一个元素为 key,i = 0,j = len(当前元素集)
# 2,j-- 直到找到小于 key 的元素,然后 L[i] 与 L[j] 交换
# 3,i++ 直到找到大于 key 的元素,然后 L[i] 与 L[j] 交换
# 4,当 i == j 时停止
# 5,L[i] = key
# 此时当前元素集被第 i 个元素分成了左右两部分,左边的都比 key 小,右边的都比 key 大
# 6,对左右两部分重复上面 5 步直到再无分割
def quick_sort( T, left, right, rank):
tmp_i = left
tmp_j = right
if left >= right:
return
key = T[left][rank]; key_item = T[left]
while tmp_i != tmp_j:
while tmp_i < tmp_j and T[tmp_j][rank] > key:
tmp_j -= 1
T[tmp_i] = T[tmp_j]
while tmp_i < tmp_j and T[tmp_i][rank] < key:
tmp_i += 1
T[tmp_j] = T[tmp_i]
T[tmp_i] = key_item
quick_sort( T, left, tmp_i-1, rank )
quick_sort( T, tmp_i+1, right, rank )
return T
# 制作 kd 树
# 原队列: [(2, 3), (5, 4), (9, 6), (4, 7), (8, 1), (7, 2)]
# 1,以x轴为基准排列 : [(2, 3), (4, 7), (5, 4), (7, 2), (8, 1), (9, 6)]
# 2,取中间的数为根,这时会产生左节点集和右节点集,即:经过(7, 2)的垂直于 x 轴的超平面 1 将整个矩形区域分成了左右两部分:
# (7, 2)
# / \
# / \
# / \
# [(2, 3), (4, 7), (5, 4)] [(8, 1), (9, 6)]
# 3,对左右子树集以 y 轴为基准排列:
# [(2, 3), (5, 4), (4, 7)] [(8, 1), (9, 6)]
# 4,取中间的数为父节点,这时会产生左节点集和右节点集,即:经过 (5, 4) 和 (9, 6) 的垂直于超平面 2 (或者说 y 轴)的超平面将上面的两个左右区域又分成了两部分
# (5, 4) (9, 6)
# / \ /
# / \ /
# (2, 3) (4, 7) (8, 1)
# 循环上面 4 步,直到没有结点。
# 最终 kd 树如下图所示:
# (7, 2)
# / \
# / \
# (5, 4) (9, 6)
# / \ /
# / \ /
# (2, 3) (4, 7) (8, 1)
def make_kd_tree( T ):
# 获取中间的数
def get_middle_item( _input ):
middle_item_num = len( _input ) / 2
middle_item = _input[middle_item_num]
return middle_item, middle_item_num
# kd 树的迭代函数
# 参数:二叉树的结点,上一步的结点集,当前迭代时结点集的最小序号,最大序号,秩
def iter_for_kd_tree( root, tmp_T, left, right, rank ):
# 根据 left 和 right 截取 tmp_T,tmp_T 为上一步的结点集,如:
# 在第一次迭代后,若当前循环的是左结点集,那 left = 0,right = middle_item_num
# 于是本次就是在 [(2, 3), (5, 4), (4, 7)] 这个结点集中选择中位点并继续了。
tmp_T = tmp_T[left: right]
# 若当前的结点集中已无节点,就返回 None
if len(tmp_T) == 0: return
# 若当前结点中只有一个元素,那就创建并返回用该元素创建的二叉树结点
if len(tmp_T) == 1:
return BinaryTreeNode( tmp_T[0] )
# 对当前的结点集以当前的秩为基准进行排列
quick_sort( tmp_T, 0, len(tmp_T)-1, rank )
# 更新秩,为下次排列做准a
rank = (rank + 1) % len(T[0])
# 获取当前结点集的中间元素和中间元素的坐标(该坐标用于将当前结点集分离成两部分)
middle_item, middle_item_num = get_middle_item( tmp_T )
# 使用该中间元素创建一个二叉树结点
root = BinaryTreeNode( middle_item )
# 将 "root 的左子结点,当前的结点集,左边结点集的最小坐标,左边结点集的最大坐标,秩" 传入本函数进行迭代
# 返回的结点保存到 root 的左子结点
root.left = iter_for_kd_tree( root.left, tmp_T, 0, middle_item_num, rank )
# root 的左子结点的父结点指向 root 自己
if root.left != None: root.left.father = root
# 同上,保存到 root 的右子结点
root.right = iter_for_kd_tree( root.right, tmp_T, middle_item_num+1, len(tmp_T), rank )
if root.right != None: root.right.father = root
# 返回根
return root
rank = 0 # 第一次在 x 轴上找中位点
return iter_for_kd_tree( BinaryTreeNode(), T, 0, len(T), rank )
# 使用 kd 树,进行 k 近邻算法
def use_kd_tree( T, root, target ):
# 得到两点间的距离
def get_distance( x, y ):
distance = (x[0] - y[0]) * (x[0] - y[0]) + (x[1] - y[1]) * (x[1] - y[1])
return math.sqrt( distance )
# 中序遍历 kd 树,得到包含 target 的叶子结点
def inOrder( node, rank ):
# 如果该结点没有左子结点和右子结点,那该结点就是叶子结点了
if not node.left and not node.right:
return node
# 保存当前的秩
tmp_rank = rank
# 更新秩
rank = (rank + 1) % len(T[0])
# 从根结点出发,如果目标点在当前秩的坐标 < node 在当前秩的坐标
if target[tmp_rank] <= node.data[tmp_rank]:
# 移动到左子结点
node = inOrder( node.left, rank )
else:
# 反之移动到右子结点
node = inOrder( node.right, rank )
return node
# 得到最近的点
def find_close_node( node, target, close_node ):
# 遍历到根结点就 ok 了
if not node.father: return
# 计算当前最近邻点距离
min_distance = get_distance( node.data, target )
# 计算 target 距离当前最邻近点的父节点的距离
new_distance = get_distance( node.father.data, target )
# 如果距离父节点更近
if min_distance >= new_distance:
min_distance = new_distance
# 将父节点保存成“当前最近邻点”
close_node = node.father.data
# 判断父节点的另外一个结点距离 target 是否更近,记得话将其保存成“当前最近邻点”
if node.father.left != node:
new_distance = get_distance( node.father.left.data, target )
if min_distance >= new_distance:
close_node = node.father.left.data
else:
new_distance = get_distance( node.father.right.data, target )
if min_distance >= new_distance:
close_node = node.father.right.data
find_close_node( node.father, target, close_node )
return close_node
rank = 0
node = inOrder( root, rank )
close_node = node.data
find_close_node( node, target, close_node )
return close_node
root = make_kd_tree( list_T )
target = (4, 3)
print use_kd_tree( list_T, root, target )
#bt = BTree( root )
#bt.inOrder( bt.root )















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









