






今日课堂内容:域套接字
TCP流式套接字
//服务器
#include <myhead.h>
int main(int argc, const char *argv[])
{
//1、为通信创建一个端点
int sfd = socket(AF_UNIX, SOCK_STREAM, 0);
//参数1:说明使用的是ipv4通信域
//参数2:说明使用的是TCP面向连接的通信方式
//参数3:由于参数2中已经指定通信方式,填0即可
if(sfd == -1)
{
perror("socket error");
return -1;
}
printf("socket success sfd = %d\n", sfd); //3
//判断要绑定的套接字文件是否存在?
if(access("./unix", F_OK) == 0)
{
//说明文件存在,要将其删除
if(unlink("./unix") ==-1)
{
perror("unlink error");
return -1;
}
}
//2、绑定ip和端口号
//2.1 准备地址信息结构体
struct sockaddr_un sun;
sun.sun_family = AF_UNIX; //通信域
strcpy(sun.sun_path , "./unix"); //套接字文件路径
//2.2 绑定工作:必须绑定一个不存在的套接字文件
if(bind(sfd, (struct sockaddr*)&sun, sizeof(sun)) ==-1)
{
perror("bind error");
return -1;
}
printf("bind success\n");
//3、将套接字设置成被动监听状态
if(listen(sfd, 128)==-1)
{
perror("listen error");
return -1;
}
printf("listen success\n");
//4、阻塞等待客户端的连接
//4.1 定义用于接受客户端信息的容器
struct sockaddr_un cun;
socklen_t addrlen = sizeof(cun);
int newfd = accept(sfd, (struct sockaddr*)&cun, &addrlen);
if(newfd == -1)
{
perror("accept error");
return -1;
}
printf("[%s]:发来连接请求\n", cun.sun_path);
//5、与客户端进行相互通信
char rbuf[128] = ""; //读取消息内容的容器
while(1)
{
//清空容器
bzero(rbuf, sizeof(rbuf));
//从套接字中读取数据
//int res = read(newfd, rbuf, sizeof(rbuf));
int res = recv(newfd, rbuf, sizeof(rbuf), 0);
if(res == 0)
{
printf("客户端已经下线\n");
break;
}
//将读取的消息展示出来
printf("[%s]:%s\n", cun.sun_path, rbuf);
//将收到的消息处理一下,回复给客户端
strcat(rbuf, "*_*");
//讲消息发送给客户端
//write(newfd, rbuf, strlen(rbuf));
send(newfd, rbuf, strlen(rbuf), 0);
printf("发送成功\n");
}
//6、关闭套接字
close(newfd);
close(sfd);
return 0;
}
//客户端
#include <myhead.h>
int main(int argc, const char *argv[])
{
//1、创建用于通信的套接字文件描述符
int cfd = socket(AF_UNIX, SOCK_STREAM, 0);
if(cfd == -1)
{
perror("socket error");
return -1;
}
printf("cfd = %d\n", cfd); //3
//判断要绑定的套接字文件是否存在?
if(access("./linux", F_OK) == 0)
{
//说明文件存在,要将其删除
if(unlink("./linux") ==-1)
{
perror("unlink error");
return -1;
}
}
//2、绑定IP地址和端口号 ?
//2.1 填充客户端地址信息结构体
struct sockaddr_un cun;
cun.sun_family = AF_UNIX;
strcpy(cun.sun_path, "./linux");
//2.2 绑定
if( bind(cfd, (struct sockaddr*)&cun, sizeof(cun)) ==-1)
{
perror("bind error");
return -1;
}
printf("bind success\n");
//3、连接服务器
//3.1 准备对端地址信息结构体
struct sockaddr_un sun;
sun.sun_family = AF_UNIX;
strcpy(sun.sun_path, "./unix");
//3.2 连接服务器
if(connect(cfd, (struct sockaddr*)&sun, sizeof(sun))==-1)
{
perror("connect error");
return -1;
}
printf("connect success\n");
//4、数据收发
char wbuf[128] = "";
char rbuf[128] = "";
while(1)
{
//从终端上获取要发送的数据
fgets(wbuf, sizeof(wbuf), stdin);
wbuf[strlen(wbuf)-1] = '\0'; //将读取的换行改成'\0'
//将数据发送给服务器
send(cfd, wbuf, strlen(wbuf), 0);
printf("发送成功\n");
//接收服务器发来的消息
bzero(rbuf, sizeof(rbuf));
recv(cfd, rbuf, sizeof(rbuf), 0);
printf("服务器发来的消息为:%s\n", rbuf);
}
//5、关闭套接字
close(cfd);
return 0;
}
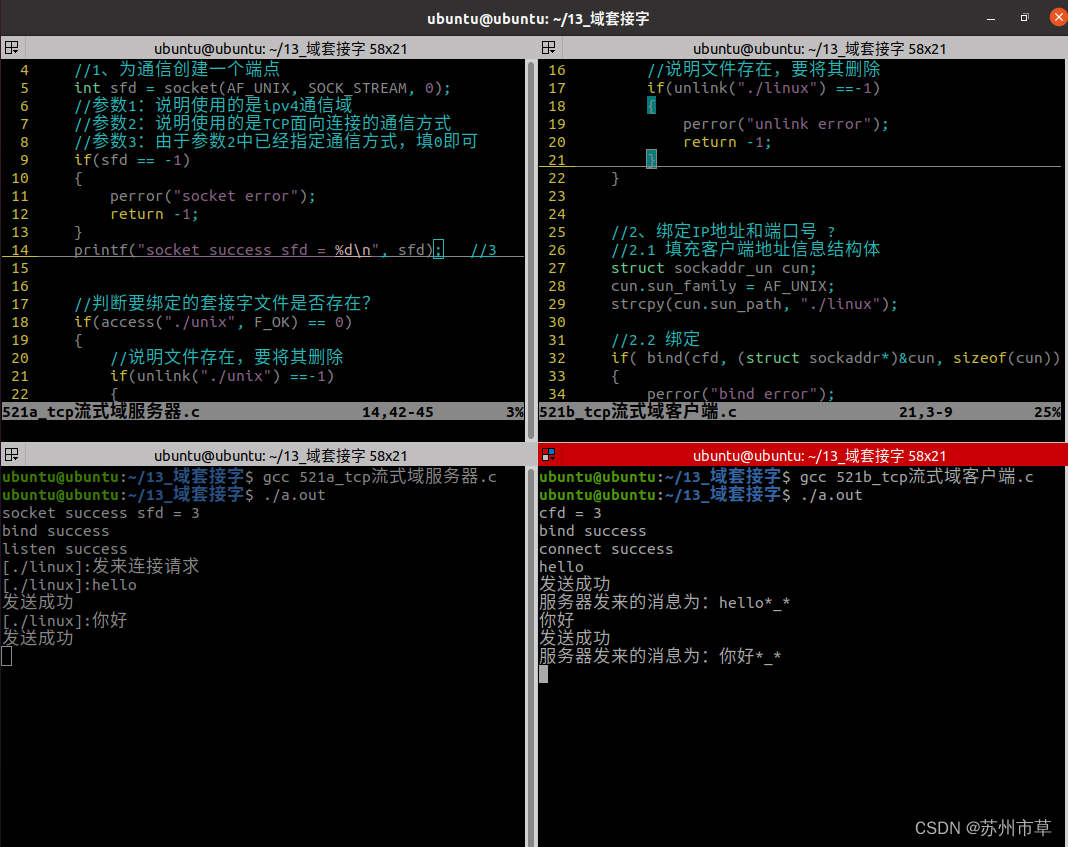
UDP报式套接字
//服务器
#include <myhead.h>
int main(int argc, const char *argv[])
{
//1、创建用于通信的套接字文件描述符
int sfd = socket(AF_UNIX, SOCK_DGRAM, 0);
if(sfd == -1)
{
perror("socket error");
return -1;
}
printf("sfd = %d\n", sfd); //3
//判断要绑定的套接字文件是否存在?
if(access("./unix", F_OK) == 0)
{
//说明文件存在,要将其删除
if(unlink("./unix") ==-1)
{
perror("unlink error");
return -1;
}
}
//2、绑定IP地址和端口号
//2.1 填充地址信息结构体
struct sockaddr_un sun;
sun.sun_family = AF_UNIX;
strcpy(sun.sun_path, "./unix");
//2.2 绑定
if(bind(sfd, (struct sockaddr*)&sun, sizeof(sun)) ==-1)
{
perror("bind error");
return -1;
}
printf("bind success\n");
//3、数据收发
char rbuf[128] = "";
//准备接受对端的地址信息
struct sockaddr_un cun;
socklen_t addrlen = sizeof(cun);
while(1)
{
//清空容器
bzero(rbuf,sizeof(rbuf));
//读取数据
//read(sfd, rbuf, sizeof(rbuf));
recvfrom(sfd, rbuf, sizeof(rbuf), 0, (struct sockaddr*)&cun, &addrlen);
printf("[%s]:%s\n", cun.sun_path, rbuf);
//将收到的消息,加个笑脸回过去
strcat(rbuf, "*_*");
//if(write(sfd, rbuf, strlen(rbuf))==-1)
if(sendto(sfd, rbuf, strlen(rbuf), 0, (struct sockaddr*)&cun, sizeof(cun))==-1)
{
perror("write error");
return -1;
}
printf("发送成功\n");
}
//4、关闭套接字
close(sfd);
return 0;
}
//客户端
#include <myhead.h>
int main(int argc, const char *argv[])
{
//1、创建用于通信的套接字文件描述符
int cfd = socket(AF_UNIX, SOCK_DGRAM, 0);
if(cfd == -1)
{
perror("socket error");
return -1;
}
printf("cfd = %d\n", cfd); //3
//2、绑定套接字文件
//2.1 填充地址信息结构体
struct sockaddr_un cun;
cun.sun_family = AF_UNIX;
strcpy(cun.sun_path, "./linux");
//判断要绑定的套接字文件是否存在?
if(access("./linux", F_OK) == 0)
{
//说明文件存在,要将其删除
if(unlink("./linux") ==-1)
{
perror("unlink error");
return -1;
}
}
//2.2 绑定
if(bind(cfd, (struct sockaddr*)&cun, sizeof(cun)) ==-1)
{
perror("bind error");
return -1;
}
printf("bind success\n");
//3、数据收发
char wbuf[128] = "";
//填充服务器的地址信息结构体
struct sockaddr_un sun;
sun.sun_family = AF_UNIX;
strcpy(sun.sun_path, "./unix");
char rbuf[128] = "";
while(1)
{
//清空容器
bzero(wbuf,sizeof(wbuf));
bzero(rbuf, sizeof(rbuf));
//从终端上获取信息
fgets(wbuf, sizeof(wbuf), stdin);
wbuf[strlen(wbuf)-1] = 0;
//讲消息发送给服务器
sendto(cfd, wbuf, strlen(wbuf), 0, (struct sockaddr*)&sun, sizeof(sun));
printf("发送成功\n");
//接受服务器发来的消息
recvfrom(cfd, rbuf, sizeof(rbuf), 0,NULL, NULL);
printf("收到服务器消息为:%s\n", rbuf);
}
//4、关闭套接字
close(cfd);
return 0;
}
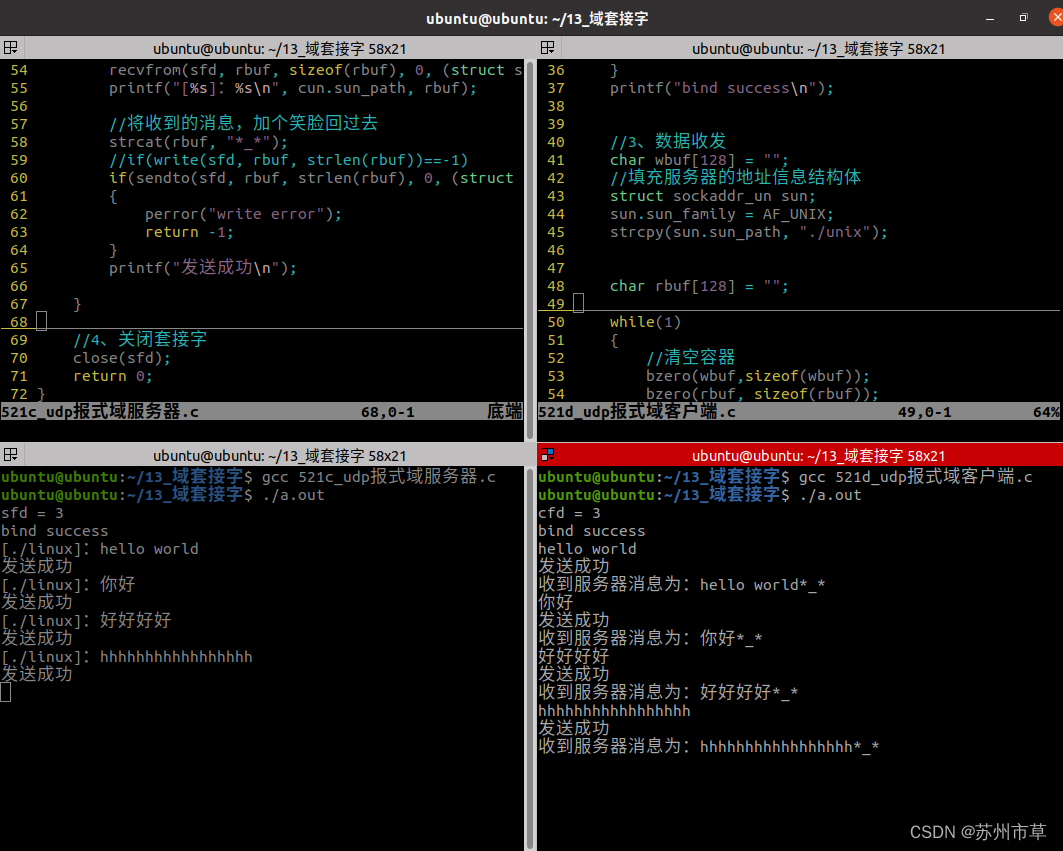
项目作业:
#include <myhead.h>
#define SER_PORT 69
void download(int fd,struct sockaddr_in sin);
void upload(int fd,struct sockaddr_in sin);
int main(int argc, const char *argv[])
{
/*1.判断终端输入 */
if(argc !=2 ){
printf("ip未输入\n");
exit(-1);
}
/*2. 创建套接字 */
int fd;
if((fd=socket(AF_INET,SOCK_DGRAM,0))<0){
perror("socket");
exit(1);
}
/*3. 向结构体中录入服务器信息 */
struct sockaddr_in sin;
sin.sin_family=AF_INET;
sin.sin_port=htons(SER_PORT);
sin.sin_addr.s_addr=inet_addr(argv[1]);
/*4. 功能实现 */
while(1){
/*4.1 打印提示表 */
printf("**********************\n");
printf("********1.下载********\n");
printf("********2.上传********\n");
printf("********3.退出********\n");
printf("**********************\n");
/*4.2. 文件传输 */
int S_opcode=0;
scanf("%d",&S_opcode);
while(getchar()!=10);
switch (S_opcode){
/*7.1 下载文件 */
case 1:
download(fd,sin);
break;
/*7.2 上传文件 */
case 2:
upload(fd,sin);
break;
case 3:
goto _EXIT;
break;
default:
printf("输入不正确\n");
break;
}
}
/*5. 退出 */
_EXIT:
close(fd);
return 0;
}
/* 下载 */
void download(int fd,struct sockaddr_in sin){
int num=1;
int flag=0;
int wpid=-1;
char Rsever_buf[516]={0};
/*1. 与服务端进行数据传输 */
/*1.1 初始化 */
char Wsever_buf[516]="";//写入服务端的字符串
/*1.2 第一次数据建立准备 */
/*1.2.1 文件操作码选择 */
short *opcode=(short *)Wsever_buf;
*opcode=htons(1);
/*1.2.2 文件名传输 */
char *filename=Wsever_buf+2;
printf("请输入文件名:");
char filestr[32]="";
fgets(filestr,32,stdin);
filestr[strlen(filestr)-1]=0;
strcpy(filename,filestr);
/*1.2.3 传输模式 */
char *mode=filename+strlen(filename)+1;
strcpy(mode,"octet");
/*1.2.4 数据大小统计 */
int size=2+strlen(filename)+strlen(mode)+2;
/*2. 第一次读写请求传输 */
if(sendto(fd,Wsever_buf,size,0,(struct sockaddr *)&sin,sizeof(sin))<0){
perror("sendto");
exit(-1);
}
while(1){
/*3. 读取服务端数据包 */
bzero(Rsever_buf,sizeof(Rsever_buf));
socklen_t addrlen=sizeof(sin);
ssize_t recv_len=-1;
if((recv_len=recvfrom(fd,Rsever_buf,sizeof(Rsever_buf),0,(struct sockaddr *)&sin,&addrlen))<0){
perror("recvfrom");
exit(-1);
}
/*3. 判断操作码及编号 */
short *r_opcode =(short *)Rsever_buf;
short *r_num=r_opcode+1;
switch (htons(*r_opcode)){
/*3.1 正确数据包处理*/
case 3:
if(*r_num==htons(num)){
printf("正在下载中\n");
num++;
break;
}
else{
printf("数据包编号错误\n");
exit(-1);
}
/*3.2 错误数据包提示 */
case 5:
if(0==htons(*r_num)){
printf("未定义,差错错误信息\n");
return;
}else if(1==htons(*r_num)){
printf("File not found\n");
return;
}else if(2==htons(*r_num)){
printf("Access violation\n");
return;
}else if(3==htons(*r_num)){
printf("Disk full or allocation exceeded\n");
return;
}else if(4==htons(*r_num)){
printf("illegal TFTP operation\n");
return;
}else if(5==htons(*r_num)){
printf("Unknown transfer ID\n");
return;
}else if(6==htons(*r_num)){
printf("File already exists\n");
return;
}else if(7==htons(*r_num)){
printf("No such user\n");
return;
}else if(8==htons(*r_num)){
printf("Unsupported option(s) requested\n");
return;
}
break;
default:
break;
}
/*4. 打开文件 */
if(0==flag){
wpid=open(filename,O_WRONLY | O_CREAT |O_TRUNC,0666);
if(wpid<0){
perror("open");
exit(-1);
}
flag=1;
}
/*5. 写入文件 */
if(write(wpid,Rsever_buf+4,recv_len-4)<0){
printf("%s\n",Wsever_buf+4);
perror("write");
break;
}
/*6. ACK确认回馈 */
char ACK[4]={0};
short *w_opcode=(short *)ACK;
*w_opcode=htons(4);
short *w_num=w_opcode+1;
*w_num=*r_num;
/*7. 传输ACK确认包 */
if(sendto(fd,ACK,4,0,(struct sockaddr *)&sin,sizeof(sin))<0){
perror("sendto");
exit(-1);
}
/*8. 判断文件是否下载结束 */
if(recv_len<516){
printf("文件下载完成\n");
close(fd);
break;
}
}
}
/*上传*/
void upload(int fd,struct sockaddr_in sin){
int num=0;
int flag=0;
char Rsever_buf[516]={0};
/*1. 与服务端进行数据传输 */
/*1.1 初始化 */
char Wsever_buf[516]="";//写入服务端的字符串
/*1.2 第一次数据建立准备 */
/*1.2.1 文件操作码选择 */
short *opcode=(short *)Wsever_buf;
*opcode=htons(2);
/*1.2.2 文件名传输 */
char *filename=Wsever_buf+2;
printf("请输入文件名:");
char filestr[32]="";
fgets(filestr,32,stdin);
filestr[strlen(filestr)-1]=0;
strcpy(filename,filestr);
/*1.2.2.1. 打开文件 */
int wpid=-1;
if((wpid=open(filename,O_RDONLY))<0){
printf("文件名不存在,请重新输入\n");
return;
}
/*1.2.3 传输模式 */
char *mode=filename+strlen(filename)+1;
strcpy(mode,"octet");
/*1.2.4 数据大小统计 */
int size=2+strlen(filename)+strlen(mode)+2;
/*2. 第一次读写请求传输 */
if(sendto(fd,Wsever_buf,size,0,(struct sockaddr *)&sin,sizeof(sin))<0){
perror("sendto");
exit(-1);
}
while(1){
/*3. 读取服务端数据包 */
bzero(Rsever_buf,sizeof(Rsever_buf));
socklen_t addrlen=sizeof(sin);
ssize_t recv_len=-1;
if((recv_len=recvfrom(fd,Rsever_buf,sizeof(Rsever_buf),0,(struct sockaddr *)&sin,&addrlen))<0){
perror("recvfrom");
exit(-1);
}
/*3. 判断操作码及编号 */
short *r_opcode =(short *)Rsever_buf;
short *r_num=r_opcode+1;
switch (htons(*r_opcode)){
/*3.1 正确数据包处理*/
case 4:
if(*r_num==htons(num)){
printf("正在上传中\n");
num++;
*r_num=htons(num);
break;
}
else{
printf("数据包编号错误\n");
break;
}
/*3.2 错误数据包提示 */
case 5:
if(0==htons(*r_num)){
printf("未定义,差错错误信息\n");
return;
}else if(1==htons(*r_num)){
printf("File not found\n");
return;
}else if(2==htons(*r_num)){
printf("Access violation\n");
return;
}else if(3==htons(*r_num)){
printf("Disk full or allocation exceeded\n");
return;
}else if(4==htons(*r_num)){
printf("illegal TFTP operation\n");
return;
}else if(5==htons(*r_num)){
printf("Unknown transfer ID\n");
return;
}else if(6==htons(*r_num)){
printf("File already exists\n");
return;
}else if(7==htons(*r_num)){
printf("No such user\n");
return;
}else if(8==htons(*r_num)){
printf("Unsupported option(s) requested\n");
return;
}
break;
default:
break;
}
/*4. 读取文件内容 */
int retval=-1;
if((retval=read(wpid,Rsever_buf+4,512))<0){
perror("read");
break;
}else if(0==retval){
printf("文件上传完毕\n");
return;
}
/*5. 文件上传 */
*r_opcode=htons(3);
if(sendto(fd,Rsever_buf,retval+4,0,(struct sockaddr *)&sin,sizeof(sin))<0){
perror("sendto");
return;
}
}
}
今日课堂提问:
1.项目中如何实现TCP的并发?
答:
在项目中实现 TCP 的并发通常涉及创建多个独立的执行流程来处理同时发起的多个 TCP 连接。常用的方法有以下几种:
1. **多进程**:服务端为每个新的客户端连接创建一个新的进程。这种方法的优点是简单易理解,每个进程独立运行,容错性好。但缺点是进程创建和切换的开销较大,不适合大量并发连接。
2. **多线程**:服务端为每个新的客户端连接创建一个新的线程。相比多进程,多线程的开销较小,因为线程间切换的成本低于进程间切换,共享资源的管理也比较方便。但多线程程序设计相对复杂,需要妥善处理同步和并发问题。
3. **I/O 多路复用**:通过选择性地阻塞在多个 I/O 上,例如使用 select、poll 或 epoll(在 Linux 上)等系统调用,服务器可以在单线程或少量线程中管理多个客户端连接。当某个 I/O 流准备好进行读写操作时,系统会通知服务器程序,从而进行相应的处理。
在实现 TCP 并发时,还需要考虑到负载均衡、资源管理、错误处理等问题,以确保服务器的稳定和性能。选择哪一种方法取决于具体的应用需求、性能要求和开发资源。
2.TCP通信过程中的三次握手?
答:
TCP的三次握手应用于建立连接:
第一次握手:客户端向服务器发送一个SYN包(同步包),其中包含客户端的初始序列号。此时,客户端进入SYN_SEND状态,等待服务器的确认。
第二次握手:服务器收到SYN包后,会确认客户端的SYN(通过发送一个ACK包,其中ack=客户端的序列号+1),同时服务器也会发送一个自己的SYN包,其中包含服务器的初始序列号。这个包通常被称为SYN+ACK包。此时,服务器进入SYN_RECV状态。
第三次握手:客户端收到服务器的SYN+ACK包后,会再次发送一个ACK包以确认收到服务器的SYN包(ack=服务器的序列号+1)。发送完这个ACK包后,客户端和服务器都进入ESTABLISHED状态,表示连接已建立成功。
简记:同步包→同步包+应答包→应答包
3.四次挥手的过程?
答:
TCP的四次挥手应用于释放连接,需要进行的四个步骤,具体步骤如下:
第一次挥手:当一方(假设为客户端)决定关闭连接时,它会发送一个FIN(Finish)报文段给对方。
第二次挥手:服务器收到FIN报文段后,会对这个FIN报文段进行确认,然后自己也发送一个ACK报文段。
第三次挥手:服务器在发送完ACK报文段后,会等待所有的数据传输完成,然后发送一个FIN报文。
第四次挥手:客户端收到服务器的FIN报文段后,会对其进行确认,并发送一个ACK报文段给服务器。
简记:FIN包→应答包→FIN包→应答包
4.tcp\IP协议分几层?tcp\IP是哪一层?
答:
TCP/IP 协议模型通常分为四层,这些层次分别是:
1. **网络接口层**:也称为链接层或网络访问层,它负责通过网络媒体发送和接收数据包,包括定义电缆的物理和电气标准。
2. **互联网层**:它主要负责数据包在网络中的传输,确保数据包能够跨越多个网络从源到达目的地。互联网协议(IP)就处在这一层。
3. **传输层**:这一层提供端到端的通信服务,确保数据的成功传输。TCP(传输控制协议)和 UDP(用户数据报协议)都处于这一层。
4. **应用层**:它负责处理特定的应用程序细节,提供了网络服务与最终用户应用程序之间的接口。例如,HTTP、FTP、SMTP 等协议都工作在这一层上。
从协议的名称“TCP/IP”来看,“TCP”指的是传输控制协议,位于传输层;“IP”指的是互联网协议,位于互联网层。因此,“TCP/IP”实际上涉及到模型中的两个不同层次:传输层和互联网层。
5.UDP为什么丢包,怎样处理?丢包发生在哪一层?为什么?
答:
UDP(用户数据报协议)丢包的原因包括:
1. **无连接性**:UDP 是一种无连接的协议,不像 TCP 那样在数据传输之前建立连接。这意味着UDP不保证可靠传输,数据包可能会在传输过程中丢失。
2. **无拥塞控制**:UDP 本身不进行拥塞控制。当网络拥塞时,UDP 继续以相同的速率发送数据包,这可能导致网络设备(如路由器)的缓冲区溢出,从而丢包。
3. **无序传输**:UDP 不保证数据包的顺序,所以数据包到达顺序可能与发送顺序不同,接收方需要处理可能的乱序问题。
4. **无错误校验重传机制**:TCP 有检验和及确认应答机制,并会重传损坏的数据包。而 UDP 只有基本的检验和功能,但不会重传损坏或丢失的数据包。
处理 UDP 丢包的方法包括:
- **应用层重传机制**:在需要可靠性的应用中,可以在应用层实现重传机制。如果在预定的时间内没有收到数据包的应答,发送方可以重发数据包。
- **序列号**:在数据包中引入序列号,以便接收方能够检测到丢包事件,并且能够将乱序到达的数据包重新排列成正确的顺序。
- **冗余数据**:使用前向错误校正(FEC)等技术,在传输数据中加入额外的冗余数据,这样即使某些数据包丢失,接收方也可能恢复出原始数据。
- **调节发送速率**:根据网络的实时状况调整数据的发送速率,避免因网络拥塞造成丢包。
- **使用其他协议**:对于需要高可靠性的应用,可以考虑使用更可靠的协议,如 TCP,或者更先进的协议,例如 QUIC。
- **应用选择重传(Selective Acknowledgment, SACK)**:这是一种在接收端告知发送端只重传丢失的数据包,而不是所有后续数据的机制。
丢包发生在网络层原因:
网络拥堵:当网络中的数据流量超过了网络设备(如路由器或交换机)的处理能力时,这些设备的缓冲区可能会满,导致无法继续接收新的数据包。当缓冲区满时,新到达的数据包将被丢弃。网络拥堵是导致丢包最常见的原因之一。
路由问题:数据包在网络层按照路由算法确定的路径从源头路由到目标。如果路由配置错误或是动态路由算法遇到问题,可能导致数据包被错误地发送到不存在或无法到达的目的地,从而导致丢包。
硬件故障:网络设备的物理损坏或故障也可能导致丢包。例如,路由器的接口损坏,导线问题,或其他硬件故障都可能阻止数据包的正确传输。
链路质量差:无线网络或长距离传输中的信号衰减、干扰、噪声等问题也是导致丢包的常见原因。在这些情况下,数据包在传输过程中可能会变得不完整或损坏,接收端设备无法正确解析这些数据包,导致丢包。
包过大:如果数据包的大小超过了网络中间设备的最大传输单元(MTU),而且数据包没有设定允许分片或者路径上的某个设备不支持分片,那么这个数据包会被丢弃。
安全策略:为了安全考虑,一些网络设备可能配置了包过滤或防火墙规则,用于阻止特定类型的流量。符合这些规则的数据包将被丢弃。
6.TCP是同步还是异步?谈谈你对同步异步的理解?
答:
TCP(传输控制协议)本身在底层是同步的,因为它需要建立连接,在发送方和接收方之间传输数据,并确认数据包已接收。TCP确保数据准确无误地从一个网络端点传递到另一个网络端点。
对于**同步**(Synchronous)来说,它通常指的是操作的发起者必须等待这个操作完成才能继续进行后续的操作。在同步操作中,任务按照它们发生的顺序依次执行,每个任务的完成是下一个任务开始的前提。例如,当你进行网络请求,在得到响应之前,程序将不会执行后续代码,这是同步操作的特点。
而**异步**(Asynchronous)操作则不同,异步意味着操作的发起者不必等待操作完成就可以继续执行后续的操作。在异步执行中,可以启动一个任务,并且在它完成之前就开始执行其他任务。当该任务完成时,程序会在适当的时间处理完成的操作。这种方式允许程序在等待长时间操作(如文件读写、网络请求等)的同时,继续执行其他代码,从而优化程序的整体性能。
系统中的同步和异步操作常常结合起来使用,以实现更高效、可靠的数据处理和通信。应用程序根据不同的需要,可能采用同步或异步模式来处理任务,或者结合使用二者的特点。例如,在一个TCP服务中,尽管TCP协议是同步的,但应用层可以采用异步编程模型来管理多个TCP连接,以提高系统的并发能力和性能。
7.什么是TCP的沾包现象,如何解决?
答:
TCP的粘包现象(sticky packets phenomenon)是指在使用TCP进行通信时,由于TCP是一个面向字节流的协议,它会将应用程序的数据看作一串无结构的字节流,数据包之间的界限并不是固定的。因此,当发送方连续快速发送多个较小的消息时,TCP可能将它们合并为一个较大的数据包来提高效率,同样,接收方也可能一次性读取并合并多个数据包。这就可能导致接收端不能确定每个数据包的边界,即发生粘包。
解决粘包问题一般有以下几种方法:
1. **消息定界**:为每个消息设置边界,如使用特殊的分隔符或序列来标识消息的开始和结束。接收方在接收数据时,根据这些定界符来分割原始字节流,从而恢复出独立的消息。
2. **固定长度**:每个消息都采用固定的长度,这样接收方就可以在接收到对应长度的数据后进行处理。
3. **消息长度字段**:在消息的开始处添加一个长度字段,这个长度字段指示了整个消息的长度,接收方首先读取长度字段,然后读取相应长度的数据作为一个消息。
4. **组合方法**:在消息开始处既指定消息的长度又包含一些结束符,确保接收方能准确无误地分割消息。
5. **应用层协议设计**:设计实用的应用层协议来处理消息的封包和解包。例如,HTTP、FTP等应用层协议都有自己的处理方式来防止粘包问题。
6. **利用现成的框架和库**:许多网络编程库(如Netty、asyncio等)提供了解决粘包问题的机制,无需手动处理粘包,只需要按库的规定编写逻辑即可。
在应用层实现这些策略可以避免TCP粘包现象,确保数据能够正确、完整地在客户端和服务器之间传输。
8.组播和广播的区别?
答:
组播(Multicast)和广播(Broadcast)是网络通信中用于发送消息给多个目的地的两种机制:
1. **广播**:
- 广播是一对所有的通信方式,其中一台主机发送的消息将传送给同一局域网(LAN)上的所有其他主机。
- 广播消息通常用在没有特定目标的情况下,例如,当新设备加入网络并寻址DHCP服务器以获取IP地址时,它会发送广播消息。
- 广播地址对于所有设备都是公开和可识别的,就像把信件扔进一个房间让每个人都能拿去阅读。
- 在广播中,网络中的每台设备即使对消息不感兴趣也会收到消息,这可能导致无用的网络流量和设备处理。
2. **组播**:
- 组播允许将消息同时发送给一组指定的目的地(即组播组中的主机)。只有加入该组的主机才会接收组播消息。
- 组播地址仅适用于那些已经表明愿意接收该特定组播组消息的设备。
- 组播有效地支持了多点传输,仅将消息传递给感兴趣的监听者,这样就减少了网络的拥堵和无效流量。
- 组播广泛用于流媒体、实时应用和网络服务中,例如视频会议和在线游戏,典型的例子有IGMP(Internet Group Management Protocol)和多播路由。
总结来说,广播是将消息发送给所有人,而组播是将消息仅发送给一组感兴趣的监听者。组播比广播更有效率,因为它减少了不必要的数据传输。
9.阻塞IO和非阻塞IO的区别?
答:
阻塞IO(Blocking IO)和非阻塞IO(Non-blocking IO)主要区别体现在程序如何等待IO操作完成:
1. **阻塞IO**:
- 在阻塞IO模型中,当一个IO操作(如读取或写入)开始时,如果数据没有准备好,程序会被挂起(即阻塞),直到数据准备好并且IO操作完成。
- 在数据准备阶段,程序做不了其他事情,它会等待在那里直到整个IO操作完全完成后才会继续执行。
- 阻塞IO简化了编程模型,因为在发起IO请求之后,你只需要等待结果,不必担心在这个过程中如何处理其他任务。
2. **非阻塞IO**:
- 非阻塞IO模型中,IO操作不会导致程序挂起等待。如果数据没有准备好,IO调用会立即返回一个指示数据尚未准备好的状态。
- 程序可以继续执行后续代码,它可以定期地检查IO操作是否可以进行,或者可以进行其他工作,这样很好地利用了等待时间。
- 非阻塞IO通常与事件驱动或轮询机制一起使用,程序可以在多个IO操作之间有效地切换,提高了程序的整体效率和响应性。
非阻塞IO更适用于处理高并发情况,尤其在需要同时管理多个连接或者进行多个并行IO操作时。但这种模型编程难度较高,因为要管理和调度多个IO操作,而且可能需要额外的机制(如IO复用或事件通知)来检测IO状态。
10.并发和并行的区别?
答:
并发(Concurrency)和并行(Parallelism)是计算机科学中两个关键概念,常常用来描述处理多个任务的能力,它们之间有着本质的区别:
1. **并发**:
- 并发是指一个处理单元(如CPU)在同一时间段内处理多个任务的能力。它更多地关注多任务的交错执行,即任务在单个核心上通过上下文切换实现多任务的“同时”处理。
- 并发不是真正的同时执行多个操作,而是从宏观角度看,使得每个任务都有机会按顺序执行,从而给用户一种多个任务同时处理的错觉。
- 并发更多地应用于任务处理的组织和调度上,常用于单核或多核处理器上的任务管理,以提高资源的使用效率和系统的响应速度。
2. **并行**:
- 并行是指多个处理单元(如多个CPU核心)同时执行多个任务或操作。在并行计算中,每个处理单元都在同一时刻独立地执行不同的任务,实现了真正的同时处理。
- 并行计算侧重于通过增加计算资源来增加计算速度,适用于有大量计算需要分割执行的场景,如大规模科学计算、图像处理等。
- 在多核和多处理器系统中,并行计算可以显著提高计算效率和处理速度,特别是对于可以明确分解和独立执行的任务。
简而言之,**并发是任务交错执行**(在单个核心上“同时”处理多个任务),**并行是多个核心同时执行任务**。并发的目的在于充分利用有限的计算资源以提高效率,而并行的目标是通过增加计算资源来减少计算时间。















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









