







我们前面费了那么大篇幅介绍堆和优先级队列,就是为了分析本文的7道题。而这7道题,
特别!特别!特别!
重要!重要!重要!
不过呢,正如我们前面说的,这些题目其实知道怎么处理就行,不必一定要写出来。
1.Leetcode23 合并K个排序链表

这个题我们前面曾经花了很大的篇幅来介绍,其中提到一句说可以使用优先级队列来做。原理是不管几个链表,最终都是按照顺序来的。如果使用优先级队列,每次都将剩余节点的最小值加到输出链表尾部,最后堆空的时候,合并也就完成了。
public ListNode mergeKLists(ListNode[] lists) {
if (lists == null || lists.length == 0) return null;
PriorityQueue<ListNode> q = new PriorityQueue<>(Comparator.comparing(node -> node.val));
for (int i = 0; i < lists.length; i++) {
if (lists[i] != null) {
q.add(lists[i]);
}
}
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
while (!q.isEmpty()) {
tail.next = q.poll();
tail = tail.next;
if (tail.next != null) {
q.add(tail.next);
}
}
return dummy.next;
}2.LeetCode239 滑动窗口最大值
类似题:剑指offer59

这个题其实就是每次框移动的时候,都输出框的最大值。框的大小就是堆的大小,滑动窗口移动的时候,堆就跟着调整元素,。
public int[] maxSlidingWindow(int[] nums, int k) {
if (nums == null || k <= 0) return new int[0];
int[] res = new int[nums.length - k + 1];
ArrayDeque<Integer> deque = new ArrayDeque<Integer>>();
int index = 0;
for (int i = 0; i < nums.length; i++) {
while (!deque.isEmpty()&& deque.peek()< i - k + 1) // Ensure deque's size doesn't exceed k
deque.poll();
// Remove numbers smaller than a[i] from right(a[i-1]) to left, to make the first number in the deque the largest one in the window
while (!deque.isEmpty() && nums[deque.peekLast()] < nums[i])
deque.pollLast();
deque.offer(i);// Offer the current index to the deque's tail
if (i >= k - 1)// Starts recording when i is big enough to make the window has k elements
res[index++] = nums[deque.peek()];
}
return res;
}3.leetcode 264 丑数II
也是剑指offer49题

使用最小堆,要得到从小到大的第 nn 个丑数,可以使用最小堆实现。
初始时堆为空。首先将最小的丑数 11 加入堆。
每次取出堆顶元素 xx,则 xx 是堆中最小的丑数,由于 2x, 3x, 5x2x,3x,5x 也是丑数,因此将 2x, 3x, 5x2x,3x,5x 加入堆。
上述做法会导致堆中出现重复元素的情况。为了避免重复元素,可以使用哈希集合去重,避免相同元素多次加入堆。
在排除重复元素的情况下,第 nn 次从最小堆中取出的元素即为第 nn 个丑数。
class Solution {
public int nthUglyNumber(int n) {
int[] factors = {2, 3, 5};
Set<Long> seen = new HashSet<Long>();
PriorityQueue<Long> heap = new PriorityQueue<Long>();
seen.add(1L);
heap.offer(1L);
int ugly = 0;
for (int i = 0; i < n; i++) {
long curr = heap.poll();
ugly = (int) curr;
for (int factor : factors) {
long next = curr * factor;
if (seen.add(next)) {
heap.offer(next);
}
}
}
return ugly;
}
}
4.LeetCode347 前K个高频元素

使用堆的思路与算法
首先遍历整个数组,并使用哈希表记录每个数字出现的次数,并形成一个「出现次数数组」。找出原数组的前 k 个高频元素,就相当于找出「出现次数数组」的前 k 大的值。
最简单的做法是给「出现次数数组」排序。但由于可能有O(N) 个不同的出现次数(其中 NN 为原数组长度),故总的算法复杂度会达到 O(NlogN),不满足题目的要求。
在这里,我们可以利用堆的思想:建立一个小顶堆,然后遍历「出现次数数组」:
如果堆的元素个数小于 k,就可以直接插入堆中。
如果堆的元素个数等于 k,则检查堆顶与当前出现次数的大小。如果堆顶更大,说明至少有 k 个数字的出现次数比当前值大,故舍弃当前值;否则,就弹出堆顶,并将当前值插入堆中。
遍历完成后,堆中的元素就代表了「出现次数数组」中前 k 大的值。
class Solution {
public int[] topKFrequent(int[] nums, int k) {
Map<Integer, Integer> occurrences = new HashMap<Integer, Integer>();
for (int num : nums) {
occurrences.put(num, occurrences.getOrDefault(num, 0) + 1);
}
// int[] 的第一个元素代表数组的值,第二个元素代表了该值出现的次数
PriorityQueue<int[]> queue = new PriorityQueue<int[]>(new Comparator<int[]>() {
public int compare(int[] m, int[] n) {
return m[1] - n[1];
}
});
for (Map.Entry<Integer, Integer> entry : occurrences.entrySet()) {
int num = entry.getKey(), count = entry.getValue();
if (queue.size() == k) {
if (queue.peek()[1] < count) {
queue.poll();
queue.offer(new int[]{num, count});
}
} else {
queue.offer(new int[]{num, count});
}
}
int[] ret = new int[k];
for (int i = 0; i < k; ++i) {
ret[i] = queue.poll()[0];
}
return ret;
}
}
5.LeetCode692 前K个高频单词
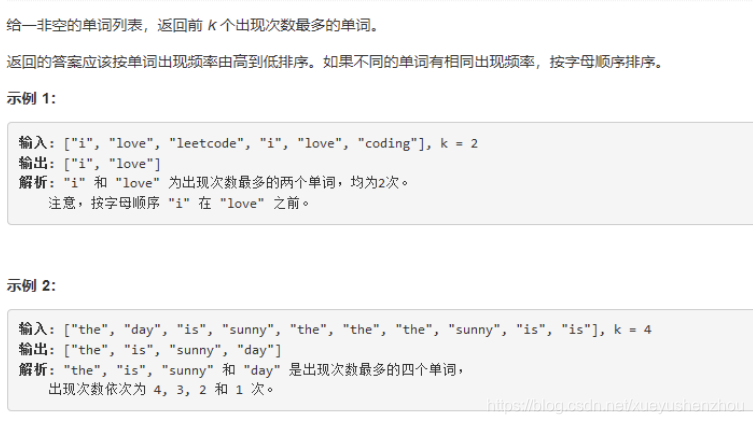
这个有点复杂,如果用小根堆解决问题的方法是:
先用哈希表统计单词的出现频率,然后因为题目要求前 K 大。所以构建一个 大小为 K 的小根堆按照上述规则自定义排序的比较器。然后依次将单词加入堆中,当堆中的单词个数超过 K 个后,我们需要弹出顶部最小的元素使得堆中始终保留 K 个元素,遍历完成后剩余的 K 个元素就是前 KK 大的。最后我们依次弹出堆中的 K 个元素加入到所求的结果集合中。
代码不写了















 1043
1043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











