







文章目录
一、实战概述
在信息爆炸的时代,数据处理与分析的重要性日益凸显。MapReduce作为一种强大的分布式计算模型,以其高效并行处理能力解决了大规模数据集的处理难题。本次实践教程,我们将通过一个具体的任务——学生信息排序,深入浅出地引导大家掌握MapReduce的基本原理和应用。从数据准备到实现步骤,再到拓展练习,我们将一起领略MapReduce的强大魅力,揭示其在大数据处理中的关键作用。
本教程将通过Hadoop MapReduce实现学生信息排序任务。首先,启动Hadoop服务,创建sortstudent目录和包含学生信息的student.txt文件,然后将其上传到HDFS的/sortstudent/input目录。接着,创建Maven项目SortStudent,添加hadoop和junit依赖,配置日志属性文件。在net.hw.mr包下创建Student类实现序列化比较接口,设置性别升序、年龄降序的比较规则。随后,创建StudentMapper和StudentReducer类进行数据处理和排序。在StudentDriver类中设置作业配置并运行。拓展练习中,我们将修改Student类的比较规则以实现性别升序、年龄降序排序,最后重新运行StudentDriver查看结果。
二、提出任务
学生表,包含五个字段(姓名、性别、年龄、手机、专业),有8条记录
三、准备数据
(一)、准备数据
1、在虚拟机上创建文本文件
在主目录下创建student.txt文件,执行命令
vim student.txt
并写入以下内容
李文丽 女 19 15892943440 大数据应用
张三丰 男 20 15890903456 人工智能应用
郑晓琳 女 18 18867890234 软件技术
唐宇航 男 22 15856577890 计算机应用
陈燕文 女 21 13956576783 软件技术
童安格 男 19 15889667890 大数据应用
肖雨涵 男 20 15857893452 软件技术
冯晓华 女 18 18856784560 大数据应用

2、上传文件到HDFS指定目录
创建/sortstudent/input目录,执行命令:
hdfs dfs -mkdir -p /sortstudent/input/

将文本文件student.txt上传到HDFS的/sortstudent/input目录
hdfs dfs student.txt -put /sortstudent/input/

(二)、实现步骤
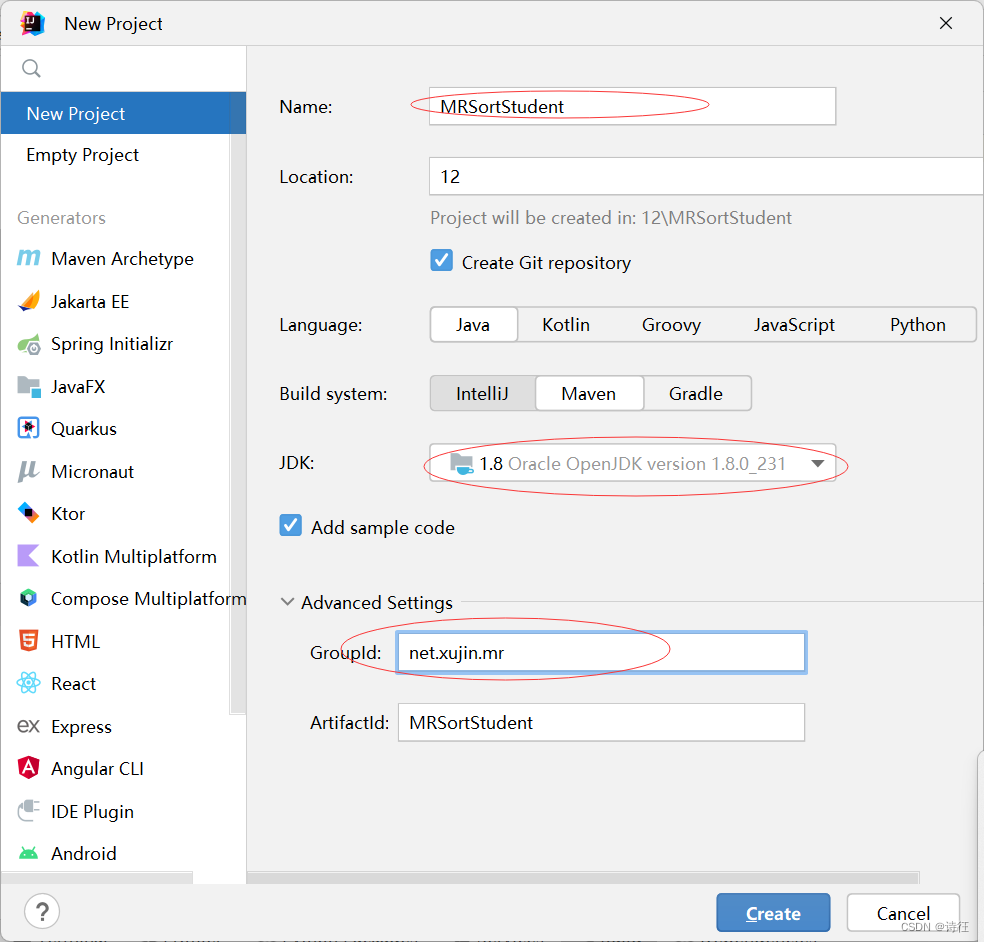
1、创建Maven项目
Maven项目 - MRSortStudent,设置了JDK版本 - 1.8,组标识 - net.xujin.mr

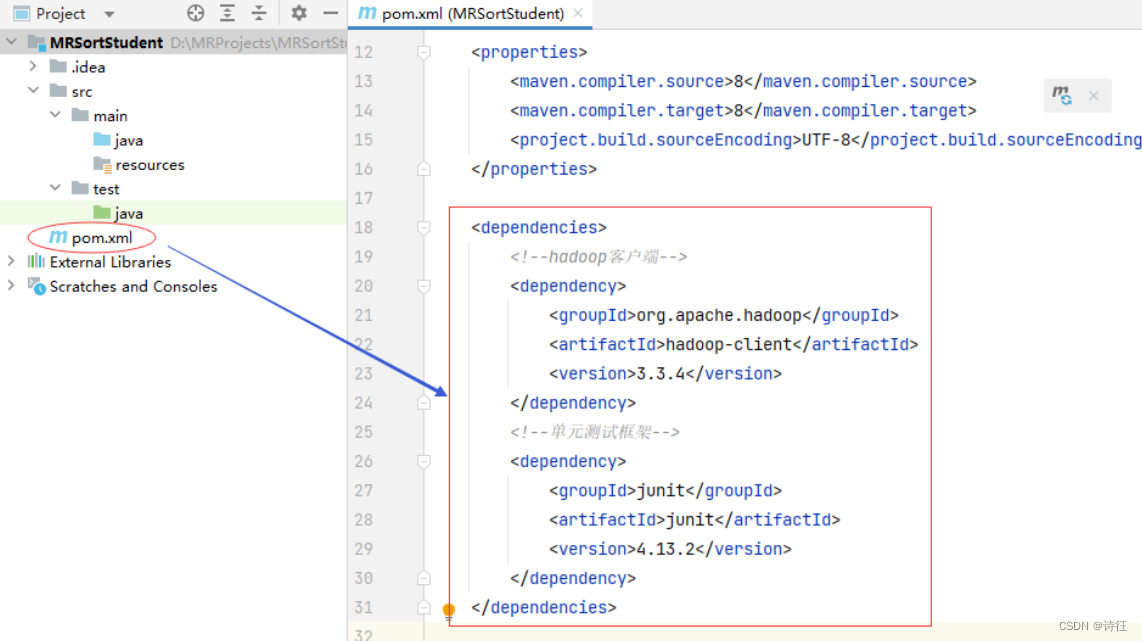
2、添加相关依赖
在pom.xml文件里添加hadoop和junit依赖

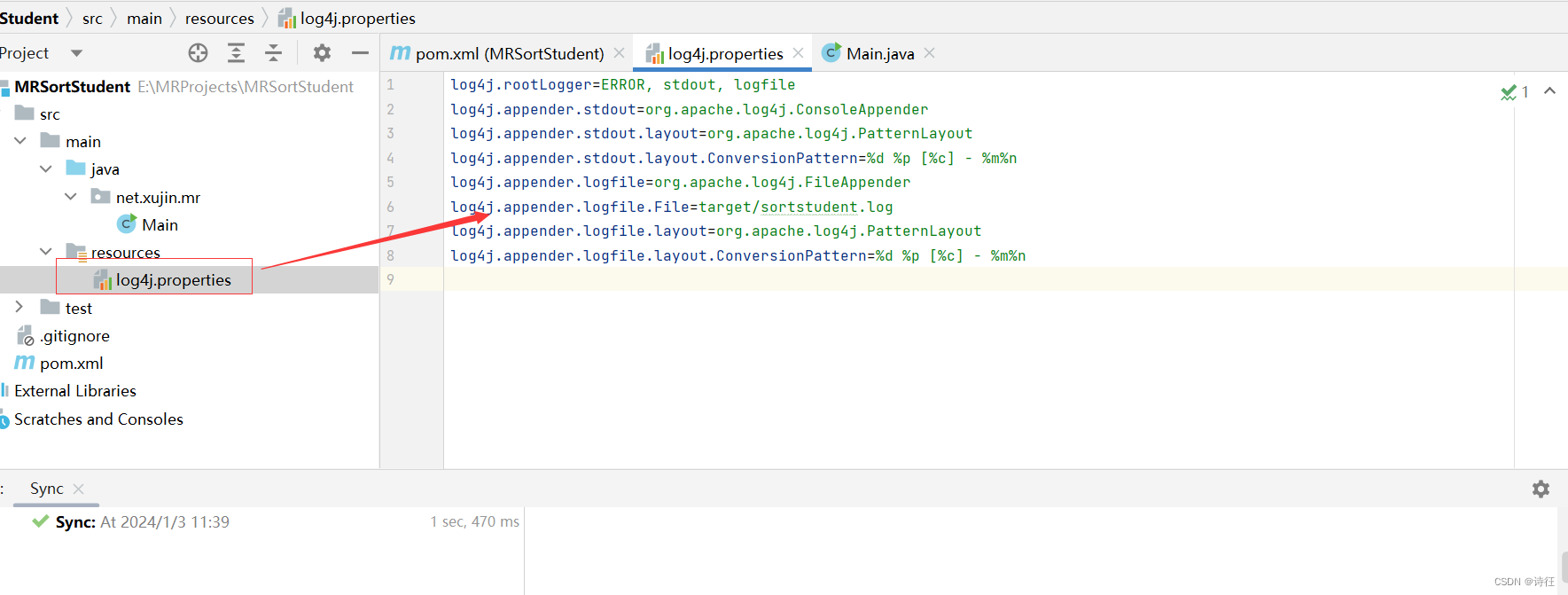
3、创建日志属性文件
创建文件log4j写入以下内容
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/sortstudent.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4、创建学生实体类
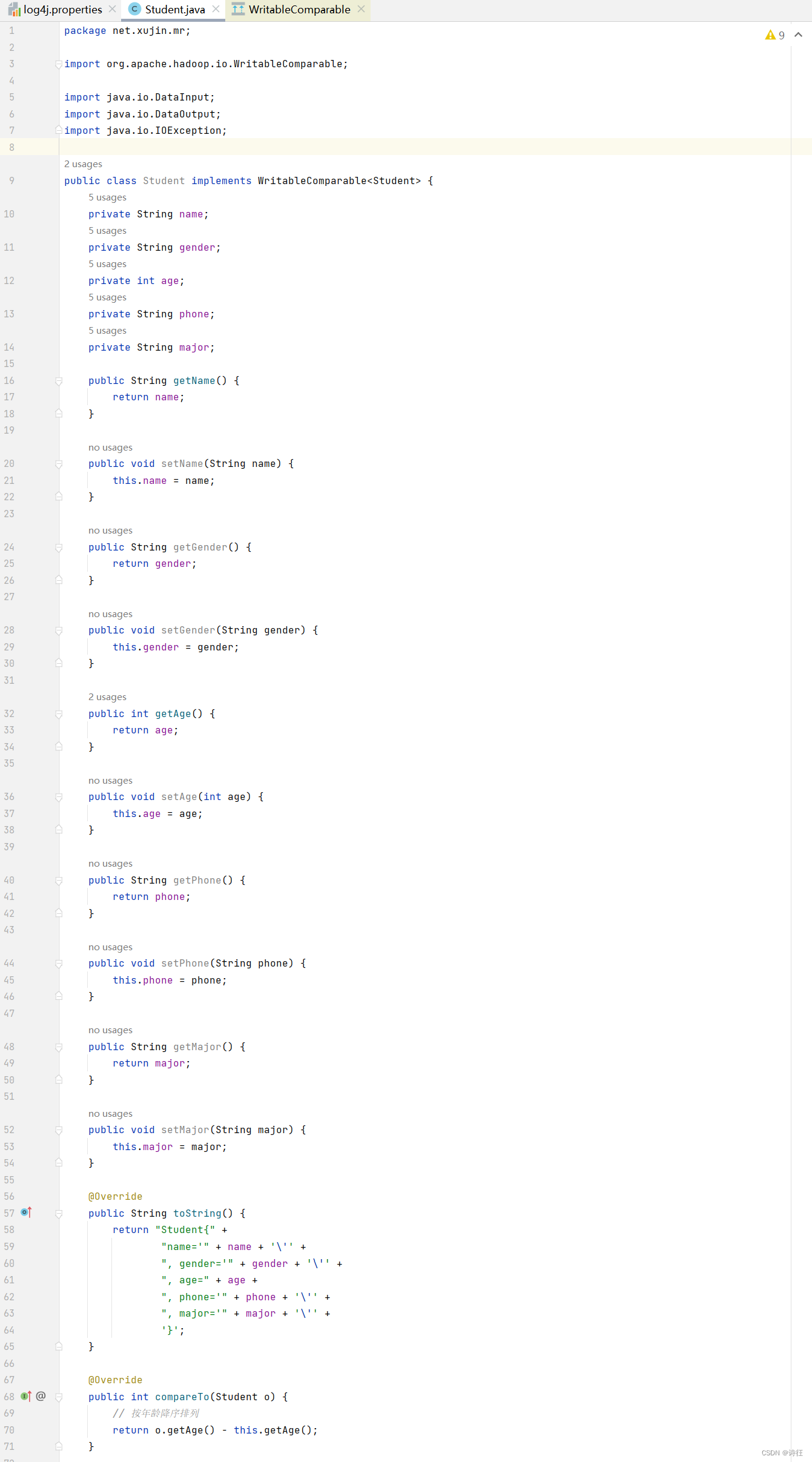
在net.xujin.mr下创建Student类
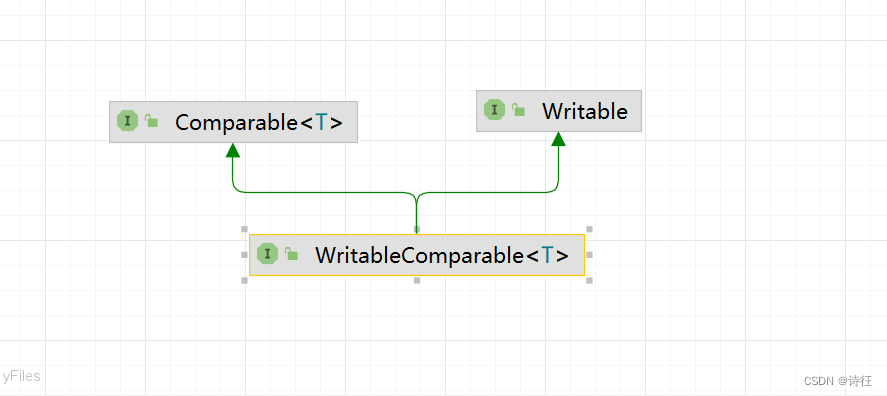
为了让学生按照年龄排序,需要让学生实体类实现一个序列化可比较接口 - WritableComparable,这个接口有三个抽象方法要我们去实现。
查看WritableComparable接口的继承关系图
写入以下内容
package net.xujin.mr;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Student implements WritableComparable<Student> {
private String name;
private String gender;
private int age;
private String phone;
private String major;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getMajor() {
return major;
}
public void setMajor(String major) {
this.major = major;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", gender='" + gender + '\'' +
", age=" + age +
", phone='" + phone + '\'' +
", major='" + major + '\'' +
'}';
}
@Override
public int compareTo(Student o) {
// 按年龄降序排列
return o.getAge() - this.getAge();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeUTF(gender);
out.writeInt(age);
out.writeUTF(phone);
out.writeUTF(major);
}
@Override
public void readFields(DataInput in) throws IOException {
name = in.readUTF();
gender = in.readUTF();
age = in.readInt();
phone = in.readUTF();
major = in.readUTF();
}
}
说明:该Java类Student表示学生对象,实现WritableComparable接口以供Hadoop处理。它包含姓名、性别、年龄、电话和专业属性的getter和setter方法。compareTo方法用于按年龄降序比较学生对象。write和readFields方法实现了序列化与反序列化,使得Student对象可在Hadoop数据流中读写传输。
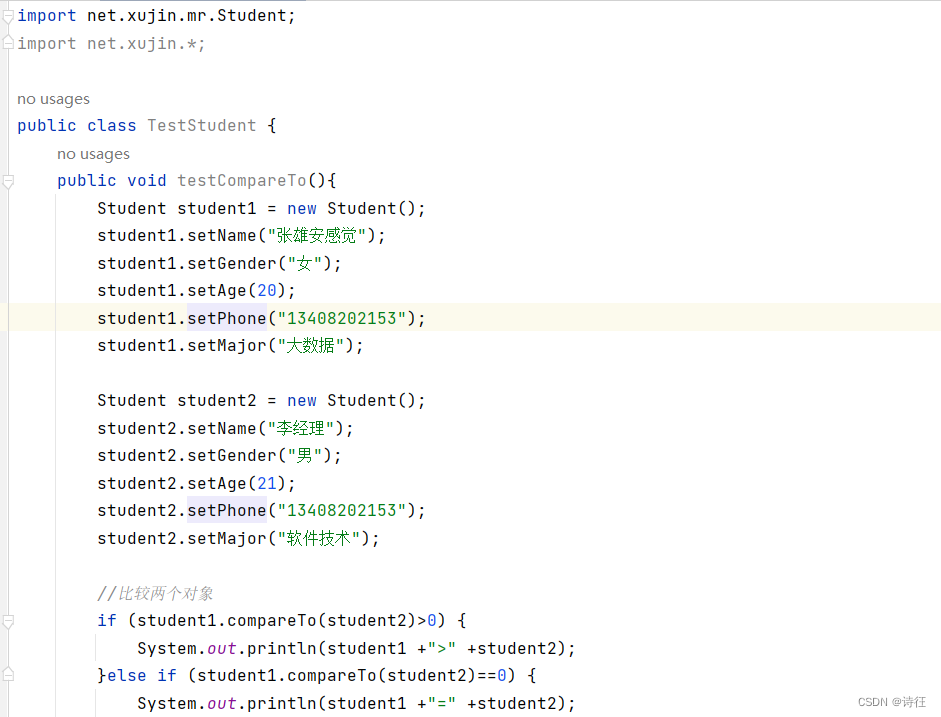
- 测试学生类是否可比较大小
在java中新建一个TestStudent类
import net.xujin.mr.Student;
import net.xujin.*;
public class TestStudent {
public void testCompareTo(){
Student student1 = new Student();
student1.setName("张雄安感觉");
student1.setGender("女");
student1.setAge(20);
student1.setPhone("13408202153");
student1.setMajor("大数据");
Student student2 = new Student();
student2.setName("李经理");
student2.setGender("男");
student2.setAge(21);
student2.setPhone("13408202153");
student2.setMajor("软件技术");
//比较两个对象
if (student1.compareTo(student2)>0) {
System.out.println(student1 +">" +student2);
}else if (student1.compareTo(student2)==0) {
System.out.println(student1 +"=" +student2);
}else {
System.out.println(student1 +"<" +student2);
}
}
}

5、创建学生映射器类
在net.xujin.mr下创建StudentMapper类
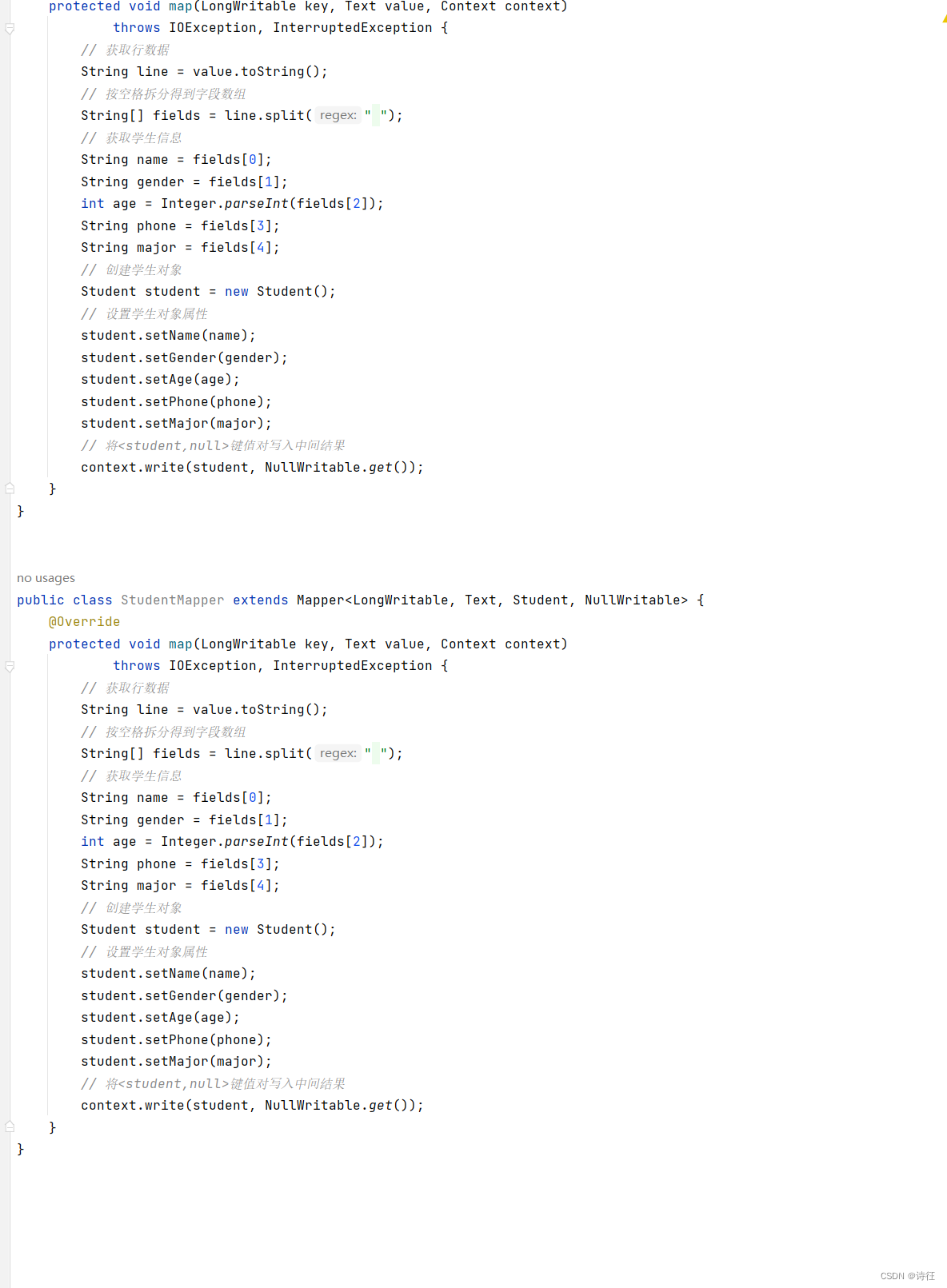
package net.xujin.mr;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class StudentMapper extends Mapper<LongWritable, Text, Student, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取行数据
String line = value.toString();
// 按空格拆分得到字段数组
String[] fields = line.split(" ");
// 获取学生信息
String name = fields[0];
String gender = fields[1];
int age = Integer.parseInt(fields[2]);
String phone = fields[3];
String major = fields[4];
// 创建学生对象
Student student = new Student();
// 设置学生对象属性
student.setName(name);
student.setGender(gender);
student.setAge(age);
student.setPhone(phone);
student.setMajor(major);
// 将<student,null>键值对写入中间结果
context.write(student, NullWritable.get());
}
}
说明:该Java类StudentMapper是Hadoop MapReduce作业的映射器,用于处理学生信息文本数据。它从输入行中解析出学生各项属性,并封装成Student对象student,然后将<student,null>键值对写入中间结果,以供后续Reducer阶段进一步处理。
6、创建学生归并器类
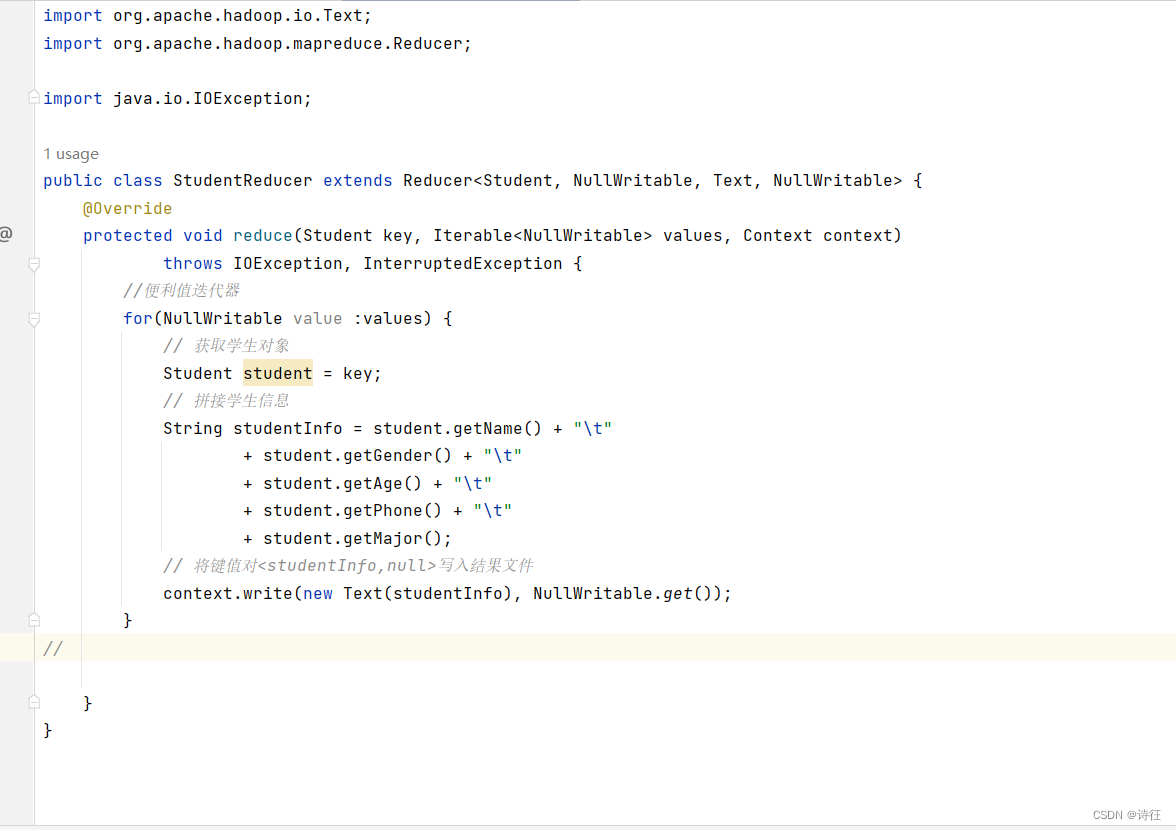
在net.xujin.mr包里创建StudentReducer类

说明:该Java类StudentReducer是Hadoop MapReduce的归并器,继承自Reducer。在reduce方法中,获取学生对象并拼接其各项属性信息为字符串studentInfo,然后将<studentInfo,null>键值对写入输出文件,实现对学生数据的收集与整合。
7、创建学生驱动器类
在net.xujin.mr包里创建StudentDriver类

package net.xujin.mr;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class StudentReducer extends Reducer<Student, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Student key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
// 获取学生对象
Student student = key;
// 拼接学生信息
String studentInfo = student.getName() + "\t"
+ student.getGender() + "\t"
+ student.getAge() + "\t"
+ student.getPhone() + "\t"
+ student.getMajor();
// 将键值对<studentInfo,null>写入结果文件
context.write(new Text(studentInfo), NullWritable.get());
}
}
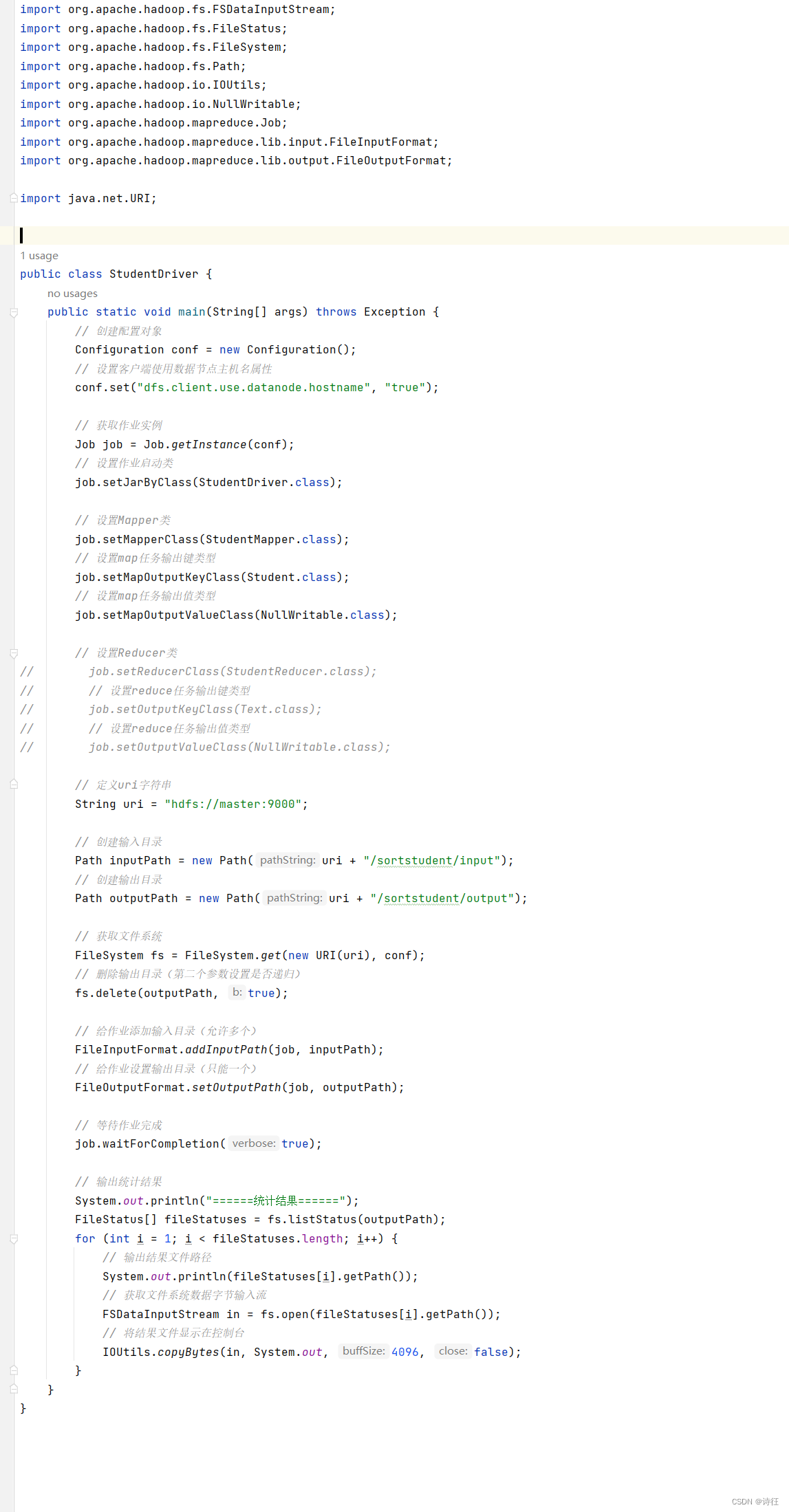
注意:暂时将Reducer类的设置注释掉

8、启动应用,查看结果
运行StudentDriver 类,看到输出的学生对象确实按按年龄降序排列

恢复对Reducer类的设置

运行StudentDriver 类,看到年龄安降序排序,但是少了3条记录

9、修改学生归并器类
修改学生归并器类,遍历值迭代器,这样就不会按“年龄”去重了
10、启动应用,查看结果
运行StudentDriver 类,结果符合要求

11、拓展联系,将结果改为升序排序
在Student类的compareTo方法中,交换o.getAge()和this.getAge()的位置

运行StudentDriver 类,结果符合要求

四、拓展练习
任务:学生信息排序,先按性别升序,再按年龄降序
修改compareTo
public int compareTo(Student o) {
//return o.getAge() - this.getAge();//降序
int genderComparison = o.getGender().compareTo(this.getGender());
if (genderComparison == 0) {
// 如果性别相同,则按照年龄排序
return o.getAge() - this.getAge();//升序
}
return genderComparison;
}

运行StudentDriver 类,结果符合要求
















 7570
7570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









