







1.HDFS的基本框架与工作过程
1.1 基本组成结构与文件访问过程
HDFS是一个建立在一组分布式服务器节点的本地文件系统之上的分布式文件系统。其采用经典的主-从式结构,其基本组成结构如图1所示。
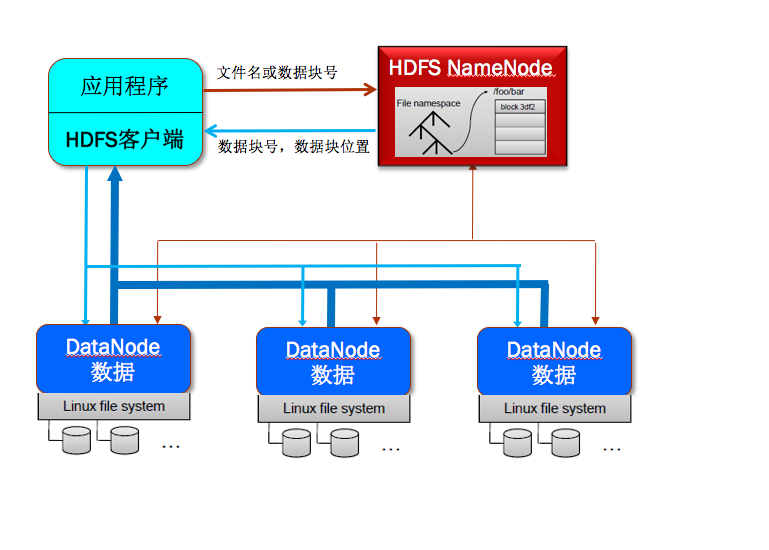
图1 HDFS的基本组成结构
一个HDFS文件系统包括一个主控节点NameNode和一组DataNode从节点。NameNode是一个主服务器,用来管理整个文件系统的命名空间和元数据,以及处理来自外界的文件访问请求。NameNode保存了文件系统的三种元素:
1)命名空间,即整个分布式文件系统的目录结构;
2)数据块与文件名映射表;
3)每个数据块副本的位置信息,每一个数据块默认有3个副本。
HDFS的基本文件访问过程是:
1)首先,用户的应用程序通过HDFS的客户端程序将文件名发送至NameNode。
2)NameNode接收到文件名之后,在HDFS目录中检索文件名对应的数据块,再根据数据块信息找到保存数据块的DataNode地址之后,与这些DataNode并行地进行数据传输操作,同时将操作结果的相关日志(比如是否成功,修改后的数据块信息等)提交到NameNode。
1.2 数据块
为提高硬盘效率,文件系统中最小的数据读写单位不是字节,而是一个更大的概念数据块。HDFS数据块的大小默认64MB,也可以设置成128MB等。数据块如此大,是为了减少寻址开销的时间。
1.3 命名空间
HDFS中的文件命名遵循了传统的“目录/子目录/文件“格式。通过命令行或者是API可以创建目录,并且将文件保存在目录中;也可以对文件进行创建,删除,重命名操作。命名空间由NameNode管理,所有对命名空间的改动(包括创建,删除,重命名,或改变属性等,但是不包括打开,读取,写入数据)都会被记录下来。
1.4 通信协议
HDFS采用TCP协议作为底层的支撑协议。基本实现架构图2所示。应用和NameNode的交互协议叫Client协议,NameNode和DataNode交互的协议叫DataNode协议。用户和DataNode交互是通过发起原创过程调用(Remote Procedure Call,RPC),并由NameNode响应来完成的。其中,NameNode不会主动发起远程过程调用请求。
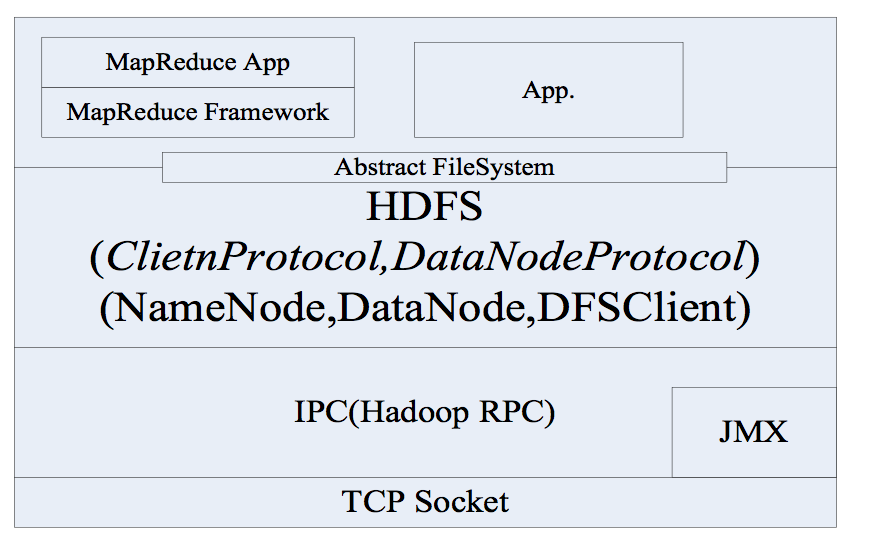
图2 HDFS基本实现架构
1.5 客户端
客户端并不是HDFS的一部分,但它是作为用户和HDFS通信最常见也是最方便的渠道。
除了命令行客户端外,HDFS还提供了应用开发程序时访问的编程接口。
2.HDFS可靠性设计
2.1 HDFS数据块多副本存储设计
HDFS采用了在系统中采用保存多个副本的方式保存数据,从而做到数据存储的可靠性,而且同一个数据块的多个副本会存放在不同的节点上。如图3所示。这种方式有以下优点:
1)客户可从不同数据块读数据,加快传输速度;
2)采用多副本可以用来做数据传输是否出错判断;
3)保证了在某个DataNode实效下,不丢失数据。
HDFS按照块的方式随机存储节点,为了可以判断数据是否出错,副本默认3个(1或2个不能判断数据对错)。
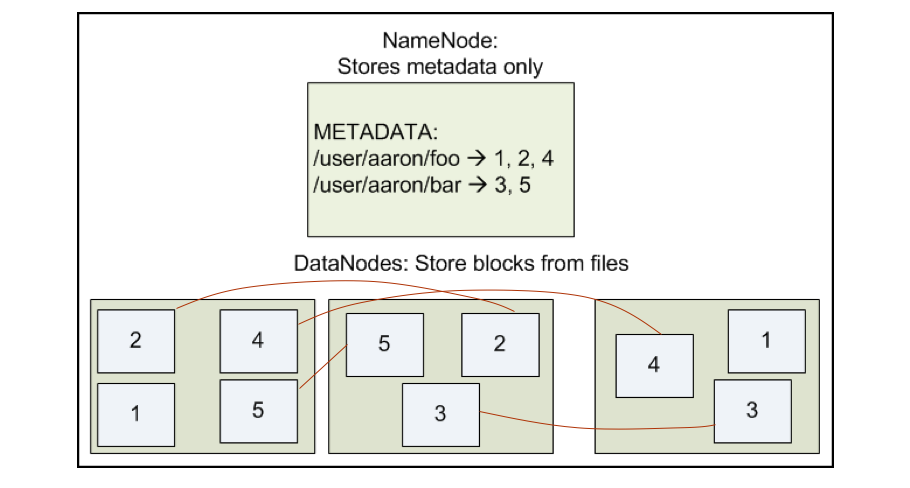
图3 HDFS数据分布设计
2.2 HDFS可靠性的设计实现
1)安全模式
HDFS刚启动的时候,NameNode进入安全模式,该模式下不能对文件做任何操作,等待每一个DataNode报告情况,当确认的安全数据块所占比例达到阀值,NameNode才推出安全模式。退出安全模式后才进行副本复制操作。
2)SecondaryNameNode
HDFS使用SecondaryNameNode来备份Name Node的元数据,以便NameNode实效后,能从SecondaryNameNode恢复出NameNode上的元数据。SecondaryNameNode作为NameNode的副本,本身不做任何操作。
3)心跳包
心跳:NameNode 不断检测DataNode是否有效,若失效,则寻找新的节点替代,将失效节点数据重新分布。
4)数据一致性
HDFS在创建文件时会一同创建一个校验和文件,文件在传输过程中会把文件本身和校验和文件一起发送过去,应用收到数据后会进行校验和,如果出错,需要从其他DataNode上读取副本。
5)组约
在Linux中,为了防止出现多个进程向同一个文件写数据的情况,采用了文件加锁的机制。在HDFS中,采用租约(Lease)机制来保证写入,一个客户端鼻血获得Name Node发放的一个租约,而同一个文件制发放一个租约,这样就保证了,只有拥有这个租约的用户可以写数据。不需要读写时,NameNode会收回租约。
6)回滚
如果在升级HDFS版本后,出现问题,可以用回滚,将恢复到前一个版本。
3.HDFS文件操作命令
文件操作命令的格式是:
bin/hdfs dfs -cmd < args >
举例:
这个例子的图来自hadoop笔记5。

图4 HDFS文件操作指令
1) mkdir
命令:bin/hdfs dfs -mkdir /user (来自图4)
说明:在分布式文件系统中创建文件夹user
2) put
命令:bin/hdfs dfs -put input (来自图4)
说明:将本地的文件夹input上传到HDFS上。
其他命令如cat,cp,get,ls,mv,rm等,这里不多介绍,读者可自行搜索。
4.HDFS基本编程接口与示例
在后面笔记会有项目,会在后面逐步使用API,所以不在这里过多介绍。读者可到官网直接查看:
http://hadoop.apache.org/docs/current/api/overview-summary.html
本文的学习内容整理自《深入理解大数据-大数据处理与编程实践》机械工业出版。以及我导师云计算课程的PPT。有不当之处,还望指正。

















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









