










需求
目标网址:http://www.p2pjd.com/Article_Class_103.html
- 点开链接,获取网贷黑名单的内容,不管信息是什么,每一条都保存为一条数据到txt。
- 将获取的数据中的电话号,手机号,qq号提取出来,保存于另一文件中。
代码
和上一篇的爬取方法类似:http://blog.csdn.net/xunalove/article/details/77906343
使用selenium爬虫利器自动爬取113条信息,然后通过正则匹配出想要的数据。
# -*- coding:utf-8 -*-
#-*- coding:utf-8 -*-
import unittest
import time
import re
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import sys
reload(sys)
sys.setdefaultencoding("ISO-8859-1")
def get_all_code():
f = open("/home/xuna/桌面/img_code/all.txt",'w')
url = 'http://www.p2pjd.com/News/20433.html'
driver = webdriver.Chrome()
driver.get(url)
n =1
for i in range(113):
name_xpath = '//*[@id="content"]'
name = driver.find_element_by_xpath(name_xpath).text.encode("GB18030","ignore")
name = "".join(name.split())
try:
f.write(name + "\n")
except:
print "cuowu"
print n
n = n + 1
if i == 112:
break
click_btn = driver.find_element_by_xpath('//*[@id="web2l"]/div[4]/li[1]/a')
ActionChains(driver).click(click_btn).perform()
driver.close()
def get_num():
f = open("/home/xuna/桌面/img_code/all.txt",'r')
f1 = open("/home/xuna/桌面/img_code/phone_number.txt",'a')
s = ""
for line in f:
temp = line.decode("GB18030","ignore")
s = s + temp
#手机号
t = set()
res = re.findall(r'1[3458]\d{9}',s) + re.findall(r'\d{3}-\d{8}|\d{4}-\{7,8}',s) + re.findall(r'[1-9][0-9]{4,9}',s)
#去重
for num in res:
t.add(num)
for num in t:
f1.write(str(num) + "\n")
print len(t)
if __name__ == "__main__":
#获取全部的数据
#get_all_code()
#依次获取数据中的手机号,电话号和QQ号
get_num()效果
获取的全部数据
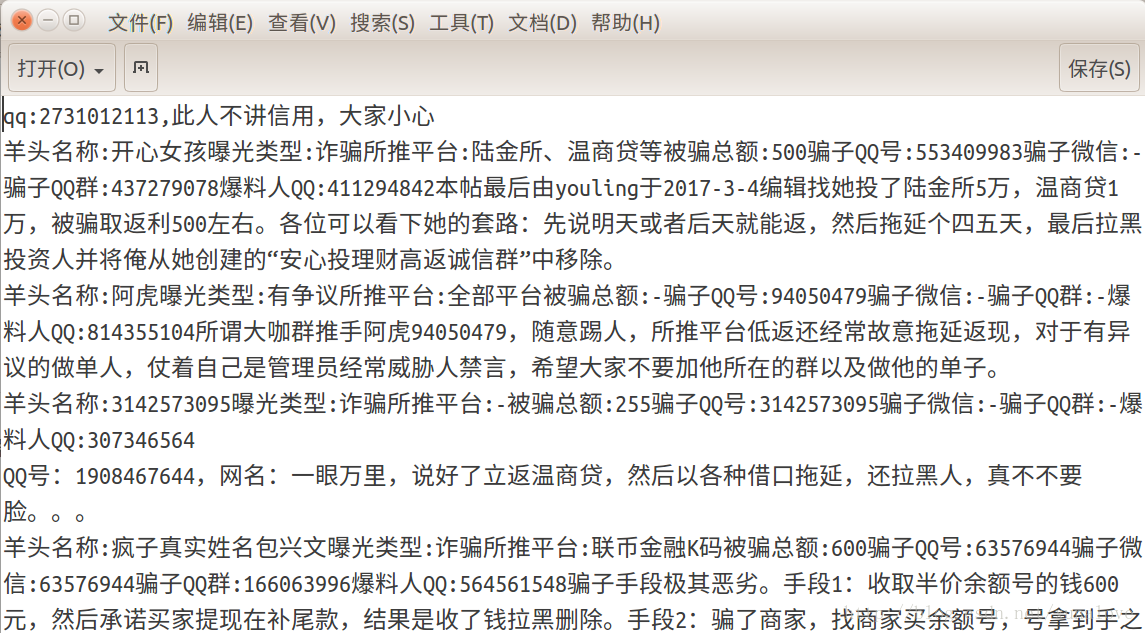
获取的手机号,电话号和qq号

存在的问题
匹配的手机号里面会存在身份证号的部分,匹配的qq号则会混合进去身份证号和部分金钱的数字。
解决方法
先匹配出身份证号,替换为空,然后匹配手机,匹配一个手机号就将其替换为空,之后匹配的qq号里面则不会存在身份证号和手机号,但是还有有部分金钱的数字混进去。。















 980
980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









