







【百度系列 I】多关键字图片搜索结果汇总
【百度系列 II】关键字搜索url结果汇总(给定关键字和页数)
【百度系列 III】深度搜索(给定网址采集全部url)
需求
批量自动化采集百度图片。
1. 模拟百度图片输入关键字,获取结果。
2. 将搜索的结果图片(先保存600张)保存在文件夹中,以下面格式“关键字_n.jpg”(n取1,2,3,4,…..)
思路
方法一
- 通过requests请求url。
- 解析获取的html文本,获取图片url集合。
做着的时候发现果然百度的图片不是辣么简单的。(貌似有点复杂)
图一

方法二
利用强大的Chrome浏览器的开发者工具(F12)分析百度图片时如何处理请求的。
图二
分析同一关键字的不同请求的url变化(copy link adress)。
图三
从上面我们可以大致的猜想一下:除去相同的字段,我们可以找到四个不同的字段。
大概是:- queryWord = “xx” : 输入的关键词
- pn=30, pn=60 : 在获取结果中我们可以发现,要查看更多的图片,需要下拉,很有可能就是通过pn控制的。
- rn=30 : 两次都没有改变,大概是每页30张照片。
- &gsm=3c&1510487919192=:暂时不太清楚,而且发生变化了,先去掉。
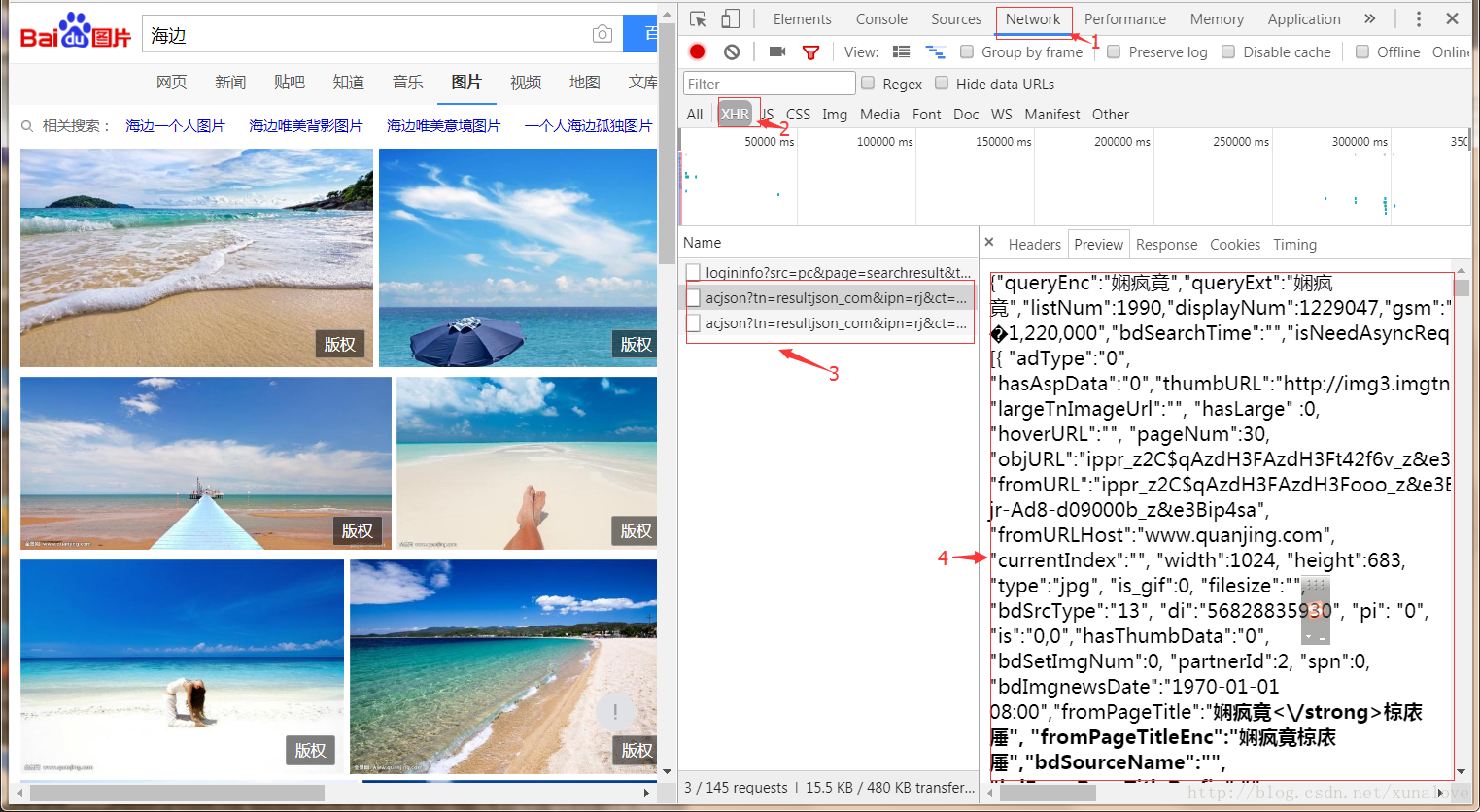

有了以上的猜测如何获取根据图片请求的url获取图片的url集合,先分析图一4中Preview中的参数(Network中的Preview是发送请求后,从服务器端返回web前端发送一段json数据,有点乱码,可以复制到https://www.bejson.com/这里,点击校验,会自动回复json格式),如下所示:
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









