







原文链接:点击打开链接
在看了一些深度学习的目标检测的论文后,想着去用开源的代码去跑一下,看看实际的效果。于是小菜就想着直接把faster_rcnn用起来,包括前期的faster_rcnn安装和配置并运行其中的一个demo.py。后面是用自己的数据集训练faster_rcnn的模型。
1. 准备工作:
-
1) 搭建caffe框架
这个可以参考linux先搭建caffe的笔记。
-
2) 安装第三方依赖包:Cython、 python-opencv、easydict
pip install cython
pip install easydict
apt-get install python-opencv
- 3)下载py-faster-rcnn
# Make sure to clone with --recursive
git clone --recursive https://github.com/rbgirshick/py-faster-rcnn.git - 4) 编译faster_rcnn
进入py-faster-rcnn/lib,执行make
cd py-faster-rcnn/lib
make- 5) 配置faster_rcnn
进入py-faster-rcnn\caffe-fast-rcnn,执行
cp Makefile.config.example Makefile.config然后,配置Makefile.config文件,配置好Makefile.config文件后,执行:
make –j4 && make pycaffe 注:我在这一步出错了,老是不能编译成功。问题应该是出在Makefile.config文件内容中的,应该是出在路径添加中出错。
解决:
在原来搭建的caffe文件中将Makefile.config文件内容直接复制过来。
接下来下载已经训练好的faster模型,进入py-faster_rcnn/data/scripts目录,执行./fech-faster_rcnn_models,sh
- 6) 测试faster_rcnn
运行网络和加载下载的模型进行最后的测试demo
执行:
./tools/demo.py出现问题:
ImportError:No module named yaml
解决:
sudo apt-get install python-yaml2. 训练步骤:
-
1) 下载VOC2007数据集
提供一个百度云地址:http://pan.baidu.com/s/1mhMKKw4
解压,然后,将该数据集放在py-faster-rcnn\data下,用自己的数据集替换VOC2007数据集。(替换Annotations,ImageSets和JPEGImages)(用你的Annotations,ImagesSets和JPEGImages替换py-faster-rcnn\data\VOCdevkit2007\VOC2007中对应文件夹)。 -
2) 下载ImageNet数据集下预训练得到的模型参数(用来初始化)
提供一个百度云地址:http://pan.baidu.com/s/1hsxx8OW解压,然后将该文件放在py-faster-rcnn\data下。
-
3) 修改训练的配置文件
1.py-fasterrcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt/
stage1_fast_rcnn_train.pt修改
1. layer {
2. name: 'data'
3. type: 'Python'
4. top: 'data'
5. top: 'rois'
6. top: 'labels'
7. top: 'bbox_targets'
8. top: 'bbox_inside_weights'
9. top: 'bbox_outside_weights'
10. python_param {
11. module: 'roi_data_layer.layer'
12. layer: 'RoIDataLayer'
13. param_str: "'num_classes': 16" #按训练集类别改,该值为类别数+1
14. }
15. }
1. layer {
2. name: "cls_score"
3. type: "InnerProduct"
4. bottom: "fc7"
5. top: "cls_score"
6. param { lr_mult: 1.0 }
7. param { lr_mult: 2.0 }
8. inner_product_param {
9. num_output: 16 #按训练集类别改,该值为类别数+1
10. weight_filler {
11. type: "gaussian"
12. std: 0.01
13. }
14. bias_filler {
15. type: "constant"
16. value: 0
17. }
18. }
19. }
1. layer {
2. name: "bbox_pred"
3. type: "InnerProduct"
4. bottom: "fc7"
5. top: "bbox_pred"
6. param { lr_mult: 1.0 }
7. param { lr_mult: 2.0 }
8. inner_product_param {
9. num_output: 64 #按训练集类别改,该值为(类别数+1)*4
10. weight_filler {
11. type: "gaussian"
12. std: 0.001
13. }
14. bias_filler {
15. type: "constant"
16. value: 0
17. }
18. }
19. } 2.py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt/stage1_rpn_train.pt修改
1. layer {
2. name: 'input-data'
3. type: 'Python'
4. top: 'data'
5. top: 'im_info'
6. top: 'gt_boxes'
7. python_param {
8. module: 'roi_data_layer.layer'
9. layer: 'RoIDataLayer'
10. param_str: "'num_classes': 16" #按训练集类别改,该值为类别数+1
11. }
12. }3.py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt/stage2_fast_rcnn_train.pt修改
1. layer {
2. name: 'data'
3. type: 'Python'
4. top: 'data'
5. top: 'rois'
6. top: 'labels'
7. top: 'bbox_targets'
8. top: 'bbox_inside_weights'
9. top: 'bbox_outside_weights'
10. python_param {
11. module: 'roi_data_layer.layer'
12. layer: 'RoIDataLayer'
13. param_str: "'num_classes': 16" #按训练集类别改,该值为类别数+1
14. }
15. }
1. layer {
2. name: "cls_score"
3. type: "InnerProduct"
4. bottom: "fc7"
5. top: "cls_score"
6. param { lr_mult: 1.0 }
7. param { lr_mult: 2.0 }
8. inner_product_param {
9. num_output: 16 #按训练集类别改,该值为类别数+1
10. weight_filler {
11. type: "gaussian"
12. std: 0.01
13. }
14. bias_filler {
15. type: "constant"
16. value: 0
17. }
18. }
19. } 1. layer {
2. name: "bbox_pred"
3. type: "InnerProduct"
4. bottom: "fc7"
5. top: "bbox_pred"
6. param { lr_mult: 1.0 }
7. param { lr_mult: 2.0 }
8. inner_product_param {
9. num_output: 64 #按训练集类别改,该值为(类别数+1)*4
10. weight_filler {
11. type: "gaussian"
12. std: 0.001
13. }
14. bias_filler {
15. type: "constant"
16. value: 0
17. }
18. }
19. } 4.py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt/stage2_rpn_train.pt修改
1. layer {
2. name: 'input-data'
3. type: 'Python'
4. top: 'data'
5. top: 'im_info'
6. top: 'gt_boxes'
7. python_param {
8. module: 'roi_data_layer.layer'
9. layer: 'RoIDataLayer'
10. param_str: "'num_classes': 16" #按训练集类别改,该值为类别数+1
11. }
12. } 5.py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt/faster_rcnn_test.pt修改
1. layer {
2. name: "cls_score"
3. type: "InnerProduct"
4. bottom: "fc7"
5. top: "cls_score"
6. inner_product_param {
7. num_output: 16 #按训练集类别改,该值为类别数+1
8. }
9. } 1. layer {
2. name: "bbox_pred"
3. type: "InnerProduct"
4. bottom: "fc7"
5. top: "bbox_pred"
6. inner_product_param {
7. num_output: 64 #按训练集类别改,该值为(类别数+1)*4
8. }
9. } 6.py-faster-rcnn/lib/datasets/pascal_voc.py修改
1.class pascal_voc(imdb):
- def __init__(self, image_set, year, devkit_path=None):
- imdb.__init__(self, 'voc_' + year + '_' + image_set)
- self._year = year
- self._image_set = image_set
- self._devkit_path = self._get_default_path() if devkit_path is None \
- else devkit_path
- self._data_path = os.path.join(self._devkit_path, 'VOC' + self._year)
- self._classes = ('__background__', # always index 0
- '你的标签1','你的标签2',你的标签3','你的标签4'
- ) 上面要改的地方是
修改训练集文件夹:
self._data_path = os.path.join(self._devkit_path, 'VOC'+self._year) 用你的数据集直接替换原来VOC2007内的Annotations,ImageSets和JPEGImages就不用修改,以免出现各种错误。
修改标签:
self._classes = (‘background‘, # always index 0
‘你的标签1’,’你的标签2’,’你的标签3’,’你的标签4’)
修改成你的数据集的标签就行。
(2)
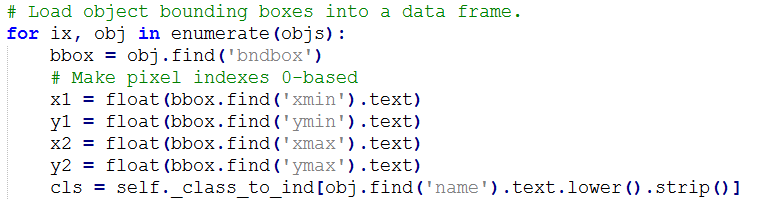
cls = self._class_to_ind[obj.find(‘name’).text.lower().strip()]
这里把标签转成小写,如果你的标签含有大写字母,可能会出现KeyError的错误,所以建议标签用小写字母。建议训练的标签还是用小写的字母,如果最终需要用大写字母或中文显示标签,可参考:http://blog.csdn.net/sinat_30071459/article/details/51694037
7.py-faster-rcnn/lib/datasets/imdb.py修改
该文件的append_flipped_images(self)函数修改为:
1. def append_flipped_images(self):
2. num_images = self.num_images
3. widths = [PIL.Image.open(self.image_path_at(i)).size[0]
4. for i in xrange(num_images)]
5. for i in xrange(num_images):
6. boxes = self.roidb[i]['boxes'].copy()
7. oldx1 = boxes[:, 0].copy()
8. oldx2 = boxes[:, 2].copy()
9. boxes[:, 0] = widths[i] - oldx2 - 1
10. print boxes[:, 0]
11. boxes[:, 2] = widths[i] - oldx1 - 1
12. print boxes[:, 0]
13. assert (boxes[:, 2] >= boxes[:, 0]).all()
14. entry = {'boxes' : boxes,
15. 'gt_overlaps' : self.roidb[i]['gt_overlaps'],
16. 'gt_classes' : self.roidb[i]['gt_classes'],
17. 'flipped' : True}
18. self.roidb.append(entry)
19. self._image_index = self._image_index * 2 注:为防止与之前的模型搞混,训练前把output文件夹删除(或改个其他名),还要把py-faster-rcnn/data/cache中的文件和
py-faster-rcnn/data/VOCdevkit2007/annotations_cache中的文件删除(如果有的话)。
4) 训练参数设置
可在py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt中的solve文件设置,迭代次数可在py-faster-rcnn\tools的train_faster_rcnn_alt_opt.py中修改:
max_iters = [80000, 40000, 80000, 40000]
分别为4个阶段(rpn第1阶段,fast rcnn第1阶段,rpn第2阶段,fast rcnn第2阶段)的迭代次数。可改成你希望的迭代次数。如果改了这些数值,最好把py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt里对应的solver文件(有4个)也修改,stepsize小于上面修改的数值。
5) 开始训练
进入py-faster-rcnn,
执行
./experiments/scripts/faster_rcnn_alt_opt.sh 0 ZF pascal_voc 这样,就开始训练了。
我训练这里出错:
开始数据集的制作中,标签的名字是数字1,出现KeyError ‘3’
解决:在生成XML文件的代码中修改标签的name为小写英文字母。
错误:
File “/py-faster-rcnn/tools/../lib/datasets/imdb.py”, line 108, in append_flipped_images
assert (boxes[:, 2] >= boxes[:, 0]).all()
解决:检查自己数据发现,左上角坐标(x,y)可能为0,或标定区域溢出图片
1、修改lib/datasets/imdb.py,append_flipped_images()函数
数据整理,在一行代码为 boxes[:, 2] = widths[i] - oldx1 - 1下加入代码:
for b in range(len(boxes)):
if boxes[b][2]< boxes[b][0]:
boxes[b][0] = 0
2、修改lib/datasets/pascal_voc.py,_load_pascal_annotation(,)函数
将对Xmin,Ymin,Xmax,Ymax减一去掉,变为:
6) 测试
将训练得到的py-faster-rcnn\output\faster_rcnn_alt_opt***_trainval中ZF的caffemodel拷贝至py-faster-rcnn\data\faster_rcnn_models(如果没有这个文件夹,就新建一个),然后,修改:py-faster-rcnn\tools\demo.py,主要修改:
1. CLASSES = ('__background__',
2. '你的标签1', '你的标签2', '你的标签3', '你的标签4') 改成你的数据集标签:
1. NETS = {'vgg16': ('VGG16',
2. 'VGG16_faster_rcnn_final.caffemodel'),
3. 'zf': ('ZF',
4. 'ZF_faster_rcnn_final.caffemodel')} 上面ZF的caffemodel改成你的caffemodel。
1. im_names = ['1559.jpg','1564.jpg'] 改成你的测试图片。(测试图片放在py-faster-rcnn\data\demo中)
7) 结果
在py-faster-rcnn下,
执行:./tools/demo.py –net zf
或者将默认的模型改为zf:
parser.add_argument('--net', dest='demo_net', help='Network to use [vgg16]',
choices=NETS.keys(), default='vgg16') 修改:
default=’zf’
执行:./tools/demo.py















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









