







文章目录
- 面向对象的三大特征和六大原则
- hash
- 数据结构与算法
- 操作系统
- 计算机网络
- 接口
- rest API
- java高级
- 异常
大佬面经
面向对象的三大特征和六大原则
hashSet的add方法
String类的面试问题
Arrays.sort()
默认从小到大,怎么改成从大到小
https://blog.csdn.net/qq_41257129/article/details/80209496
https://blog.csdn.net/qq_41763225/article/details/82890122
索引值及长度
String的charAt() :
charAt() 方法用于返回指定索引处的字符。索引范围为从 0 到 length() - 1。
String s = "www.runoob.com";
char result = s.charAt(8);
System.out.println(result);
//长度:s.length();
string和int的转换
https://www.cnblogs.com/panxuejun/p/6148493.html
ArrayList
ArrayList<String> list = new ArrayList<String>();
for(int i=0;i<list.size();i++) {
System.out.println(list.get(i));
}
//长度:list.size();
Stack,ArrayDeque,LinkedList的区别
实参形参:值传递和引用传递
string,stringbuffer
对象传递
try和finally的参数传递的区别
详细的参数传递
值传递的常见面试题
indexOf()
indexOf() 方法有以下四种形式:
public int indexOf(int ch): 返回指定字符在字符串中第一次出现处的索引,如果此字符串中没有这样的字符,则返回 -1。
public int indexOf(int ch, int fromIndex): 返回从 fromIndex 位置开始查找指定字符在字符串中第一次出现处的索引,如果此字符串中没有这样的字符,则返回 -1。
int indexOf(String str): 返回指定字符在字符串中第一次出现处的索引,如果此字符串中没有这样的字符,则返回 -1。
int indexOf(String str, int fromIndex): 返回从 fromIndex 位置开始查找指定字符在字符串中第一次出现处的索引,如果此字符串中没有这样的字符,则返回 -1
JavaBean
维基百科:JavaBeans是Java中一种特殊的类,可以将多个对象封装到一个对象(bean)中。特点是可序列化,提供无参构造器,提供getter方法和setter方法访问对象的属性。名称中的“Bean”是用于Java的可重用软件组件的惯用叫法。
MVC设计模式
PriorityQueue有限队列
单例模式和工厂模式
Java与B/S架构
Java技术是一个体系,主要包含三个部分:J2SE(标准版)、J2EE(企业版)、 J2ME(移动版)。
当然这其中应用最为广泛的当属J2EE。
java的客户端也可以分成两种,一种是软件交互形式(Client/Server,C/S模式),主要由J2SE完成;另一种是浏览器交互形式(Browser/Server,B/S模式),主要由J2EE实现。(XML作为数据传输方式,不属于数据表现层,不算是客户端)
J2EE的表现层主要是jsp技术(当然,表现层实际中还会包含html,css,javascript客户端脚本及其类库,flash平台应用等)。
Java的B/S模式架构具体可有以下几种组合:
- jsp
纯jsp+html+JavaBean就可以实现简单的B/S架构,类似于基于php的WordPress博客程序,比较简单方便。在html代码中混合jsp代码,直接在页面通过dao访问数据库,得到数据并显示。
- jsp+Servlet
这是基于MVC(Model-View-Control,模型-视图-控制)的一种架构。jsp作为视图层(表现层),Servlet作为Control层,负责处理请求分发,是业务逻辑层,Model层则是JavaBean,负责数据的封装及与视图层的交互。
- jsp+Struts
Struts(Struts1.2)实现了对请求分发的统一配置管理,Action通过单例模式,减少了服务器内存消耗;ActionValidateForm实现了表单的预处理和服务器端验证,提高了安全性。
- jsp+Struts+Spring+Hibernate
Spring常见的模块是IOC和AOP,Spring IOC基于控制反转思想的一种新架构,通过配置文件统一配置,进行属性注入,实现了软件基于组件的可插拔,极大地降低了业务逻辑层与JavaBean的耦合度;Spring AOP是面向方面编程的一种实现,通过代理模式实现了强大的事务管理。
- jsp+Struts+Spring+EJB
EJB是Enterprise JavaBean的缩写,是一种SOA(面向服务架构),通过向用户提供统一接口(service抽象接口),用户可以通过该接口访问服务,实现RMI(远程方法调用),并且对用户屏蔽了数据库的细节和具体函数,保证了服务器端的数据安全。
其实,采用各种框架带来了一些执行效率上的问题,但是在J2EE项目中,用户的需求不断改变,企业只有通过采用成熟的框架,降低开发成本,提高代码重用性,才能在市场中生存。框架让程序员可以把精力更多地放在业务逻辑层,开发出复杂业务逻辑的行业方案,比如医疗、财务。
注:
以上只是常见的几种技术(框架)组合,实际中可有其它选择;以上的组合中均应包含JavaBean,如vo(po)、dao、factory等,由于JavaBean也可重用于C/S模式,故没有将之包含在内;B/S模式一般还应该包含数据库。
jdk1.7与1.8区别
区别
hashmap
美团hashmap
红黑树
红黑树转化
hashmap与hashtable
hashmap的数据结构:
https://www.cnblogs.com/dassmeta/p/5338955.html
https://blog.csdn.net/Jae_Peng/article/details/79562432
https://blog.csdn.net/u013851082/article/details/53942319
https://blog.csdn.net/TomCosin/article/details/82769532
https://www.cnblogs.com/finite/p/8251587.html
https://blog.csdn.net/it_manman/article/details/79423593
是否阅读jdk源码,实现类是怎么弄
java八大基本数据类型及其封装类,对应的字节数
八大数据类型
1个字节是8位。
byte 1字节 -128~127
short 2字节 -32768~32767
int 4字节 -2147483648~2147483647
long 8字节 -9223372036854775808 ~ 9223372036854775807
float 4字节 -3.4E38~3.4E38
double 8字节 -1.7E308~1.7E308
char 2字节 从字符型对应的整型数来划分,其表示范围是0~65535
boolean 1 true或false
输出
System.out.println()这个是在输出内容之后换行,而 System.out.print()输出内容之后不换行。只是一个 ln 的差距
final、static、this、super 关键字
https://blog.csdn.net/kye055947/article/details/88565318
final:
https://www.cnblogs.com/xiaoxiaoyihan/p/4974273.html
http://c.biancheng.net/view/763.html
https://zhidao.baidu.com/question/202970284.html
https://www.jianshu.com/p/fb87dd2ed094
https://blog.csdn.net/qq_31433709/article/details/87823478
java类变量和实例变量的区别
https://www.cnblogs.com/zxan/p/7277876.html
https://www.cnblogs.com/baby-zhude/p/8011969.html
java中静态方法为什么无法调用非静态变量或者方法
https://ask.csdn.net/questions/748681
https://blog.csdn.net/qq_36428821/article/details/78674318
java多态性及java怎么实现多态性
多态实现
https://www.cnblogs.com/serendipity-fly/p/9469289.html
https://www.cnblogs.com/1693977889zz/p/8298240.html
重写和重载的区别
https://www.cnblogs.com/zhuangsl/p/11237184.html
https://blog.csdn.net/qunqunstyle99/article/details/81007712
java类不能多继承,接口可以多继承
https://www.cnblogs.com/Berryxiong/p/6142735.html
extends和implements的区别
https://blog.csdn.net/qq_15037231/article/details/82813140
hash
解决hash冲突的四种办法
1.开放定址法
线性探测再散列
二次探测再散列
伪随机探测再散列
2.再哈希法
3.链地址法
4.建立公共溢出区
具体内容及优缺点
拉链法的优点:
(1)处理冲突简单,没有堆积现象,平均查找长度较短
(2)拉链法中的链表上的节点空间是动态申请的,更适合于创造表之前无法确定表长的情况
(3)开放定址法为了减少冲突,要求装填因子较小,节点规模大时会浪费空间,结点较大时,拉链法中增加的指针域可以忽略不计,节省空间
(4)用拉链法构造的散列表中,删除节点的操作易于实现,只要删掉相应节点就可以,而开放地址构造的散列表,不能直接将对应位置质控,否则将截断在它之后填入的冲突的节点的查找。
拉链法的缺点:
指针需要额外的空间,节点规模较小,开放定址法较为节省空间。
hashcode,==和equals的区别
hashmap源码
java7及jav8的hashmap和concurrenthashmap源码
hashmap源码分析
HashMap的数组大小为什么必须为2的n次幂,我们对其作出了一个层次的回答,而其第二个层次的回答就在resize函数的执行逻辑中。在Java8的扩容中,不是简单的将原数组中的每一个元素取出进行重新hash映射,而是做移位检测。所谓移位检测的含义具体是针对HashMap做映射时的&运算所提出的,通过上文对&元算的分析可知,映射的本质即看hash值的某一位是0还是1,当扩容以后,会相比于原数组多出一位做比较,由多出来的这一位是0还是1来决定是否进行移位,而具体的移位距离,也是可知的,及位原数组的大小,我们来看下表的分析,假定原表大小为16:
HashCode(Java8中只使用高16位) size=16 size=32 移位情况
0101 1010 0011 1101 0101101000111101&1111 0101101000111101&11111 向前移动16位
1011 0111 1000 0101 1011011110000101&1111 1011011110000101&11111 不移动
1110 0100 0001 0001 1110010000010001&1111 1110010000010001&1111 向前移动16位
由上表可知,是否移位,由扩容后表示的最高位是否为所决定,并且移动的方向只有一个,即向高位移动。因此,可以根据对最高位进行检测的结果来决定是否移位,从而可以优化性能,不用每一个元素都进行移位。
————————————————
hashcode和hashmap的计算!必看!面试前!
计算hashcode:乘31
为什么线程不安全
HashMap 在并发时可能出现的问题主要是两方面:
如果多个线程同时使用 put 方法添加元素,而且假设正好存在两个 put 的 key 发生了碰撞(根据 hash 值计算的 bucket 一样),那么根据 HashMap 的实现,这两个 key 会添加到数组的同一个位置,这样最终就会发生其中一个线程 put 的数据被覆盖
如果多个线程同时检测到元素个数超过数组大小 * loadFactor,这样就会发生多个线程同时对 Node 数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给 table,也就是说其他线程的都会丢失,并且各自线程 put 的数据也丢失
1.Hashmap在插入元素过多的时候需要进行Resize,Resize的条件是HashMap.Size >= Capacity * LoadFactor。
2.Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在并发的情况下可能会形成链表环。
HashMap和Hashtable、HashSet的区别
HashMap、HashTable、HashSet详解
hashmap和hashset笔记
hashmap和hashtable都实现了map接口,但是有以下不同点:
1.hashmap允许键和值是null,而hashtable不允许键或值是null。
2.hashtable是同步的,hashmap不是,因此hashmap适合单线程,hashtable适合多线程
3.HashMap是非synchronized,而Hashtable是synchronized,意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
4.另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器。HashMap可以通过下面的语句进行同步:Map m = Collections.synchronizeMap(hashMap);
5.hashtable是一个遗留的类
高并发下的hashmap
concurrenthashmap:
java1.7的ConcurrentHahmap
java1.8CAS乐观锁
源码分析Java8中ConcurrentHashMap是如何保证线程安全的
源码作图:ConcurrentHashMap如何实现高效地线程安全(jdk1.8)
非阻塞同步算法与CAS无锁
LinkedHashmap
HashMap和LinkedHashMap的继承关系。这两个类都实现了Map接口,同时LinkedHashMap继承于HashMap。
Map的设计思想就是以空间来换时间,主要用来存储键值对。键不可以重复,值可以重复。
HashMap
HashMap根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。 HashMap最多只允许一条记录的键为Null,允许多条记录的值为 Null,HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap,因为多线程操作Hash Map时,rehash时可能会导致数据的不一致,链表出现死循环的情况。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
LinkedHashMap
LinkedHashMap 是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比 LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
LinkedHashMap源码
Java中HashMap、LinkedHashMap和TreeMap区别使用场景
多次输出HashMap、LinkedHashMap和TreeMap结果
public class TestMap {
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
useHashMap();
// useTreeMap();
// useLikedHashMap();
}
}
public static void useHashMap() {
System.out.println("------无序(随机输出)------");
Map<String, String> map = new HashMap<String, String>();
map.put("1", "Level 1");
map.put("2", "Level 2");
map.put("3", "Level 3");
map.put("a", "Level a");
map.put("b", "Level b");
map.put("c", "Level c");
Iterator<Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Entry<String, String> e = it.next();
System.out.print("Key: " + e.getKey() + "; Value: " + e.getValue());
System.out.println();
}
}
// 有序(默认排序,不能指定)
public static void useTreeMap(){
System.out.println("------有序(但是按默认顺充,不能指定)------");
Map<String, String> map = new TreeMap<String, String>();
map.put("1", "Level 1");
map.put("4", "Level 4");
map.put("3", "Level 3");
map.put("a", "Level a");
map.put("b", "Level b");
map.put("c", "Level c");
Iterator<Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Entry<String, String> e = it.next();
System.out.print("Key: " + e.getKey() + "; Value: " + e.getValue());
System.out.println();
}
}
public static void useLikedHashMap() {
System.out.println("------有序(根据输入的顺序输出)------");
Map<String, String> map = new LinkedHashMap<String, String>();
map.put("1", "Level 1");
map.put("4", "Level 4");
map.put("3", "Level 3");
map.put("a", "Level a");
map.put("b", "Level b");
map.put("c", "Level c");
Iterator<Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Entry<String, String> e = it.next();
System.out.print("Key: " + e.getKey() + "; Value: " + e.getValue());
System.out.println();
}
}
}
多次结果都一样
------HashMap无序(随机输出)------
Key: 1; Value: Level 1
Key: a; Value: Level a
Key: 2; Value: Level 2
Key: b; Value: Level b
Key: 3; Value: Level 3
Key: c; Value: Level c
------Treemap有序(但是按默认顺充,不能指定)------
Key: 1; Value: Level 1
Key: 3; Value: Level 3
Key: 4; Value: Level 4
Key: a; Value: Level a
Key: b; Value: Level b
Key: c; Value: Level c
------LinkedHashMap有序(根据输入的顺序输出)------
Key: 1; Value: Level 1
Key: 4; Value: Level 4
Key: 3; Value: Level 3
Key: a; Value: Level a
Key: b; Value: Level b
Key: c; Value: Level c
红黑树
数据结构与算法
排序与二分查找
排序见 公众号文章收藏 [一份清晰又全面的排序算法攻略]
快排
归并排序
归并与快排
堆排序
希尔排序
直接选择排序
插入排序
二分查找:
大神整理的二分查找题目
满二叉树,完全二叉树和平衡二叉树
字典序算法
Base64算法
操作系统
linux grep的用法
linux问到查询大小为100Mb的文件
https://www.cnblogs.com/zknublx/p/10165676.html
linux 下查找大于100M的文件:find . -type f -size +100M
查看进程
https://www.cnblogs.com/wuyou/p/3357151.html
常用命令
https://blog.csdn.net/qq_38543396/article/details/80606733
https://blog.csdn.net/qq_39973449/article/details/81942754
rsync -e "ssh -p22 -i /home/data/.ssh/id_rsa_aliyun" -avzP root@47.104.213.82:/root/label_mission/recorder_server8084/recorder_server_data
计算机网络
DNS
常见面试题
IP地址子网划分
前后端交互
websockt前后端交互:
https://www.cnblogs.com/zhangruiqi/p/8215792.html
https://blog.csdn.net/github_39532240/article/details/85330232
https://www.cnblogs.com/lijuntao/p/6496906.html
http前后端交互:
https://www.cnblogs.com/loveheihei/p/10101257.html
http与websocket对比的优缺点:
https://blog.csdn.net/zq736122079/article/details/76850038
https://blog.csdn.net/liurwei/article/details/82348065
https://www.jianshu.com/p/730fe433cdd4
https://blog.csdn.net/nalnait/article/details/82049560
json传输与xml的优缺点
https://www.jianshu.com/p/243deb64bcb5
https://www.jb51.net/article/69598.htm
形成死锁的必要条件
https://blog.csdn.net/wsq119/article/details/82218911
https://www.cnblogs.com/zeze/p/9711792.html
https://blog.csdn.net/guaiguaihenguai/article/details/80303835
子网掩码的作用:
它有两个主要作用:一是屏蔽部分IP地址,区分网络标识和主机标识,解释IP地址是在局域网上还是在远程网络上;其次将一个大的IP网络划分为几个小的子网络。
子网掩码可以减少IP浪费。随着互联网的发展,越来越多的网络应运而生,有的是数百个,有的只是少数,浪费了大量的IP地址,因此有必要对子网进行划分,使用子网来提高网络应用的效率。
子网掩码设置成功后,网络地址和主机地址就固定了,与IP地址一样,子网掩码的长度为32位,也可以是十进制的。
osi
OSI七层模型与TCP/IP五层模型
OSI的7层从上到下分别是 7 应用层(TELNET,HTTP,FTP,NFS,SMTP) 6 表示层 5 会话层 4 传输层 (TCP,UDP)3 网络层 (IP,ARP,RARP协议)2 数据链路层 (mac地址,工作内容ARP,RARP)1 物理层
OSI七层模型的每一层都有哪些协议
进程和线程通信
进程间的几种通信方式的比较和线程间的几种通信方式
进程间通信:socket是跨机器,服务端和客户端。
接口
rest API
https://blog.csdn.net/D_estin_y/article/details/95069549
https://blog.csdn.net/hanruikai/article/details/82690730
java高级
OSGI
OSGI( 动态模型系统)
OSGi(Open Service Gateway Initiative),是面向 Java 的动态模型系统,是 Java 动态化模块化系
统的一系列规范。
- 动态改变构造
OSGi 服务平台提供在多种网络设备上无需重启的动态改变构造的功能。为了最小化耦合度和促使
这些耦合度可管理, OSGi 技术提供一种面向服务的架构,它能使这些组件动态地发现对方。 - 模块化编程与热插拔
OSGi 旨在为实现 Java 程序的模块化编程提供基础条件,基于 OSGi 的程序很可能可以实现模块级
的热插拔功能,当程序升级更新时,可以只停用、重新安装然后启动程序的其中一部分,这对企
业级程序开发来说是非常具有诱惑力的特性。
OSGi 描绘了一个很美好的模块化开发目标,而且定义了实现这个目标的所需要服务与架构,同时
也有成熟的框架进行实现支持。但并非所有的应用都适合采用 OSGi 作为基础架构,它在提供强大
功能同时,也引入了额外的复杂度,因为它不遵守了类加载的双亲委托模型。
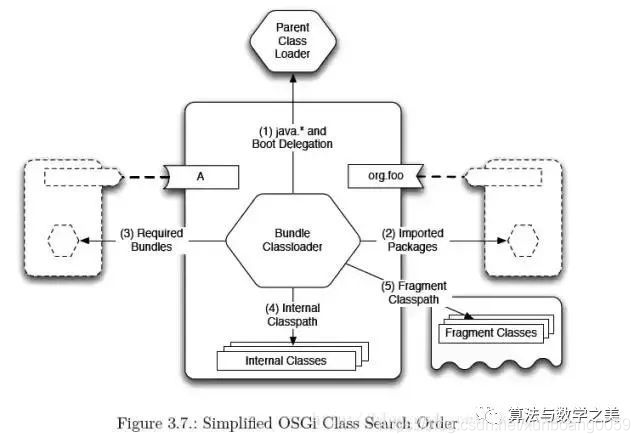
osgi类加载模型是网状的,可以在模块(Bundle)间互相委托
osgi实现模块化热部署的关键是自定义类加载器机制的实现,每个Bundle都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换
当收到类加载请求时,osgi将按照下面的顺序进行类搜索:
1)将以java.*开头的类委派给父类加载器加载
2)否则,将委派列表名单(配置文件org.osgi.framework.bootdelegation中定义)内的类委派给父类加载器加载
3)否则,检查是否在Import-Package中声明,如果是,则委派给Export这个类的Bundle的类加载器加载
4)否则,检查是否在Require-Bundle中声明,如果是,则将类加载请求委托给required bundle的类加载器
5)否则,查找当前Bundle的ClassPath,使用自己的类加载器加载
6)否则,查找类是否在自己的Fragment Bundle中,如果在,则委派给Fragment Bundle的类加载器加载
7)否则,查找Dynamic Import-Package(Dynamic Import只有在真正用到此Package的时候才进行加载)的Bundle,委派给对应Bundle的类加载器加载
8)否则,类查找失败
java高级面试题
tomcat反双亲委派
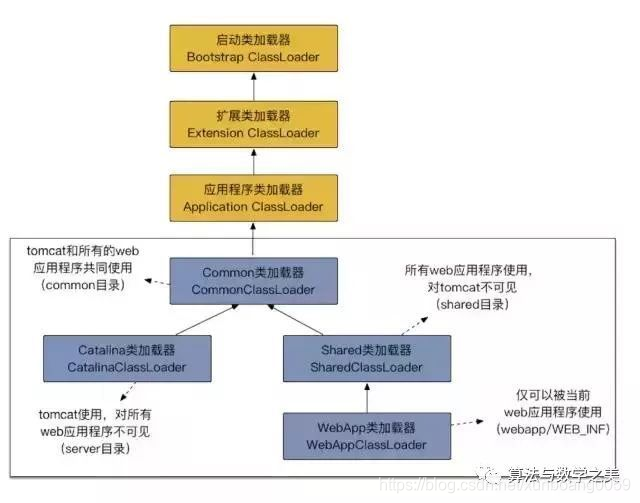
不同应用使用不同的 webapp类加载器,实现应用隔离的效果,webapp类加载器下面是jsp类加载器
不同应用共享的jar包可以放到Shared类加载器/shared目录下
Tomcat 类加载器之为何违背双亲委派模型
异常
Throw 和 throws 的区别:
位置不同
- throws 用在函数上,后面跟的是异常类,可以跟多个; 而 throw 用在函数内,后面跟的是异常对象。
功能不同: - throws 用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先的处理方式; throw 抛出具体的问题对象,执行到 throw,功能就已经结束了,跳转到调用者,并将具体的问题对象抛给调用者。也就是说 throw 语句独立存在时,下面不要定义其他语句,因为执行不到。
- throws 表示出现异常的一种可能性,并不一定会发生这些异常; throw 则是抛出了异常,执行 throw 则一定抛出了某种异常对象。
- 两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。














 1113
1113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









