







本文学习内容来自《大数据革命——理论、模式与技术创新》 电子工业出版社
传统的关系型数据库数据仓库在面对大数据的处理地显得越来越力不从心。在这样的背景下,NoSQL数据库应运而生。
CAP理论
2000年美国加州大学伯克利分析的Eric Brewer教授提出了CAP理论,即一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance),最多只能同时满足2个。
传统的关系型数据库属于CA模式,对分区容忍性的支持比较差。
对分布式数据库系统而言,分区容错性是基本需求,因此只有CP和AP两种选择。
CP模式
保证分布在网络上不同节点数据的一致性,但对可用性支持不足
- BigTable
- HBase
- MongoDB
- Redis
- MemcacheDB
- Berkeley DB
AP模式
主要以实现最终一致性来确保可用性和分区容忍性,但弱化了对数据的一致要求
- Dynamo
- Cassandra
- Tokyo Cabinet
- CouchDB
- SimpleDB
ACID和BASE方法论
ACID指的是关系型数据库为了支持事务(Transcation)的正确性和可靠性,必须满足4项特性:
- 原子性(Atomicity):一个事务中所有操作,要么全完成,要么全不完成
- 一致性(Consistency):事务开始前和结束,数据库的完整性没有被破坏
- 隔离性(Isolation):两个或多个事务并发访问
- 持久性(Durability)
传统的SQL数据库支持的是强一致性,也就是在更新完成后,任何后续访问都将返回更新过的值,为了实现ACID,往往需要频繁对库或表加锁。
对于很多Web应用,尤其是SNS应用来说,一致性可以降低,而对可用性的要求高。为了支持高并发读写,有些NoSQL产品采用了Eventually Consistency(最终一致性)的原则,从而产生了基于弱一致性的BASE方法论。
BASE:Basically Availabe(基本可用)、Soft-state(软状态)、Eventual Consistency(最终一致性),构成了大多数NoSQL数据库的方法论基础。
商业数据库的变革
很多商业数据库更多地是结合传统RDBMS技术和分布式及并行计算技术来处理大数据的需求。很多系统两袖清风从硬件层面来对数据处理进行加速。
- Greenplum
基于开源数据库PostgreSQL的分布式数据库,整个集群由很多个数据节点加上控制节点组成,其中每个数据节点上运行了很多个PostgreSQL数据库。数据在进入数据库时,首先要对数据分布的工作,即把一个表的数据尽可能均匀地分布到每个节点的库中。这样做的目的是充分利用每个节点的I/O能力 。 Greenplum真正发挥了并行无处不在的优势 ,在一个主机上同时启动多个PostgreSQl数据库。控制节点只承担少量的控制功能,以及和客户端的交互,完全不承担任何计算任务。 HP的Vertica
在很多方面 Greenplum接近,都是基于MPP架构。Vertical是采用列存储的数据库,尤其适合基于列的查询,如聚合操作。Vertical在查询和插入性能上较好,但在进行update和delete以及相关的事务处理时相对开销较大。Netezza和Exadata都是采用数据仓库一体机的方案。
NoSQL数据库分类
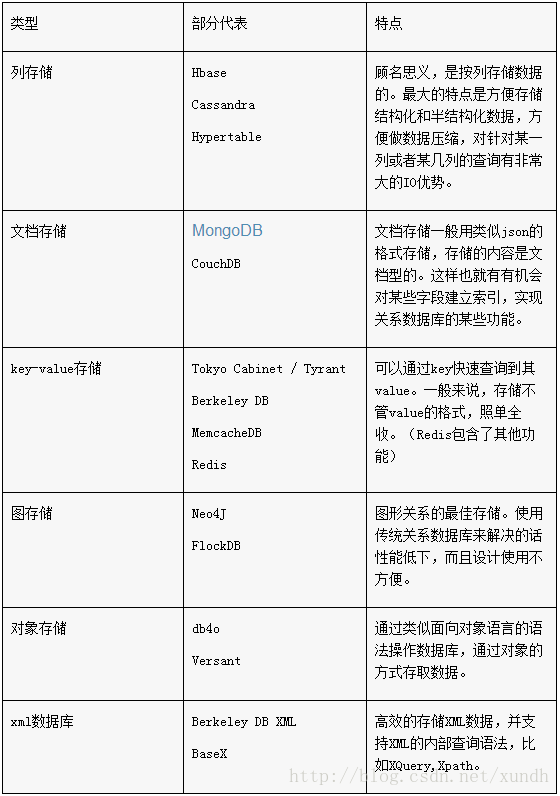
列式存储
BigTable
谷歌设计的一个存储和处理海量数据的非关系型数据库。包括3个主要的组件:客户端程序库、一个Master 主服务器和多个Table子表服务器。
BigTable是一个稀疏的、分布式的、多维的、排序的持久化映射。
Hbase
BigTable的开源实现,建立在HDFS之上。
Hbase使用和BigTable相同的数据模型,用户将数据按照行存储在一个数据表中,每一个数据行都有一个任意字符串的键值(Row key)及任意数据的列。类型相同或逻辑上关联的列进一步组成了列族(Column Family)。
列族是权限控制及列属性设置的基本单位,它必须在数据存储之前进行创建,如果要对列族进行修改,则需要在管理员权限下先停止表才可以进行。一般情况下,一个表的列族是相对固定的并且数量较少的。与此相反,HBase可以拥有任意多个列,并且可以在运行时动态创建。由于每一列都属于某个列族,因此列名通常可以写作family:qualifer的形式。此外,在HBase的每一个单元格中都可以存储多个版本的值,按时间戳递减排列,位于最上面的是时间最晚的版本,即最新值。HBase会定期删除过旧的版本,只保留较新的几个版本。键值、列名、时间戳共同确定了HBase中的一个值 。
HBase中的每一行数据,都严格按键键值的字母序排列。
HBase访问接口
- Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据
- HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用
- Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据
- REST Gateway,支持REST 风格的Http API访问HBase, 解除了语言限制
- Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计
- Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase
Cassandra
Facebook最初开发,用于储存收件箱等简单格式数据。2008年开源,一种流行的分布式结构化数据存储方案。
Cassandra是社交网络方面理想的数据库,以亚马逊专有的完全分布式的Dynamo为基础,而Cassandra的系统架构与Dynamo一脉相承,是基于DHT(分布式哈希表)的完全P2P架构,与传统的基于数据分片的数据库集群相经,可以几乎无缝地加入或删除节点。
文档存储
主要解决的问题不是高性能的并发读/写,而是保证海量数据存储的同时,具有良好的查询性能。目前主流的有:CouchDB和MongoDB。
key-value存储
主流的有Redis、Memcached、Voldemort、Tokyo Cabinet和Tokyo Tyrant(主要用于日本最大的SNS网站mixi.jp上)、Megastore等。
图数据库
以应用图形理论存储实体之间的关系信息,最常见的例子就是社会网络中人与人之间的关系。常见的有:
Neo4j、Tweitter的FlockDB和谷歌的Pregel等。
















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











