







一、前言说明
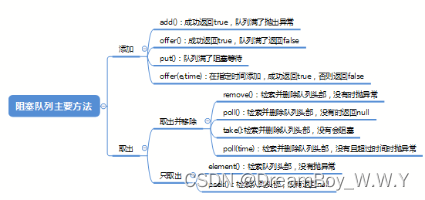
queue常见方法如下:
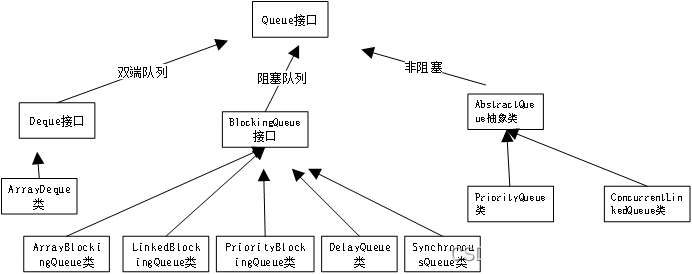
queue队列常见又分为阻塞和非阻塞,这篇文章,主要介绍常使用的几个队列:PriorityQueue、SynchronousQueue、LinkedBlockingQueue、DelayQueue。

二、LinkedBlockingQueue
LinkedBlockingQueue采用单向链表,两个Lock锁;
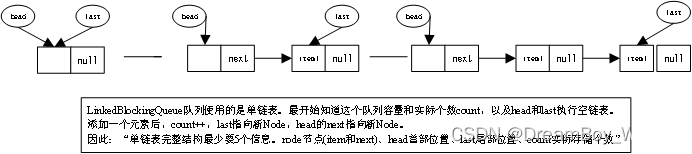
LinkedBlockingQueue队列主要有两个操作(添加和取出)。这里“添加”时有takeLock锁和notEmpty的Condition。“取出”时有putLock锁和notFull的Condition。
---- -链式队列,队列容量不足或为0时自动阻塞。
三、SynchronousQueue
SynchronousQueue也是有内存空间,当一个add线程添加数据,此时无take线程取数据,会阻塞等待,因此保持一对一通信原理。
四、PriorityQueue
PriorityQueue底层数据结构是数组,实现原理是堆(类似大顶堆/小顶堆)的实现,主要是插入和删除操作的堆化;
插入元素:从尾部插入,然后从下往上对parent调整堆化
取出元素:取出堆顶元素,然后取出最后一个元素放入堆顶,再从上往下对parent调整堆化
—堆的性质:父节点的值要么都大于/小于左右子节点,左右子节点之间没要求
五、DelayQueue
DelayQueue借助PriorityQueue队列【前面的分析:优先级队列在堆顶一定是优先级最高或最低,取出后,又进行堆化,重新把优先级最高或最低放入堆顶】。
(1)、延迟队列add()方法
先加锁,将数据加入PriorityQueue队列,如果是第一个元素,那么通知在等待队列中的take线程;
(2)、延迟队列take()方法
先加锁,先从PriorityQueue队列取第一个元素,计算出第一个元素的延迟时间,
如果时间到了,就弹出;如果延迟时间未到,会awaitNanos()阻塞等待被唤醒;
(3)、为什么设置leader字段
leadler在delayqueue里目的就是为了避免不必要的唤醒和睡眠。
线程A调用take(),在Ts后要被唤醒,因此应该awaitNanos(T),同理按照一般思路,线程B调用take()也是如此;
但这样的话,同一时刻有很多线程被唤醒但只有一个能够拿到资源,另一个被唤醒没意义,会继续睡眠【会浪费CPU资源】。所以有leader字段,
只要发现有leader了,那该线程就会直接await(),只会被signal()来唤醒。
















 981
981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











