









前面的遍历都没有关注路径本身,本节从两道题目着手,穴习一个图的遍历及路径。
首先了解几个概念。
1.欧拉通路:通过图(有向图或者无向图)中的所有边,且每条边只通过一次且行遍所有顶点的通路。
2.欧拉回路:当欧拉通路为回路时,称为欧拉回路。
3.欧拉图:具有欧拉回路的无向图。半欧拉图:具有欧拉通路但不具有欧拉回路的无向图。
简单来说,类似于[一笔画]问题。七桥问题是最早涉及这一问题的数学趣闻,有兴趣的可以了解一下 https://www.cnblogs.com/graytido/p/10421927.html
然后了解一下如何判断图是否具有欧拉通路或欧拉回路,整体来说和顶点的出度入度的奇偶性有关。
1. 无向图是否具有欧拉通路或回路的判定:
欧拉通路:图连通;图中只有2个度为奇数的节点(就是欧拉通路的2个端点)
欧拉回路:图连通;图中所有节点度均为偶数。
2. 有向图是否具有欧拉通路或回路的判定:
欧拉通路:图连通;除2个端点外其余节点入度=出度;1个端点入度比出度大1;一个端点入度比出度小1。
欧拉回路:图连通;所有节点入度=出度。
以上知识作为图论知识的重要补充,并且和下面这道题息息相关。
332. Reconstruct Itinerary
Given a list of airline tickets represented by pairs of departure and arrival airports [from, to], reconstruct the itinerary in order. All of the tickets belong to a man who departs from JFK. Thus, the itinerary must begin with JFK.
Note:
- If there are multiple valid itineraries, you should return the itinerary that has the smallest lexical order when read as a single string. For example, the itinerary
["JFK", "LGA"]has a smaller lexical order than["JFK", "LGB"]. - All airports are represented by three capital letters (IATA code).
- You may assume all tickets form at least one valid itinerary.
- One must use all the tickets once and only once.
题解:
从条件4可以看出,这是一道求解欧拉通路的题目。力扣中文官方有不错的解释,这里搬运并略微整理。
Hierholzer 算法
Hierholzer 算法用于在连通图中寻找欧拉路径,其流程如下:
从起点出发,进行深度优先搜索。
每次沿着某条边从某个顶点移动到另外一个顶点的时候,都需要删除这条边。
如果没有可移动的路径,则将所在节点加入到栈中,并返回。
我们结合下图和代码来理解这个算法:
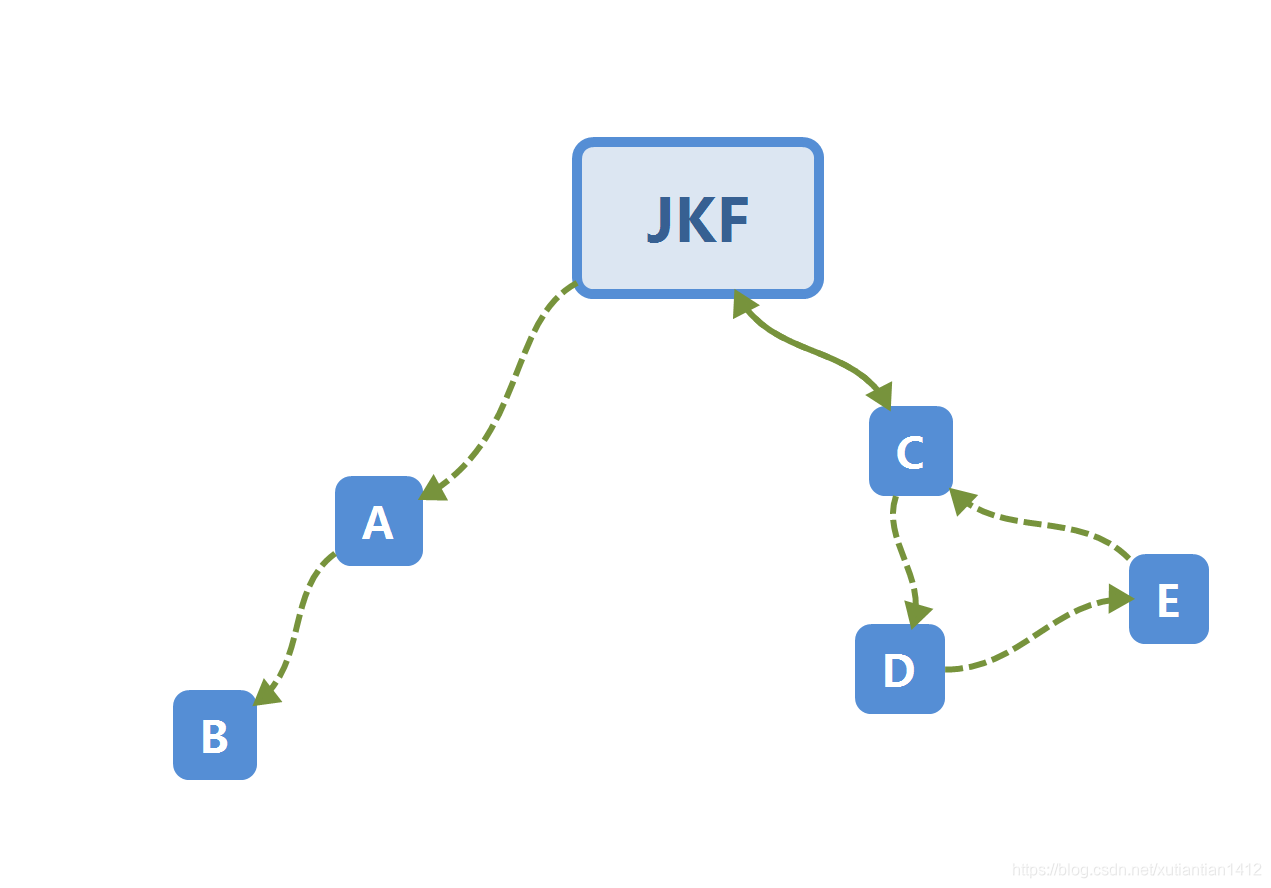
a . 首先处理一下基本信息,将边表示的图转化为邻接表,对于每个邻接表,按字典序排序,这里有人用堆来实现,不管怎样要方便我们后续代码每次取出字典序最小的邻居。
b . 递归调用dfs, 我们分两种情况理解。首先你应该意识到死胡同的概念,相当于欧拉图中 入度比出度大1 的顶点。 当我们恰好可以按字母序走完通路,或者没有死胡同或者刚好字母序大的在死胡同,这样会在最后一个终点时,一层一层结束递归调用并加入到stack,此时stack逆序就是路径;当我们按字母序会走入死胡同时,如图,B、A会首先结束递归依次如栈,然后走J - C另一个分支,不再赘述,最后这一分支走完一层层入栈,你会发现在stack 中 死胡同A-B在栈顶,最后stack逆序输出仍是路径。
c . 建议结合两三个例子自行看一遍,这一算法的关键就是,通过递归的特点 终点或死胡同会优先入栈。对于当前节点而言,从它的每一个非「死胡同」分支出发进行深度优先搜索,都将会搜回到当前节点。而从它的「死胡同」分支出发进行深度优先搜索将不会搜回到当前节点。也就是说当前节点的死胡同分支将会优先于其他非「死胡同」分支入栈。
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
def dfs(cur):
while graph[cur]:
dest = graph[cur].pop() # 默认弹出最后一个 即最小值
dfs(dest)
stack.append(cur)
from collections import defaultdict
graph = defaultdict(list)
for tic in tickets:
graph[tic[0]].append(tic[1])
for k in graph.keys():
graph[k].sort(reverse=True) # 原地排序 从小到大 --> reverse=True 从大到小
stack = []
dfs("JFK")
return stack[::-1]797. All Paths From Source to Target
Given a directed acyclic graph (DAG) of n nodes labeled from 0 to n - 1, find all possible paths from node 0 to node n - 1, and return them in any order.
The graph is given as follows: graph[i] is a list of all nodes you can visit from node i (i.e., there is a directed edge from node i to node graph[i][j]).
题解:
关注遍历路径第二题,有向无环图从点0到点n-1的所有路径。本质上还是深度优先搜索,递归求解所有路径。
解法:dfs, 理解递归一层一层的结果返回,然后将下一层(或者说邻接点)返回的路径加上当前顶点,构成当前顶点的所有路径。

class Solution:
def allPathsSourceTarget(self, graph: List[List[int]]) -> List[List[int]]:
n = len(graph)
def dfs(node):
ret = []
if node == n-1:
return [[n-1]]
for nb in graph[node]: # 0 的所有邻居
for solution in dfs(nb):
solution.append(node)
ret.append(solution)
return ret
result = dfs(0)
# 处理结果
result2 = []
for path in result:
result2.append(path[::-1])
return result2其实,所谓深度优先搜索,就是回溯算法,这一点我们之后会详细介绍算法思想、应用场景和框架,尤其是一些字符串的题目。下面的代码速度更快,思想与上面完全一致,关键是stack的使用。
class Solution:
def allPathsSourceTarget(self, graph: List[List[int]]) -> List[List[int]]:
n=len(graph)
res=[]
track=[]
def dfs(i):
track.append(i)
if i==n-1:
res.append(track[:])
track.pop()
return
for data in graph[i]:
dfs(data)
track.pop()
dfs(0)
return res














 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









