






java io流
前言
我为什么要重新整理IO流的知识?
文章目录
- java io流
- 前言
- 一. 为什么会有流的概念?
- 二. 输入流与输出流的概念
- 三. 使用流来操作文件
- 1.创建文件
- 方式一:new File(String pathName),指定文件路径来创建一个File对象,一个File对象就是一个文件
- 方式二:new File(File parent,String childFileName)
- 方式三:new File(String parentFileName,String childFileName)
- 2. 常见的文件操作
- getName:获取到文件的名字
- getAbsolutePath:获取到文件的绝对路径
- getParent:获取到文件的父级目录
- length:获取到文件的大小,这个大小是按照字节数来算的;这里要注意:不同的编码格式,英文,中文占用的字节数不同,在UTF-8中,一个中文占3个字节,1个英文,数字,符号占1个字节; 另外需要再提醒一下:1个字节等于8位,1位等于1个比特,千万不要记成1位等于8个比特了;
- mkdir:创建一级目录
- mkdirs:创建多级目录
- delete:删除空目录或者文件,只能删除空目录
- 四. IO流的分类
- 分类方式1:按照操作对象来分 >>> 字节流,字符流,字节流是操作的字节,字符流是以字符为单位进行操作的;字节流的效率更慢,因为它需要一个字节一个字节的操作,但是当它在操作二进制文件时,可以达到无损的效果,因为它本身就是操作的字节,每一个字节都能被操作到;而字符流是操作的字符,它更适合操作一些文本文件,像视频,音频等就不适合它操作;
- 字符流不适合操作二进制文件,适合操作文本文件,常见的二进制文件有哪些?音频,视频,doc文档,word文档,pdf这些都是二进制文件;
- 字节输入流:InputStream,字节输出流:OutputStream,字符输入流:Reader,字符输出流:Writer,这四个类都是顶级的抽象基类,你不能直接使用它们,而是需要使用它们的子类,java的开发者对这些类的开发十分的规范,假如是字节输入流的子类,那么这个子类就会以InputStream结尾,如果是字符输入流的子类,就会以Reader结尾,其他两个类推;
- 五. 字节输入流详解:InputStream常用子类
- 六. 字节输出流OutputStream及其常用子类
- 七. 字符流:字符输出流OutputStreamWriter,字符输入流:InputStreamReader
- 八. 节点流,包装流(也称处理流)
- 九. 缓冲流:BufferedReader,BufferedWriter,BufferedInputStream,BufferedOutputStream
- 十. 对象流:ObjectInputStream,ObjectOutputStream
- 1.序列化和反序列化:
- 2.要让某个对象能够支持序列化和反序列化,那么这个对象的类一定要实现以下两个接口之一: 我们推荐你使用Serializable接口
- ① Serializable
- ② Externalizable
- 3. 为什么推荐使用Serizable?
- 4.ObjectOutputStream提供序列化功能,ObjectInputStream提供反序列化功能
- ObjectOutputStream构造器:ObjectOutputStream(OutputStream stream)
- ObjectInputStream构造器:ObjectInputStream(InputStream stream)
- 5. 对象流使用案例:
- 使用对象流,将一个Dog对象保存到文件data.dat中,然后再将其恢复成Dog对象;
- 6.ObjectOutputStream api讲解:
- 7.ObjectInputStream api讲解:
- 8.对象流的注意点:输出与输入的顺序问题;
- 十一. 标准输入输出流
- 十二. 转换流:InputStreamReader,OutputStreamWriter;
一. 为什么会有流的概念?
首先在电脑中,我们的数据最终是要落在磁盘上的,落在磁盘上的形式最终就是以文件形式存在的,如果没有文件,你的数据如何存放呢?显然没有地方存;所以总结出来数据最终是落在磁盘的文件上,但是我们要得到这些数据,把它读到内存中,或者把内存中的数据写到磁盘的文件中,那到底该如何操作呢?
流就是专门用来操作文件的一种工具,java就是通过流来操作文件的,当你也不可以不用java的流,也可以自己写一套代码来操作文件而不用jdk的流,但是这涉及到的东西就比较底层了,不太好写;
二. 输入流与输出流的概念
输入跟输出都是相对于内存而言的,如果数据是从内存到磁盘,那么就是输出流,如果是从磁盘到内存,那么就是输入流;
这里其实需要补充一下,只要数据是从内存出来到其他地方,就称为输出流,不仅仅是磁盘,比如:当你在进行TCP编程时,客户端一方的socket会将数据通过输出流写到网络的管道中,然后传递给服务端,这里的数据就不是从内存到磁盘了,而是从内存到网络,它也叫输出流,我在工作中发现有很多人对这个概念搞不清楚,所以特此记录;
再补充一下,socket肯定是属于内存一方的,因为它实质上来说也只是一个类;
三. 使用流来操作文件
1.创建文件
方式一:new File(String pathName),指定文件路径来创建一个File对象,一个File对象就是一个文件
File file = new File("D:\\test\\newFile.txt");
try {
boolean result = file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
这里唯一需要注意的是:
① 在windows中文件目录是用" \ “隔开的,这个符号在java中要进行转义,所以这里的new File的是(“D:\test\newFile.txt”);
但是其实java的IO包是对” / "也做了兼容的,你使用File file = new File(“D:/test/newFile.txt”)也能创建出File对象,且不用转义字符;
② 当你把File new出来后,并不代表这个文件在磁盘中创建出来了,你只是创建出了一个File对象,你需要再调用file实例的createNewFile函数才能创建出文件;深入理解一下:你new出来的File,这个file对象只是存在于内存之中,这个对象还没有跟硬盘发生任何关系,只有当你调用createNewFile函数,这个函数中才会在磁盘中创建文件;
方式二:new File(File parent,String childFileName)
File parentFile = new File("D:\\test");
String fileName = "newFile.txt";
try {
File file = new File(parentFile ,fileName);
boolean result = file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
方式三:new File(String parentFileName,String childFileName)
2. 常见的文件操作
getName:获取到文件的名字
getAbsolutePath:获取到文件的绝对路径
getParent:获取到文件的父级目录
length:获取到文件的大小,这个大小是按照字节数来算的;这里要注意:不同的编码格式,英文,中文占用的字节数不同,在UTF-8中,一个中文占3个字节,1个英文,数字,符号占1个字节; 另外需要再提醒一下:1个字节等于8位,1位等于1个比特,千万不要记成1位等于8个比特了;
mkdir:创建一级目录
mkdirs:创建多级目录
File file = new File("D:\\a\\b\\c");
try {
boolean result = file.mkdirs();
} catch (Exception e) {
e.printStackTrace();
}
注意:当你要在D盘下创建多级目录,比如创建一个a目录,a目录中又创建b,创建c的话,你就只能使用mkdirs,如果使用mkdir是会报错的,mkdir只能创建一级目录,像"D:\a")这种就是一级目录,因为只需要创建出a这一级,但是mkdirs不仅仅可以创建多级目录,还可以创建一级目录,所以mkdirs更好用;
delete:删除空目录或者文件,只能删除空目录
四. IO流的分类
分类方式1:按照操作对象来分 >>> 字节流,字符流,字节流是操作的字节,字符流是以字符为单位进行操作的;字节流的效率更慢,因为它需要一个字节一个字节的操作,但是当它在操作二进制文件时,可以达到无损的效果,因为它本身就是操作的字节,每一个字节都能被操作到;而字符流是操作的字符,它更适合操作一些文本文件,像视频,音频等就不适合它操作;
字符流不适合操作二进制文件,适合操作文本文件,常见的二进制文件有哪些?音频,视频,doc文档,word文档,pdf这些都是二进制文件;
字节输入流:InputStream,字节输出流:OutputStream,字符输入流:Reader,字符输出流:Writer,这四个类都是顶级的抽象基类,你不能直接使用它们,而是需要使用它们的子类,java的开发者对这些类的开发十分的规范,假如是字节输入流的子类,那么这个子类就会以InputStream结尾,如果是字符输入流的子类,就会以Reader结尾,其他两个类推;
五. 字节输入流详解:InputStream常用子类
1.FileInputStream 文件字节输入流
这个流是专门用来将文件内容读到内存中的,因为是输入流,所以是读取到内存,又因为是InputStream所以是字节流;
FileInputStream的构造函数:
① FileInputStream(File file):指定一个File对象,表示你具体要读取哪一个文件,这样就可以构建出针对该文件的文件字节输入流对象;
② FileInputStream(String fileName):指定文件的路径,你也可以创建出针对该文件的文件字节输入流对象;
2. FileInputStream的api:
① int read:使用fileInputStream实例从文件中读取1个字节
这里值得注意的是:read函数会返回一个int值,当这个值等于-1时,就表示已经读到了文件的末尾,不能再读了;
深入一下:假如你的在读一个txt文件,文件内容是hello,如下:

当你第一次调用read函数,返回的int值到底是什么呢?其实是h这个char字符按照ASCII码转成的int值,
h在ASCII码中的int值为104,所以你得到的就是104,你将int强转为char,那么你就会得到字母h;
h在UTF-8中是一个字节,int占4个字节,所以这里使用int来装是完全装的下的(但我真不知道为啥不用char装,反而要用int装,显然用int装会造成空间的浪费)
②int read(byte[ ] b):使用fileInputStream实例从文件中一次性读取一个字节数组,读取的字节数为字节数组的长度;
这个方法跟read()的返回值不一样,这个方法返回的int值,就是本次读取到的字节数,比如你new了一个byte数组,指定长度为1024,byte【】 b = new byte【1024】;意思就是fileInputStream实例每次从文件中读1024个字节,然后将这1024个字节装入到刚才创建的字节数组b中,因为我们刚才创建的字节数组b实际上只是一个空的数组;
然后我们每次读1024个字节,一般肯定不指读一次,因为一般的文件很可能不止1024个字节,所以你每次读出来后,你就要将读出来的字节从字节数组中取出来,比如转成字符串也可以,如何转?
利用String的有参构造new String(byte【】b,int offset,int length)即可转成字符串,int offset表示你要从字节数组的那一个下标开始转,int length表示你要转的长度,到底要将多少字节转成字符串;
另外注意1:假如你最后一次读取的字节数并没有到1024个字节,那么这个返回值int就不是1024了,而是实际最后一次读到的字节数;
注意2:int read(byte[ ] b)这种方式也会将文件内容转成int类型的值,只不过它将结果放到byte数组里面去了,比如它将h转成104放入了byte数组的第一位中;这是它跟read()的区别;
注意3:String的有参构造除了new String(byte【】b,int offset,int length),
你还可以使用new String(byte【】b,int offset,int length,String charsetName)来指定到底用哪一种编码格式;
2.BufferedInputStream:缓冲字节输入流
3.ObjectInputStream:对象字节输入流
六. 字节输出流OutputStream及其常用子类
1. FileOutputStream
api:
① void write(int b)
② void write (byte【】 b)
注意:FileOutputStream在往文件中写数据时,如果这个文件不存在,那么它会创建这个文件
七. 字符流:字符输出流OutputStreamWriter,字符输入流:InputStreamReader
文件字符输入流 FileReader:从文件读到内存
文件字符输出流FileWriter:把内存的数据写到文件
1.FileWriter的构造器:
①FileWriter(File file)
②FileWriter(String filePath)
③FileWriter(File/String , boolean 是否开启覆盖);
这里唯一值得注意的是第三个构造器,如果后面的布尔值为true,就表示开启追加模式,如果你本身这个文件里面就有数据了,你继续使用FileWriter往里面写数据时,就往里面追加;但如果不为true,你每往里面写一个字符,它就会覆盖一个原文件的字符,前两个构造器就默认为false;
八. 节点流,包装流(也称处理流)
1.节点流概念:
从一个特定的数据源读写数据,就称为节点流,(数据源就是存放数据的地方)
1)如FileReader,FileWriter,FileInputStream,FileOutputStream等就是针对文件这一特定数据源操作的节点流;
2)还有其他数据源,比如数组,你要操作数组这一特定数据源时,还可以使用ByteArrayInputStream,ByteArrayOutputStream:这两种是按照字节的方式操作数组,还可以使用CharArrayReader,CharArrayWriter按照字符的方式来操作数组;
3)如果数据源是字符串,你还可以使用StringReader,StringWriter来操作;
4)如果数据源是管道:你还可以使用PipedInputStream,PipedOutputStream按照字节的方式操作管道,还可以使用PipedReader,PipedWriter按照字符的方式操作管道;
2.包装流概念:对节点流进行了一个包装,对节点流进行功能增强,如读取写入的性能提高;
注意点:当你使用处理流对节点流进行包装后,你只需要关闭处理流即可,处理流的close方法会自动调用被它包装的节点流的close方法;
九. 缓冲流:BufferedReader,BufferedWriter,BufferedInputStream,BufferedOutputStream
BufferedReader中有一个属性是Reader,只要你这个节点流是Reader的子类,BufferedReader都能对其进行包装;
同理,BufferedWriter中也有一个属性是Writer,只要你这个节点流是Writer的子类,BufferedWriter都能对其进行包装;
十. 对象流:ObjectInputStream,ObjectOutputStream
对象流是专门用来处理对象的;
在实际的开发中,我们在保存一个数据的值到文件或者其他地方时,比如我要保存一个int 类型的100到文件中,我除了想把值100保存到文件,我还想把这个100的数据类型int也保存进去,以便我们下次读取时,直接把100恢复成int 100,而不是恢复成其他什么的字符串100,这种时候就需要使用对象流;
其实对象流的特点,就是在传输数据时,可以将基本数据类型或对象进行序列化和反序列化,所以它可以保存对象;
1.序列化和反序列化:
将一个对象保存下来(保存了这个对象中各个属性的值,并且还保存了这个对象的类型),这就叫序列化;
把这些值跟类型恢复成一个对象,就叫反序列化;
2.要让某个对象能够支持序列化和反序列化,那么这个对象的类一定要实现以下两个接口之一: 我们推荐你使用Serializable接口
① Serializable
② Externalizable
3. 为什么推荐使用Serizable?
首先我们查看Serializable接口源码,我们发现它里面任何方法都没有,也就是说它本身不具备任何作用,但是扩展一下:在jdk的源码中,java的开发者们是把Serizable接口作为一个标记来使用,当它检测到你一个类是Serizable的实现子类,那么它就会让这个类支持序列化与反序列化;用一个接口作为标记这样的好处是:几乎不会对原来的类造成任何影响,因为根本没有什么方法让你去重写;
而Externalizable接口也是继承自Serizable,但是它里面就有两个方法需要我们去重写,我们只是想让一个类支持序列化跟反序列化,就没有必要去重写它,所以我们推荐使用Serizable;
① 在实现Serizable接口时,我们推荐你在序列化的类中添加serialVersionUID,来增强版本的兼容性,这个到底有什么用?
举个例子:
public class Dog implements Serializable {
private String name;
private int sex;
}
比如你上面这个Dog类实现了Serializable 接口,但是没有加serialVersionUID,那么当有一天你往这个Dog类中加了任何一个属性或方法时,在序列化和反序列化时它就不认识它了,它就认为这是一个全新的类;这会导致你之前序列化出来的数据明明就是Dog类型,你想要反序列化成加了属性的Dog类,它就死活无法反序列化成功,因为它认为这根本就不是同一个类;
public class Dog implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private int sex;
}
当你加了serialVersionUID 后,那么它就可以凭借这个serialVersionUID 来判断你到底是不是同一个类了;所以你可以把serialVersionUID 的值写的特殊一点,不一定非要是1;
②关于序列化的注意事项1:当一个类的属性被static修饰,或被tansient关键字修饰,或被@Transient注解修饰,那么这个属性不会参与序列化;
就像下图中的color,nation属性都不会参与序列化

③关于序列化的注意事项2:当你要序列化一个对象时,要求这个对象里面的属性也必须实现序列化接口,否则无法序列化成功,会报错;
这里要注意:像那些常见的数据类型,int,boolean,Integer,String等都是已经实现过序列化接口的了,所以你平时在序列化一个带有这些基本类型属性的对象时才会没有问题;当你这个对象里有一个自定义类型的属性时,你也需要将这个自定义类型实现序列化接口,否则无法序列化成功;
④ 序列化具备可继承性,假如一个类实现了序列化接口,那么它的所有子类都是默认实现了序列化;
4.ObjectOutputStream提供序列化功能,ObjectInputStream提供反序列化功能
ObjectOutputStream构造器:ObjectOutputStream(OutputStream stream)
ObjectInputStream构造器:ObjectInputStream(InputStream stream)
对象流也是处理流,底层都是采用的修饰器模式进行编写的,所以这些处理流都是对节点流进行增强,那么它们的构造函数都是接收节点流接口的参数,比如ObjectOutputStream(OutputStream stream),只要你传进来的是字节输出流的子类就可以;
5. 对象流使用案例:
使用对象流,将一个Dog对象保存到文件data.dat中,然后再将其恢复成Dog对象;
注意点① :这里为什么是保存到.dat格式的文件中,为什么不保存到txt格式中?为什么不能我随便取一个文件后缀,保存data.a,data.b中?
这里你使用那些txt格式,或者其他格式都没什么用,因为这种对象类型的数据在保存到文件时,它会使用自己格式来保存数据,而不是根据你这个文件的后缀格式来保存,所以说,你文件是啥后缀没有用,但是用.dat只作为后缀是可以的,虽然我也不知道.dat后缀的文件是个啥,记住就好了;
Dog dog = new Dog();
dog.setName("大黄");
dog.setSex(1);
try {
File file = new File("D:\\test.dat");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(file));
objectOutputStream.writeObject(dog);
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(file));
Dog dog1 = (Dog)objectInputStream.readObject();
System.out.println(dog1);
objectInputStream.close();;
objectOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
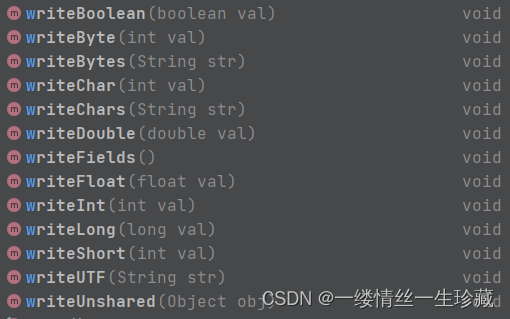
6.ObjectOutputStream api讲解:
1)write(int var),write(byte【】 b),这两个api在往内存外写数据时,是没有保存数据的类型的,比如你写一个write(100),那么就真的只是100,你反序列化的时候就得不到它的类型int;
2)其他方法名像writeInt,writeBoolean这种,你使用这种方法去写数据时,就会把数据类型也一并写进去,这里面没有writeString方法,你要写字符串的话,可以使用writeUTF或者writeChars
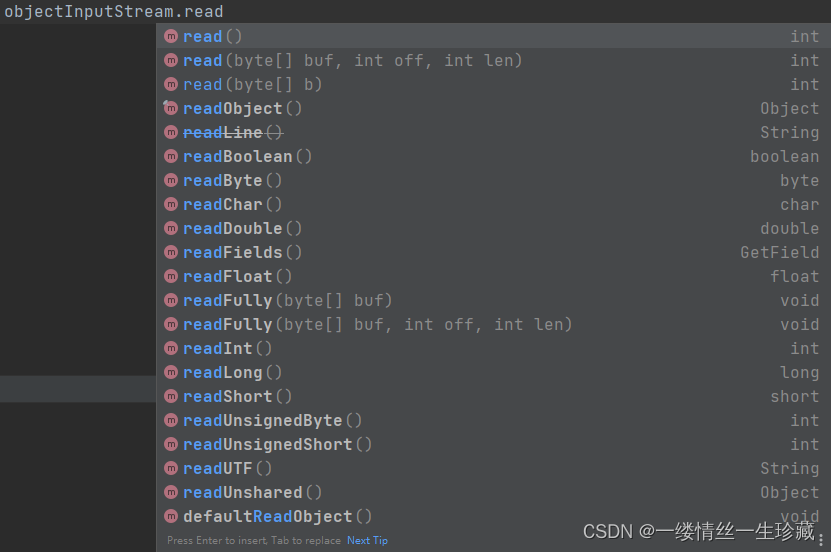
7.ObjectInputStream api讲解:
我们能看到ObjectInputStream 的read方法跟ObjectOutputStream 的write方法差不多,也有像readInt,readBoolean这种专门用来读取特定类型的方法;
8.对象流的注意点:输出与输入的顺序问题;
使用对象流,往某个地方输出数据时,比如你第一次输出了一个int,第二次输出了一个Dog,第三次你输出了一个Boolean,那么你在使用输入流来读取时,你也需要按照顺序读取,否则会出错;
比如看以下案例:
你往外输出时,是按照Int,Dog,Boolean的顺序进行输出的;
objectOutputStream.writeInt(100);
objectOutputStream.writeObject(new Dog("大黄",1));
objectOutputStream.writeBoolean(true);
那么你在进行输入时,你也需要按照Int,Dog,Boolean的顺序进行读取;
int t = objectInputStream.readInt();
Object o = objectInputStream.readObject();
boolean b = objectInputStream.readBoolean();
十一. 标准输入输出流
十二. 转换流:InputStreamReader,OutputStreamWriter;















 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









