







刚才看到一个消息,说程序员干到三十五岁就要被开除了。谁都有自己的黑暗时刻,成年人的世界没有童话镇,当然也没有魔鬼屋,有的只是光怪陆离和走马观花。
让自己不会被抛弃的唯一方法就是不断增加自己的价值,增加自己的权重。
abstract
细粒度识别的关键是 找到那些细微但是却具有标识性的特征。已经存在的Attention方法可以定位标识区域,并且放大,学习它们的细节。但是,这种方法很多都受困于 part 的数量多少和计算复杂的问题。我们提出了一个方法,能够从数百个 proposal 中,学习细粒度特征的方法:Trilinear Attention Sample Net(TASN),这种方法采用的是一种高效率的导师方法。
TASN包含三个部分:
- trilinear attention模块:对通道间的关系,进行建模,产生 attention map。
- attention-based sampler:强调被关注的高分辨率 part。
- feature distiller,特征蒸馏器:通过权重共享和 feature preserving 策略,将对个 part feature 整合成一个 object 级的特征
introduction
细粒度识别重在识别种类之间的细微差异。标识区域太过于细微,传统的CNN无法很好的去表达。现有的 attention 方法都是基于区域检测、裁剪放大、特征学习这中基本的套路。这个套路存在的问题:
- attention part 的数量是固定的,这会影响模型的有效性和稳定性;
- 不适用标记信息,很难学习到一个一致的 attention map,尽管一些初始化方法可以改善鲁棒性,不过仍然很难处理一些不常见的 pose。【大概意思是,由于物体的姿势、光照等,对 attention map 会产生影响,造成同类样本之间的 attention map 不一致】;
- CNN 如果对每个 part 都识别,是很不高效的;
这些问题是 attention model 的瓶颈问题。
TASN 可以学习上百个 proposal,并且可以有效的蒸馏这些特征,放入进一个单独的 CNN。
首先,trilinear attention module:输入是 feature map,通过 self-trilinear product,生成 attention map。这个过程是将 feature map 和关系矩阵进行集成。由于 feature map 的每个通道都可以被映射为一个 attention map,所以可以产生数百个 attention map。
然后,attention-based sampler:它的输入是 attention map 和图片,使用高分辨率强调 part。每个 iteration 后,sampler 会随机选择一个 attention map,生成一个保留细节的图片,和 使用一个平均后的 attention map,生成一个保留结构的图片。前者学习到一个特别的细节特征,后者抓住整体结构,学习到重要的细节。
最后,Part-net 和 Master-net 可以比作 teacher-net 和 student-net 。Part-net 从保留细节的图片中学习到细粒度特征,然后蒸馏学习到的特征到 Master-net中。Master-net 的输入是保留整体的图片,在每个 iteration 中重新完善某个 part。这样蒸馏过程就可以使用权重共享和特征保留完成。我们采用特征蒸馏的方式是引用[]。采用的原因是 part feature数量是不固定的,直接 concatenate 是行不通的。
特征蒸馏是通过优化参数,从 Part-net 知识迁移到 Master-net :
- 随机细节特征优化(在每个 iteration 只优化一个 part)实现数百个 proposal 中学习细节特征;
- 在 test 阶段,可以使用 Master-net 进行高效的识别。
这是第一次将蒸馏学习应用在细粒度识别上。
Method
TASN 可以使用一个网络,从而表达出丰富的细粒度特征。TASN的三个 module :定位、抽取、细节优化。
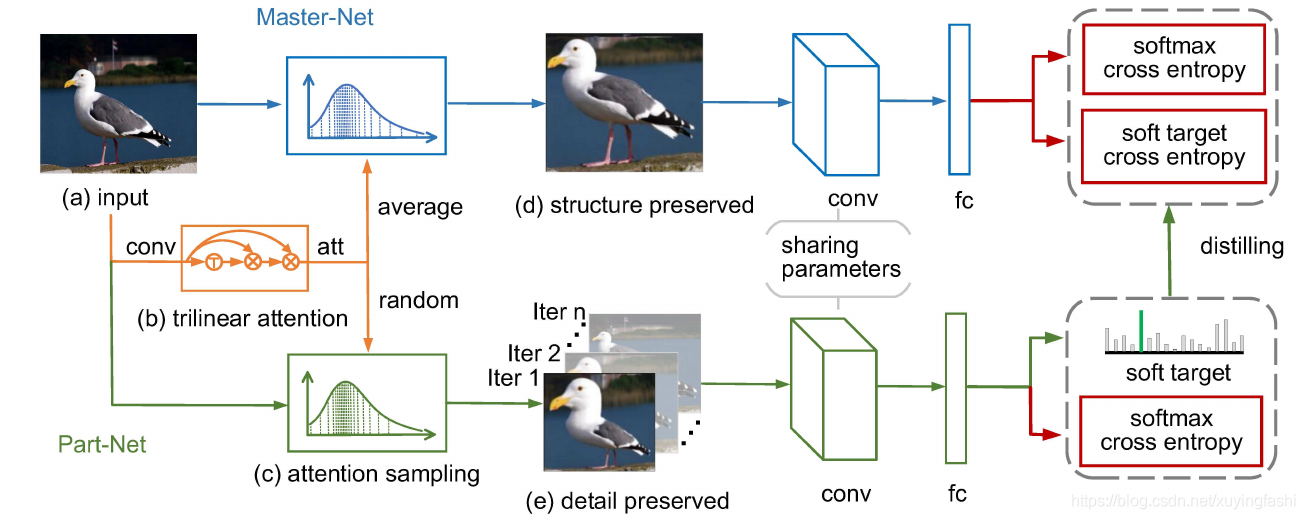
上图是 TASN 的大致过程,首先,图片会经过几个卷积层,获得 feature map(a),feature map 将在 trilnear attention module(b) 被映射为attention map。为了学习到某一区域的细粒度特征,我们将会随机的选择一个 attention map,并且使用它对图片进行 attention sampling©。采样后的图片叫做 detail-preserved 图片(e),它保留某一区域的细粒度特征。为了获取全局结构,并且获得重要的细节,平均所有的 attention map 并且使用这个 attention map 进行采样,得到的图片叫做 structure-preserved 图片。随后, Part-net 使用 detail-preserved 图片进行训练,Master-net 使用 structure-preserved 图片(d)进行训练。最后, Part-net 产生的 soft target 用于 Master-net 的知识蒸馏,损失函数是 soft target cross entory。
Trilinear Attention 的区域定位
trilinear attention 将 feature map 映射为 attention map。之前的很多工作都认同这样一个观点:feature map 的每个 channel 都和一个视觉模式(visual pattern)相关联。由于它们缺乏一致性和鲁棒性,所以这些通道是不能作为 attention map的。[40]的启发下,我们将 feature map 进行整合,映射为 attention map,这个整合映射的方法就是 trilinear attention module。
图像
I
I
I经过数个卷积层、BatchNorm层、ReLu层和池化层,我们使用的是Resnet-18作为 backbone 网络。为了获得更高的分辨率,我们把 resnet-18 中的一些 down sample 层给去除了(修改 stride 值,恒等卷积)。为了增加卷积响应的鲁棒性,我们增加了两个空洞卷积,扩大视野域。在训练阶段,我们还增加了一个分类器,优化卷积特征提取【应该增加一个单纯的损失】。
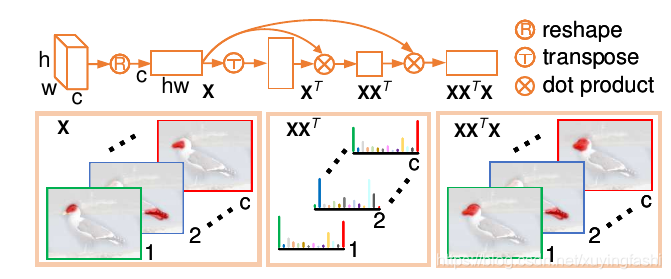
这个图给的还是很清楚的。
X
∈
R
c
∗
h
∗
w
r
e
s
h
a
p
e
X
{
X
1
,
X
2
.
.
.
X
c
}
∈
R
c
∗
h
w
X
X
T
∈
R
c
∗
c
:
X
i
X
j
T
∈
R
X
X
T
X
∈
R
c
∗
h
w
X \in R^{c*h*w} \ \ reshape\ \ X \{X_{1},X_{2}...X_{c}\} \in R^{c*hw} \newline \ \newline XX^{T} \in R^{c*c}: X_{i}X_{j}^{T} \in R \newline \ \newline XX^{T}X \in R^{c*hw}
X∈Rc∗h∗w reshape X{X1,X2...Xc}∈Rc∗hw XXT∈Rc∗c:XiXjT∈R XXTX∈Rc∗hw
这就是 attention map 获得三个公式。第一个公式,将 feature map
X
X
X 改变形状为 chw,实际上就是把每个通道变成一个 vector;第二个公式是求解 各个通道之间的关系;第三个公式,将通道之间的关系作用在 feature map 上【这节有点懵逼】,就得到了 attention map。作者认为这样做可以增强 attention map 的一致性和鲁棒性。
另外,作者研究不同的正则方法,提高 trilinear attention 的效果。分析过程会在下一节给出,结论如下:
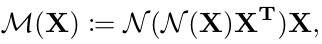
两个正则化都是对第二个维度的正则化,但是含义不同。第一个正则化是对每个通道的 feature map 进行正则化;第二个正则化,对每个 vector 对其他 vector 关系的正则化。
得到的
M
(
X
)
M(X)
M(X) reshape为 chw,那么每个通道的 feature map 的 size 就是 hw, 这就是每个通道的 attention map。
attention-based sampler
attention-based sampler 的输入是 attention maps,生成一个 structure-preserved图片 以及一个 detail-preserved 图片。相较于原始图片,这个 structure-preserved 图片移除了大部分没有标识信息的区域,因此,标志区域可以被很好的表达,而 detail-preserved图片 聚焦在一个标识区域,有着更多的细粒度信息(该区域的)。
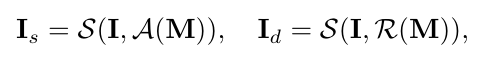
I
I
I 表示输入图片,
I
s
I_{s}
Is 表示 structure-preserved图片,
I
d
I_{d}
Id 表示 detail-preserved图片;
S
(
)
S()
S() 非均匀采样方式,
A
(
.
)
A(.)
A(.) 表示对所有 attention maps 的平均池化,
R
(
.
)
R(.)
R(.) 表示从所有 attention maps 中随机选择一个 attention map。我们使用 平均后的 attenion map 采样生成 structure-preserved图片,使用 随机选择的 attention map 采样生成 具有某个区域细节的 detail-preserved图片。随着训练,每个 attention map 都可以参与训练,那么不同的细粒度标识区域就可以异步的学习。
采样:我们对于采样的ideal是把 attention map 看做一个概率密度函数,attention value值 越大的区域越容易被采样。我们借鉴 inverse-transform[6] 的方法,通过计算分布函数的逆函数进行采样。为了减少空间扭曲,我们把 attention maps 分为两个维度。
例如 structure-preserved采样【我没有找到相关的细节解释和原理,这段公式是我自己的理解】:
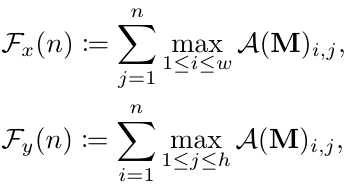
w
w
w 和
h
h
h 是 attention map 的长和宽,首先将图片拆解为 x 轴和 y 轴两个维度,
m
a
x
(
.
)
max(.)
max(.) 比
s
u
m
(
.
)
sum(.)
sum(.) 更有鲁棒性,这个是在计算积分:
我自己画了个草图,尝试理解这个 sampling:
这个积分应该是逐渐的增大的, F − 1 F^{-1} F−1 是 F ( . ) F(.) F(.) 的逆函数。也就是,建立 attention map 和 原图之间的一个映射。也就是寻找 (i, j) 位置等值的 max积分值,把这个 max积分值 对应的 n值 作为坐标,在原图中取像素。【这样取像素之后,梯度信息怎么传递?】
知识蒸馏
知识蒸馏很好理解:
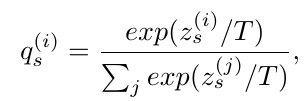
q
s
q_{s}
qs 代表 structure-preserved图片 的分类损失,
q
d
q_{d}
qd 代表 detail-preserved图片 的分类损失,上面的公式是一个 soft损失函数,但是与其他不同的是,作者说
T
T
T 是一个很关键的参数在知识蒸馏过程中,影响着 soft的概率分布。【不是很明白】
知识蒸馏损失:
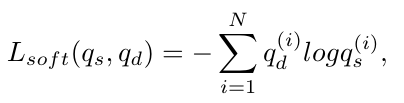
因此 Master-net的损失函数:
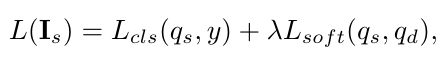














 3454
3454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









