







“这是我认真看的第一篇细粒度的论文,从这儿出发!”
摘要
特征部件的精确特征表达在细粒度识别中扮演着很重要的角色。例如专家仅仅依靠物体部件,根据自己的专业知识,就能很好的识别物体。这篇文章提出了一个新的方法“打碎重构”(Destruction and Construction Learning)DCL解决细粒度识别难度,获取专家知识。
引言
普通的图像识别已经获得了很大的成功,然而细粒度图像识别仍然很有挑战。尽管细粒度图像咋看之下一样,但是仔细的识别**标识区域(discriminative local regions)**就能判断出来。
标识区域特征在细粒度识别过程中至关重要,已经存在的细粒度识别方法分为两种:
a). 定位标识区域,然后根据标识区域分类。这种方法需要bbx(定位标记),花费比较大;
b). 使用注意力机制以无监督的方式自动定位标志区域,不需要额外的标注。但是需要注意力机制的方法都需要额外的注意力网络,额外的计算花费。
在这篇文章中,我们提出了DCL方法,除了标准的分类网络外,我们引入DCL模块自动学习标志区域。首先,为了强调标志区域细节,将输入图片打散;然后,重构这个图片,建模区域之间的联系。一方面,DCL可以自动的定位标志区域,不需要额外的标注;另一方面,DCL只在训练过程中被更新,不会在推断过程引入计算量。
Destruction:我们使用 **区域混乱机制(RCM,Region Confuse Mechanism)**故意打乱全局结构,将图片划分为若干个局部块,然后随机打乱(它们的顺序)。对于细粒度识别而言,局部细节往往是很重要的,因为来自不同的细粒度种类的图片,往往有着相似的整体结构或形状,但是却在局部细节上有着很大的不同。忽略整体而让网络关注标识区域。打乱是借鉴NPL中的方法。如果图像是错序的,对细粒度识别不重要的不相关的区域是会被忽略,网络会主动依据标识区域的细节进行分类。使用RCM,图像的视觉外观会有很大改变。如下图,尽管它变得更加难以识别,鸟类专家仍然能够很轻易的发现重点,相似的,神经网络需要学习到专家知识,来区分重构后的图像。
注意,destruction并不是总有意义的,RCM引入几种嘈杂的视觉模式【这个不是很能理解】。为了抵消这种负面影响,使用对抗损失,区分原始图像和重组图像。结果,noisy pattern可以被最小化,尽量保留了有意义的局部特征。从理念上将,对抗损失和分类损失相互对抗,尽可能识别“破碎的图像”。
Construction:图像对齐网络为了重新整齐“破碎的图像”,通过学习恢复原始的布局,网络需要理解每个区域的语义信息,包括那些标识区域。通过“constrcution”,两个不同区域的联系可以被很好的表示、建模【想不到很好的词翻译】。
贡献:
- DCL框架,“deconstruction”:RCM让网络学习到标识区域,对抗损失组织过拟合的RCM引入noisy pattern。“construction”:对齐网络通过建立区域间的联系,重新排序被破坏的图像。
- DCL的性能很好
- DCL不需要额外的计算。
 图注:DCL模型分为四个部分:RCM,分类网络,对抗网络,Region Alignment Network重组网络。
图注:DCL模型分为四个部分:RCM,分类网络,对抗网络,Region Alignment Network重组网络。
方法
在这一节中,我们介绍我们提出的DCL方法,上图显示了整体框架分为四个部分,推断过程仅仅需要分类网络。
Destruction Learning
对于细粒度识别,局部信息比全局结构更加的重要,大部分的细粒度类别,共享一个相似的全局结构,但是细微之处不同。在这个工作中,我们小心的打破全局结构,混乱局部区域,更好定位标识区域,学习标识区域特征。为了防止destruction引入nosiy pattern, 使用对抗损失以免RMC引入和细粒度分类无关的pattern。
RCM
借鉴自然语言处理,打乱句子中的单词,迫使神经网络聚焦在标识word,排除不相关的word。如果局部区域被打乱,神经网络将会为了分类,聚焦学习标识区域。
RCM打乱了图像局部区域的布局。假设Image 表示为
I
I
I, 被划分为N*N,每个子区域可以被表示为
R
i
,
j
,
1
≤
i
,
j
≤
N
R_{i,j}, 1\le i,j \le N
Ri,j,1≤i,j≤N。RCM打乱了图像的二维布局。打乱的方法是这样:对于第 j 行图像,生成一个大小为N的随机序列 q,其中
q
i
=
i
+
r
,
r
∽
U
(
−
k
,
k
)
q_i = i + r,r\backsim U(-k, k)
qi=i+r,r∽U(−k,k),k是一个可以调整的参数,
1
≤
k
≤
N
1 \le k \le N
1≤k≤N。对Q进行排序,我们可以获得一个信息的序列,满足这样一个条件:
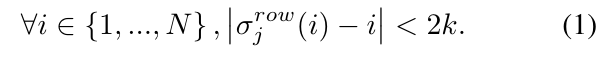 这样的处理,在列上也相似。【估摸着,k表达的是混乱的半径】
这样的处理,在列上也相似。【估摸着,k表达的是混乱的半径】
因此原始的图像可以进行这样的变换:
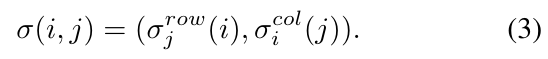 这种混乱方法打破了全局结构,并且能保证混乱的邻居半径(也就是多大范围内进行混乱)。原始图像
I
I
I、混乱图像
ϕ
(
I
)
\phi(I)
ϕ(I)和它的标签
l
l
l 组成一个三元组
(
I
,
ϕ
(
I
)
,
l
)
(I, \phi(I), l)
(I,ϕ(I),l)作为训练的输入。分类网络将图像映射到一个概率分布
C
(
I
,
θ
c
l
s
)
C(I,\theta_{cls })
C(I,θcls),
θ
c
l
s
\theta_{cls}
θcls是指分类网络中需要训练的权重,损失函数的表达:
这种混乱方法打破了全局结构,并且能保证混乱的邻居半径(也就是多大范围内进行混乱)。原始图像
I
I
I、混乱图像
ϕ
(
I
)
\phi(I)
ϕ(I)和它的标签
l
l
l 组成一个三元组
(
I
,
ϕ
(
I
)
,
l
)
(I, \phi(I), l)
(I,ϕ(I),l)作为训练的输入。分类网络将图像映射到一个概率分布
C
(
I
,
θ
c
l
s
)
C(I,\theta_{cls })
C(I,θcls),
θ
c
l
s
\theta_{cls}
θcls是指分类网络中需要训练的权重,损失函数的表达:
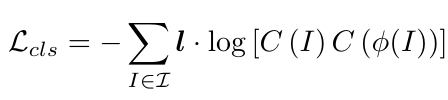 由于全局结构被破坏,为了识别分类,神经网络必须学习到标识区域,学习到种类之间的细微差距。
由于全局结构被破坏,为了识别分类,神经网络必须学习到标识区域,学习到种类之间的细微差距。
对抗训练
RCM打破的图像不一定都对细粒度识别带来好处,RCM也引入一些noisy visual pattern,从这些noisy visual pattern中学习的特征对识别产生了负面影响,对此我们提供了对抗损失,防止RCM引入的噪音进入特征空间。【这个的原因我猜测可能是因为N值一般稍稍大的时候,打破的时候有可能会非常碎,导致无法辨认,所以不能识别了】。
将原始图像和破碎的图像看成两个域(domain),对抗损失和分类损失以相互对抗的行为进行工作,1)保证域不变模式;2)拒绝I和o(I)之间特殊的域模式【也不知道作者在想什么】。
我们使用one-shot变量标记每张图片,0和1表示它们的是打碎的图片或者原图片。增加的鉴别器分支为了判断I是否是打碎的图片【这样就能尽可能保证图片打碎,并且不至于支离破碎】,鉴别器的损失函数
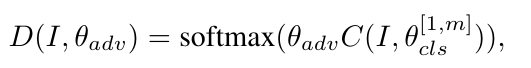 C(I, o)是分类特征网络抽取出的特征向量,Oadv是鉴别器的参数,对抗损失:
C(I, o)是分类特征网络抽取出的特征向量,Oadv是鉴别器的参数,对抗损失:
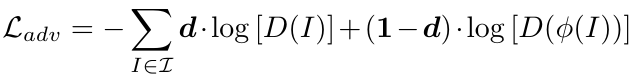 理由: 为了更好的理解对抗结构对特征学习的作用,我们将ResNet-50作为分类网络,进行了一个有无对抗的对比。
理由: 为了更好的理解对抗结构对特征学习的作用,我们将ResNet-50作为分类网络,进行了一个有无对抗的对比。
我们比较了原始图像和打碎图像的不同过滤器的散点图,如图四。图中,每个正响应的过滤器都被映射到数据点(r((I,c), r(o(I), C)))。我们可以发现cls训练的特征分布比对抗训练的特征分布更加紧凑。这就意味着过滤器对RCM引入的噪音有着巨大的响应,对原始图像也有可能有着很大的响应
【这一整节都没整明白】
contruction learning
考虑到相关区域的联合组成的复杂的分散的视觉模式,我们提出了另外一种局部的方法对局部区域的关联信息进行建模【意思是这个意思】。特别是,我们提出了一个带有region construction loss的region alignment network,它通过度量图像中不同区域的定位精度【不懂】,诱导分类网络对区域间的语义关联端到端建模。
给定图片I,相关重构o(I),R(i,j)在重构图片中的位置是Ro(i,j)。Region Alignment Network使用分类网络的一个卷积层的输出作为输入。这个特征(Region Alignment Net的输入)经过一个11的卷积核,获得一个两通道的输出,然后这个输出被一个ReLU和平均池化层处理,得到一个2N*N的output:
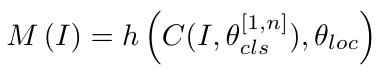 M(I)的两个输出就是位置坐标,h 是region alignment net,oloc是这个网络的参数。定义对I上的Ro(i,j)的还原预测为Mo(i,j),对I上的Ri,j的位置预测为Mi,j,它们的真实值都是 i,j。Region Alignment Net的损失是L1损失:
M(I)的两个输出就是位置坐标,h 是region alignment net,oloc是这个网络的参数。定义对I上的Ro(i,j)的还原预测为Mo(i,j),对I上的Ri,j的位置预测为Mi,j,它们的真实值都是 i,j。Region Alignment Net的损失是L1损失:
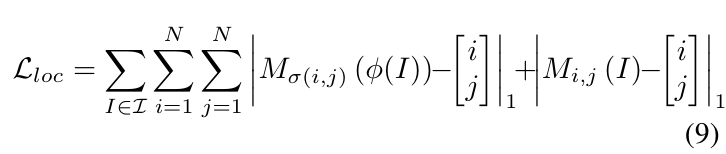 这个重构损失是有助于定位物体的位置,有助于找到图像子区域之间的关联。通过端到端的训练,这个损失可以帮助骨干分类网络建立对图像结构的深度的理解,比如物体的形状,部分之间的语义关联。
这个重构损失是有助于定位物体的位置,有助于找到图像子区域之间的关联。通过端到端的训练,这个损失可以帮助骨干分类网络建立对图像结构的深度的理解,比如物体的形状,部分之间的语义关联。
Destruction and Construction
在我们的模型中,分类,对抗和重构,都是端到端的,网络可以利用被加强的区域细节和物体部分之间的联系进行细粒度分类:
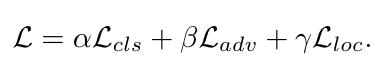 destruction 可以帮助我们寻找标识区域,construction可以帮助我们建立区域之间的联系。从而,DCL产生一组基于标识区域的复杂多样的视觉表示。
destruction 可以帮助我们寻找标识区域,construction可以帮助我们建立区域之间的联系。从而,DCL产生一组基于标识区域的复杂多样的视觉表示。
实验
使用了三个数据集CUB、CAR、AIR,并且没有使用bbx的标注
细节
backbone network:我们使用两种通用的backbone网络验证我们的分类方法,VGG-16和ResNet-50。这两个网络都是在ImageNet上进行的预训练。训练过程中的唯一标注是图片种类标签。输入图片通过随机裁剪被固定大小512512和448448。随机旋转和随机翻转也被使用,实现数据增强。所有设置以文献为准。为了让VGG16能够识别高分辨率的图片,并且不需要下采样,我们将前两个全连接层换为两个卷积层。在这篇文章所有的实验中,最一个卷积层的输出作为 region alignment net,最后一个卷积层的输出经过平均池化后,变成特征向量作为adversarial net。RCM的N值是由backbone net 和输入图片的大小决定的。图片的h、w应该可以被最后一层卷积的stride整除【不太懂】,VGG和ResNet的这个stride是32。
同时,为了region alignment net的可行,图片的w、h应该被N整除。这篇论文的实验中,使用的N值默认为7。N的选择的影响在下一节中。
实验中的模型被训练180epoch,学习率每60epoch下降十倍。测试的过程,RCM、region alignment net 和 adversarial net 都不需要。图片直接被center crop 后,经过backbone net预测分类。
性能比较
这个就
所有的实验都设置 a=b=1。a代表的是分类权重,b代表的是对抗权重。对于CUB这种非刚性的细粒度图像(比如只是一个风格),那么不同区域之间的联系就是相当的重要了,因此r=1;但是对于汽车,飞机这种数据集而言,物体的部分足够作为标识区域,所以r=0.01,强调了标识区域的重要性。不同于其他的细粒度类别,飞机的设计比如机翅,发动机,机舱等不同,飞机的种类直接不相同,因此我们使用N=2,保证局部区域的完整性。【飞机打散了不好使,这也是这个方法的缺点之一】。
解析研究
我们对DCL进行烧灼研究。我们设计了不同的拆解,在ResNet上,进行识别。这个结果显示了DCL确实很重要。DL带来的性能提升证明一个nosiy vistual pattern 和global vistual pattern、detail vistual pattern几个特征分明的特征空间是有利于细粒度识别任务。CL可以更好的提高性能。adversarial net 和 region alignment net 是互补的。
讨论
分区粒度:RCM的分区数N是该方法的一个重要参数。下表显示了N值对精度的影响:
 可以发现 N 值是一个先增后减的过程。通常 N 值比较小的情况下,对抗模块就显得无用,如果 N 值比较大的情况下,重组模块就会难以收敛(太碎了,拼不好了)。当 N=1, 这个模型就和ResNet没什么区别了。
可以发现 N 值是一个先增后减的过程。通常 N 值比较小的情况下,对抗模块就显得无用,如果 N 值比较大的情况下,重组模块就会难以收敛(太碎了,拼不好了)。当 N=1, 这个模型就和ResNet没什么区别了。
每批次中打碎图片的占比 :原始图片和打碎图片的比例是1:1,这个比例也会对精度产生一些影响。
feature map 可视化:我们可视化特征图,比较baseline模型和DCL模型,DCL模型的feature map的响应更加的靠近标识区域。即使在混乱的情况下,DCL模型仍然具有一定的鲁棒性。
 物体定位:我们也用弱监督的方式测试DCL对于VOC的性能,使用的是SPN。我们选择PLAcc作为评测标准,这个指标能够衡量网络是否能够定位到目标。实验表明DCL是有助于物体定位的。
物体定位:我们也用弱监督的方式测试DCL对于VOC的性能,使用的是SPN。我们选择PLAcc作为评测标准,这个指标能够衡量网络是否能够定位到目标。实验表明DCL是有助于物体定位的。
Destruction 中的超参数k:RCM中需要一个超参数k,我们对k进行不同值的测试:
 实验表明,当k>1的时候,对k的值并不是很敏感。
实验表明,当k>1的时候,对k的值并不是很敏感。
模型的复杂性:训练的过程中,DCL需要RCM,和Region Alignment Net以及Adversarial Net。这个参数只是ResNet的0.03%。这个模型的训练效率还是很高的。更重要的是,它的迭代次数和收敛次数与baseline的次数相近。
结论
DCL模块帮助分类网络学习专家知识。轻量级,性能好。
归纳
这个方法很精妙,它使用了deconstrcution 和 construction手段引导backbone net去寻找detail region。这样训练好的模型,就只有backbone net,在infence的过程中,计算量将会减少很多。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









