







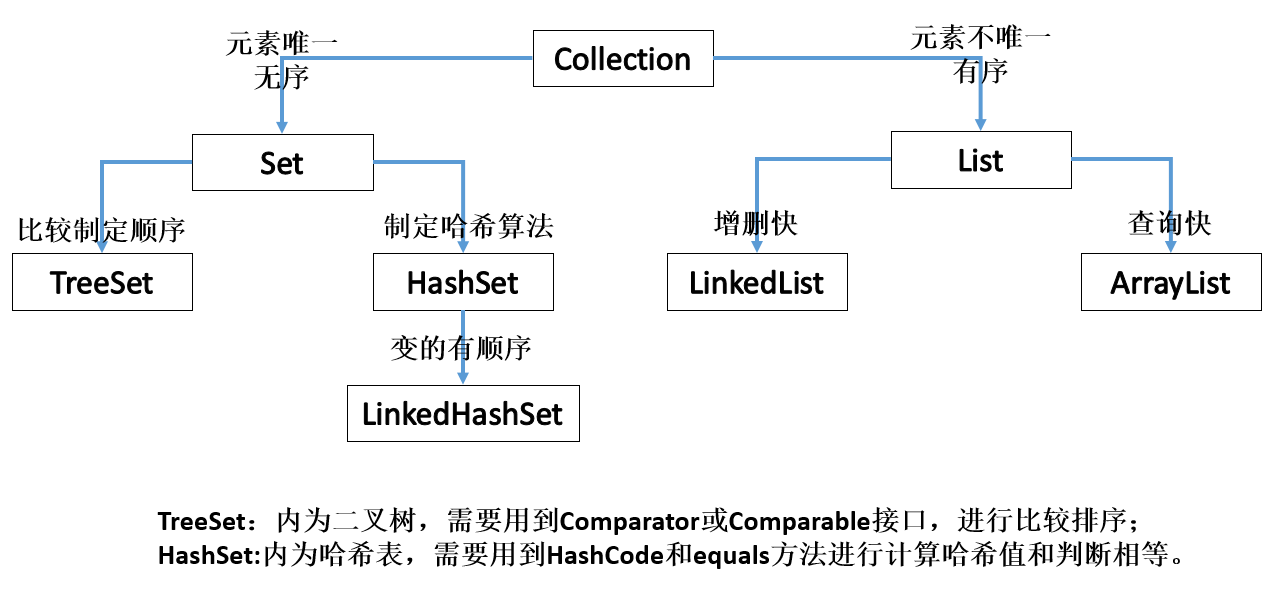
一、Set特点
1、元素不可以重复,无序。
(1)HashSet:内部数据结构是哈希表,不同步。(HashSet是无序的,但是他的子类LinkedHashSet是有序的,怎么存进去,怎么读出来,用了链表连接)
(2)TreeSet:可以对Set中的元素进行排序,不同步。元素是以二叉树的形式存放的。
二、HashSet的使用
1、哈希算法(HashCode)
给一个元素,通过哈希算法,就可以得出该元素的位置。这样比遍历算法要快的多。
function(element)
{
//哈希算法
return index;
}
2、HashSet判断元素唯一性(HashCode—>equals)
(1).先通过哈希算法(HashCode方法),得出哈希值,哈希值不同,则元素不同;
(2).若哈希值相同,则需要equals方法判断。
3、HashSet例子—-存放自定义对象(HashSet1.java)
import java.util.HashSet;
import java.util.Iterator;
public class HashSet1 {
public static void main(String[] args) {
//里面存放的是哈希值
HashSet h = new HashSet();
//每次创建对象会调用HashCode方法得出哈希值,即存放的位置
h.add(new Person("xx1",14));
h.add(new Person("xx2",12));
h.add(new Person("xx3",13));
//得出哈希值相等,则用哈希值相等已存的对象与当前要存入的对象进行equals方法比较,若equals比较相等,则不存。
h.add(new Person("xx1",14));
Iterator it = h.iterator();
while(it.hasNext())
{
Person p = (Person) it.next();
System.out.println(p.getName()+"--结果--"+p.getAge());
}
}
}
class Person implements Comparable{
private String name;
private int age;
Person(String name,int age)
{
this.name = name;
this.age = age;
}
@Override/*对Object中的哈希算法进行了重写*/
public int hashCode() {
System.out.println(this+".....hashcode"); //哪个对象调用this,this就代表这个对象
return name.hashCode()+age;
}
@Override/*对Object中的equals算法进行了重写*/
public boolean equals(Object obj) {
//当哈希值相等时,当前要写入的对象(this)会调用该方法与原来的对象(obj)进行比较
Person p = (Person) obj;
System.out.println(this+".....equals");
return this.name.equals(p.name)&&this.age == p.age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override/*用来输出当前对象this的字符串形式*/
public String toString() {
return name+":"+age;
}
@Override/*第一种排序方法:
这个函数给TreeSet调用,对Person对象进行比较*/
public int compareTo(Object o) {
//this表示当前对象,谁调用就代表谁
int temp;
Person p = (Person)o;
temp = this.name.compareTo(p.name);
return temp==0?this.age-p.age:temp;
//先按照姓名排序,若相等,则按照年龄
}
}总之:想到HashSet,条件反射到HashCode—>equals。
三、TreeSet的使用
1、TreeSet判断元素唯一性:根据比较方法的返回结果判断,结果0就为相等。
2、排序方法
(1)实现Comparable接口(接口中覆盖的compareTo方法,TreeSet1.java中实现了)
(2)给TreeSet构造函数传入比较器对象,则使用实现Comparator接口的子类对象的compare方法。(TreeSet1.java结合HashSet1.java一起运行)
3、例子—-排序方法二的实现
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSet1 {
public static void main(String[] args) {
//传入比较器对象,则使用实现Comparator接口子类对象的方法
TreeSet tr = new TreeSet(new TreeCompara());
//若不传入比较器对象,则使用Person对象中的比较方法compareTo
// TreeSet tr = new TreeSet();
//存放的对象会调用,对象中的比较方法
tr.add(new Person("yy1",11));
tr.add(new Person("yy4",14));
tr.add(new Person("yy2",12));
tr.add(new Person("yy3",11));
tr.add(new Person("yy2",19));
Iterator it = tr.iterator();
while(it.hasNext())
{
Person p = (Person) it.next();
System.out.println(p.getName()+"--结果--"+p.getAge());
}
}
}
/*第二种排序方法:利用比较器排序*/
class TreeCompara implements Comparator{
@Override
public int compare(Object o1, Object o2) {
int temp;
Person p1 = (Person) o1;
Person p2 = (Person) o2;
temp = p1.getAge()-p2.getAge(); //按照年龄比,若相等,按照名字比。
return temp==0?p1.getName().compareTo(p2.getName()):temp;
}
}总之:看到TreeSet,条件反射到Comparatable和Comparator接口比较方法。
四、集合Collection总结
1、Collection框架


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









