







Sphinx是基于sql的全文搜索引擎,满足更高效的搜索需求,以下是一个操作示例:
新建一张posts表用来做搜索用:
CREATE TABLE IF NOT EXISTS `posts` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`content` varchar(255) NOT NULL,
`user_id` int(11) NOT NULL,
`created` datetime NOT NULL,
`updated` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=18 ;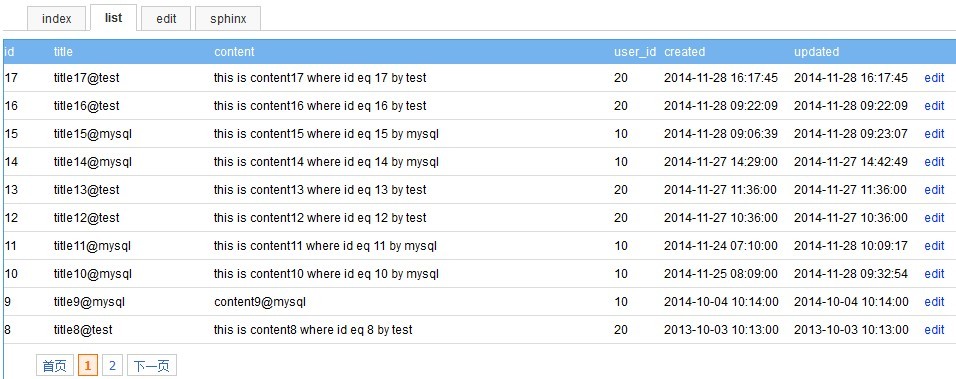
首先在posts表中,插入若干条记录,
假设现在需要搜索content字段中含有mysql的数据,使用sql select将会使用到like语句(like %mysql%),如果数据量太大,将在无索引可用的情况下,发生数据库锁表,这时使用sphinx,将可以满足需求
下载sphinx,并新建data、log文件夹用于存放sphinx生成的文件和日志:
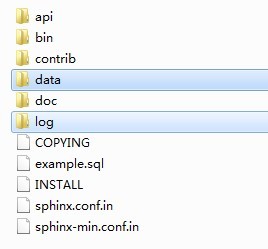
复制一份sphinx-min.conf.in(或者sphinx.conf.in)到bin文件夹下,改名为sphinx.conf,并做一些本地化的修改,以下是本例的conf参考配置:
# 建立一个sphinx计数器,用来记录增量索引的操作
# CREATE TABLE IF NOT EXISTS `sph_delta` (
# `table` varchar(50) NOT NULL,
# `max_id` int(11) NOT NULL,
# `updated` datetime NOT NULL,
# PRIMARY KEY (`table`)
# ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
# 数据库配置
source src_db
{
# 数据库配置
type = mysql
sql_host = localhost
sql_user = root
sql_pass = root
sql_db = my_sphinx
sql_port = 3306
# 数据源预操作
sql_query_pre = SET NAMES utf8
}
# 主源
source src_main:src_db
{
# 分区查询,避免大数据死锁
sql_query_range = SELECT MIN(`id`), MAX(`id`) FROM `posts`
sql_range_step = 500
# 设置需要查询的字段
sql_query = \
SELECT `id`, `title`, `content`, `user_id`, `created`, `updated` \
FROM `posts` \
WHERE `id`>=$start and `id`<=$end
# 查询完毕以后的操作
sql_query_post = REPLACE INTO `sph_delta` \
(`table`,`max_id`,`updated`) values \
('posts', (SELECT MAX(`id`) FROM `posts`), now())
# 返回结果中也包含的数据(前提是在sql_query中设置过)
sql_attr_uint = user_id
sql_attr_timestamp = created
sql_attr_timestamp = updated
}
# 增量源
source src_delta:src_db
{
# 查询大于上一次MAX(id)的数据,表的主键是自增的,切不考虑已经更新的数据
sql_query = \
SELECT `id`, `title`, `content`, `user_id`, `created`, `updated` \
FROM `posts` \
WHERE `id`>=(SELECT `max_id` FROM `sph_delta` WHERE `table`='posts')
sql_attr_uint = user_id
sql_attr_timestamp = created
sql_attr_timestamp = updated
}
# 更新源
source src_merge:src_db
{
# 查询上一次建立索引时间以后,更新的数据,表中有updated字段来记录最后更新时间
sql_query = \
SELECT `id`, `title`, `content`, `user_id`, `created`, `updated` \
FROM `posts` \
WHERE `updated`>=(SELECT `updated` FROM `sph_delta` WHERE `table`='posts')
sql_attr_uint = user_id
sql_attr_timestamp = created
sql_attr_timestamp = updated
# 排除那些已经更新了,但是在main索引仍存在的幽灵数据
sql_query_killlist = \
SELECT `id` \
FROM `posts` \
WHERE `updated`>=(SELECT `updated` FROM `sph_delta` WHERE `table`='posts')
# 更新索引创建的最后时间
sql_query_post = REPLACE INTO `sph_delta` \
(`table`,`max_id`,`updated`) values \
('posts', (SELECT MAX(`id`) FROM `posts`), now())
}
index idx_main
{
# 对应source名称
source = src_main
# 生成索引文件的路径
path = E:/sphinx-2.2.6/data/idx_main
}
index idx_delta
{
source = src_delta
path = E:/sphinx-2.2.6/data/idx_delta
}
index idx_merge
{
source = src_merge
path = E:/sphinx-2.2.6/data/idx_merge
}
indexer
{
mem_limit = 128M
}
searchd
{
listen = 9312
listen = 9306:mysql41
log = E:/sphinx-2.2.6/log/searchd.log
query_log = E:/sphinx-2.2.6/log/query.log
read_timeout = 5
max_children = 30
pid_file = E:/sphinx-2.2.6/log/searchd.pid
seamless_rotate = 1
preopen_indexes = 1
unlink_old = 1
workers = threads # for RT to work
binlog_path = E:/sphinx-2.2.6/data
}
src_db源:基本的数据库配置(sphinx中有继承的概念,这里用作基类)
src_main源:主索引,把当前的posts表中的数据,进行sphinx索引化,生成sphinx索引文件
src_delta源:增量索引,每次可以只创建posts表中新增数据的sphinx索引文件,而不需要对主索引文件进行整体重建(本例posts表主键id自增)
src_merge源:更新索引,每次可以只创建那些posts表中最近被修改的文件,也不需要对主索引文件整体重建(本例posts表中对数据操作会更新updated为更新时间)
本例在windows中操作sphinx,需要在cmd中进入到你的sphinx安装路径,并操作indexer.exe和searchd.exe:
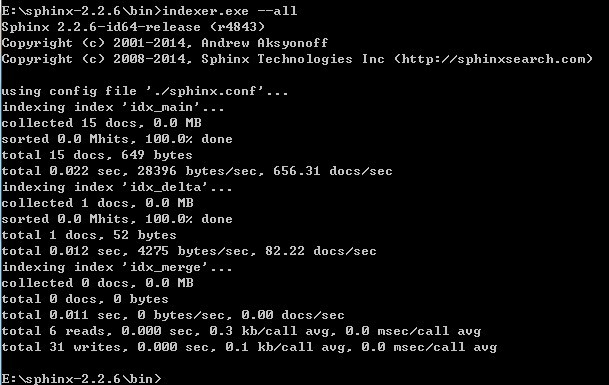

indexer.exe --all:创建conf中配置的所有索引,--all是创建所有的意思,也可以只跟索引名只对某个索引进行重新创建
searchd.exe:开启sphinx服务,除了开启mysql,windows下需要执行此命令才可以使用sphinx
回到后台中,使用sphinx进行搜索操作(后台程序需要引用sphinx文件中的api文件:\sphinx-2.2.6\api\sphinxapi.php):
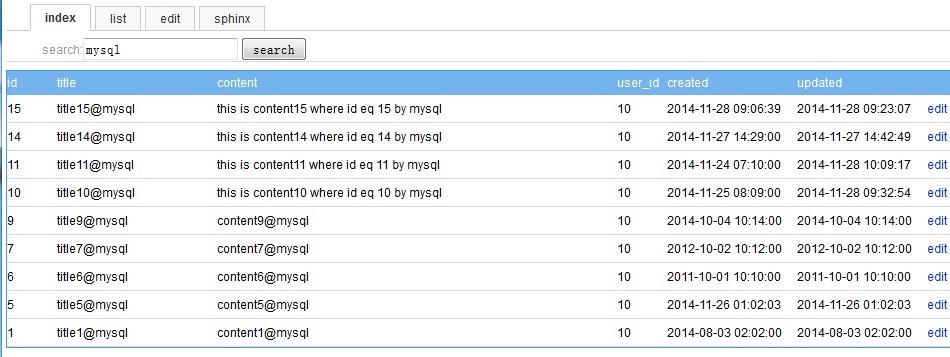
后台程序的相关代码(部分):
<?php
include_once('inc/global.php'); // 包含对mysql操作的封装类,sphinxapi的引用,简单分页function
$nav = 'index';
$search = isset($_GET['search'])?trim($_GET['search']):'';
$param .= "&search={$search}";
$page = isset($_GET['page'])?intval($_GET['page']):1;
$limit = 10;
$ms = new Mysqls();
$data = array();
$pager = '';
if($search){
// 创建Sphinx的客户端接口对象
$cl = new SphinxClient();
// 设置连接Sphinx主机名与端口
$cl->SetServer(SP_HOST,SP_PORT);
// 设定搜索模式,SPH_MATCH_ALL,SPH_MATCH_ANY,SPH_MATCH_BOOLEAN,SPH_MATCH_EXTENDED,SPH_MATCH_PHRASE
$cl->SetMatchMode(SPH_MATCH_ANY);
// 分组,当前排序方法本组中的最佳匹配数据
// $cl->SetGroupBy('user_id', SPH_GROUPBY_ATTR, '@id desc');
// 设定排序方法,SPH_SORT_RELEVANCE,SPH_SORT_ATTR_DESC,SPH_SORT_ATTR_ASC,SPH_SORT_TIME_SEGMENTS,SPH_SORT_EXTENDED
$cl->SetSortMode(SPH_SORT_EXTENDED, '@id desc');
// 相当于mysql的limit
$cl->SetLimits(($page-1)*$limit,$limit);
// 查询关键字,$index是索引名称,当等于*时表查询所有索引,注意主索引和增量索引
$result = $cl->Query($search);
// $result = $cl->Query($search,'idx_main'); // 只查idx_main主索引
// $result = $cl->Query($search,'*');
// $result = $cl->Query($search,'idx_merge'); // 只查idx_merge更新索引
// $result = $cl->Query($search,"idx_main idx_merge"); // 查询主索引&更新索引,测试更新索引中的sql_query_killlist是否生效
$total = $result['total_found'];
if($total){
$matches = $result['matches'];
foreach($matches as $k=>$v){
$id = $k;
$sql = "select * from `posts` where `id`={$id} limit 1";
$data[] = $ms->getRow($sql);
}
$pager = getPage($total,$page,$limit,$param);
}
}
本例的一些配置:
define("DB_HOST",'127.0.0.1');
define("DB_USERNAME",'root');
define("DB_PASSWORD",'root');
define("DB_NAME",'my_sphinx');
define("DB_SLAVE_HOST",'127.0.0.1');
define("DB_SLAVE_USERNAME",'root');
define("DB_SLAVE_PASSWORD",'root');
define("DB_SLAVE_NAME",'my_sphinx');
define("SP_HOST",'127.0.0.1');
define("SP_PORT",9312);在执行过一次indexer.exe --all以后,main主索引、delta增量索引和merge更新索引将被创建,但也只是以创建时间点截止的数据,之后对mysql中的实际数据进行的操作,将不会自动更新到sphinx的索引文件中(sphinx\data\)
你可以选择在cmd中,ctrl+c停掉searchd.exe,并再次执行indexer.exe idx_main之后再次开启,这样可以重建创建sphinx主索引文件,把posts表中的所有数据重建创建sphinx索引,这里可以使用一些定时脚本工具定期的去执行这个操作,但在posts表数据量过大的情况下,生成sphinx主索引文件的该操作太过频繁会浪费太多的机器资源,因为需要对posts表做整体遍历
你可以选择定期执行一次indexer.exe idx_delta增量索引,这样就不用重建创建主索引对整张posts表进行遍历,前提是posts表中有相关的自增变量
本例同时新建的sph_delta表,就是用来在最近一次sphinx索引创建后,记录下当时posts表数据的id主键最大值、最后的updated更新时间,delta增量索引可以选择每次只创建大于上次的最大id之后的数据,merge更新索引可以选择每次只创建在上一次创建索引之后发生更新的数据
若是没有定期执行merge更新索引的创建,你将会得到'幽灵数据',即在sphinx索引文件中含有的数据,但是在mysql中实际数据已经发生变更的数据
main主索引、delta增量索引和merge更新索引,需要根据你的实际数据情况,进行有选择的控制他们的执行频率















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









