







估计转义字符大家都听过,多字节字符通过微软常用的wchar_t也都了解过,三字母词是神马?不知道吧?之写这篇博客前我也不知道。因为编程中很少用得到。
但是等你碰到的时候也许会感到一头雾水。
比如,你想打印"What??"
printf( "What??!\n" );
得到的却是“What|”,你是不是会下一跳。
另外,你真的了解字符常量吗?
你未必知道,比如:
----------------------------------------------------------------------------------
'M','\n' ,'\39','\039','\xa', '\xab','\Xab','hah','??('
---------------------------------------------------------------------------------
话说它们都是 字符常量。
我们分别来看:
第一个是普通单字节字符,
有反斜杠(\)的分三种情况:
1.'\n' 都知道,是一般转义字符。
2.
a)'\39' 等同于'\039',是由1~3个八进制数字序列组成的八进制转义字符,形式为'\ooo'所以,039 (八进制)== 33(十进制)在ASICII码表中代表半角的感叹号字符 '!'所以:'\039' == 33 == '!'。
b)'\xa', '\xab','\XAB' 是由x或X加上1~216进制数字序列组成的十六进制转义字符,形式为'\xhh',如'\xa',0xa(十六进制) == 10(十进制),在ASCII码表中代表LF(line feed),行满,也就是换行,C语言中定义的'\n'的ASICII码值就是10,所以'\n' == '\xa' == '\XA'。
倒数第二个'hah'就是多字节字符。没有反斜杠哦~
3.最后一个'??( ' 这是个三字母词,对应的字符是'[',还有与之对应的一个三字母词是 '??)'!它代表字符']'
什么!看得有点儿晕?来,让我慢慢道来~~~~~~
首先说说多字节字符。
一、多字节字符
多字节字符,我们也称为多字节字符常量(multi-character character constant)。多字节字符使用多个字节表示一个字符。它是字符常量的一种,比如UNICODE编码通常使用2个字节表示一个字符。
在ANSI C(也就是通常说的C89)标准产生以前其实并没有宽字符的,直到ANSI对K&R C修订以后引入了宽字符概念。其主要目的是解决亚洲国家文字编码问题。用多个字节表示一个字符。自此C语言不只提供char类型,还提供wchar_t类型(宽字符),此类型定义在stddef.h 头文件中。wchar_t指定的宽字节类型足以表示某个实现版本扩展字符集的任何元素。
关于ANSI C和K&R C的关系和历史请点击这里自行脑补。
多字节字符和宽字符(wchar_t)的主要差异在于宽字符占用的字节数目都一样,而多字节字符的字节数目不等,这样的表示方式使得多字节字符串比宽字符串更难处理。比方说,即使字符'A'可以用一个字节来表示,但是要在多字节的字符串中找到此字符,就不能使用简单的字节比对,因为即使在某个位置找到相符合的字节,此字节也不见得是一个字符,它可能是另一个不同字符的一部分。然而,多字节字符相当适合用来将文字存储成文件。但是C为我们提供了一些多字节字符和单字节字符转换的函数:
mblen() //返回一个字符的字节数
mbstowcs() //把多字节字符串转换为宽字符串
mbtowc()/btowc() //把多字节字符转换为宽字符
wcstombs() //把宽字符串转换为多字节字符串
wctomb()/wctob() //把宽字符转换为多字节字符
另外,C语言本身并没有定义或指定任何编码集合,或任何字符集(基本源代码字符集和基本运行字符集除外),而是由 实现 指定如何编码宽字符,以及要支持什么类型的多字节字符编码机制。
对于Unicode字符集,许多实现版本使用Unicode转换格式UTF-16和UTF-32来处理宽字符。如果遵循Unicode标准,wchar_t类型至少是16或32位长,而wchar_t类型的一个值就代表一个Unicode字符。
关于Unicode和Windows下宽字符转换请移步这里。
那字符常量在内存中的映射结构是怎样的呢?
关于字符常量,C和C++的映射方式不一定是相同的。
使用单引号是在C中是“Character constants”(字符常量),在C++中是"Character literals"(字符常量),(这里"Character constants"和"Character literals"只是叫法不同,含义是相同的。 ”literals“有时也被译为”字面量“。)使用双引号是无论C还是C++都是“String literals”(字符串常量),前者通常视为单个字符,后者视为字符串,更确切的说前者只能“映射为一个值”,该值在C中总是映射为int类型的值,在C++中如果是一个字符,就映射为char类型的值,如果是多个字符那么映射为int类型。
无论C还是C++在Character constants多于一个时具体能映射多少个字符并且映射到具体什么样的值都是依赖于程序执行环境和编译器的,标准对此的规定都是明确说由实现定义。
下面示例代码被认为多字节字符常量最有意义的使用方式了。
enum
{
kActionForward = 'frwd',
kActionBackward = 'bkwd',
kActionLeft = 'left',
kActionRight = 'rght',
kActionZap = 'zap!'
};enum变量的本质是int,无法用字符串常量。用多字节字符增加代码可读性未必不是一个好方法。
char c_a= 'abc';
int i_a = 'abc';c_a和i_a的值应该是多少呢?(默认使用通用的g++ C89编译)。
先别着急敲代码测试,我们先分析一下:
‘abc’肯定是个多字节字符,不是字符串。
上面已经说了,对于字符常量,在C中总是映射为int,在C++中如果是一个字符,就映射为char类型的值,如果是多个字符那么映射为int类型。那么这里明显会被映射为int类型。那么它有32个二进制位。
所以c_a得到的值肯定是不全的,因为char类型只有8个二进制位。
我们写段程序看看结果:
int _tmain(int argc, _TCHAR* argv[])
{
char c_a= 'abc';
int i_a = 'abc';
printf("c_a = %c, i_a = %x\n", c_a, i_a);
while(1);
return 0;
}

这里i_a我是用16进制打印的,方便看结果。
可以看到c_a的结果是字符'c',i_a的结果是0x616263,为什么是这个结果呢?
对ASCII码敏感的人可能一看就知道原因了。
0x61 = 97,对应ASCII字符为'a',
0x62 = 98,对应ASCII字符为'b',
0x63 = 99,对应ASCII字符为'c',
看来我们的编译器解释方式是从左到右依次对应二进制的高低位。
对于c_a,被截断后只留下低8位,因此得到的是0x63,也就是字符'c'了。
那'012'对应的int值是多少呢?
当然是0x303132啦~不要问我为什么,我不告诉你。
这个怎么玩呢?
来!我们玩一玩:
int isNumLessThanZero(int m)
{
if(m < 0)
{
return 'yes';
}
return 'no';
}
int _tmain(int argc, _TCHAR* argv[])
{
int i_a = -1;
if(isNumLessThanZero(i_a) == 'yes')
{
printf("i_a is less than 0.");
}
else
{
printf("i_a is greater than 0.");
}
while(1);
return 0;
}
是不是感觉这时候‘yes’和'no'可以取代true和false了呢?然后用它来那啥了呢?哈哈!!!!哈哈哈!!!!哈哈哈!!!!
神经病又犯了、、、
注意:ANSI C标准虽然允许使用多字节字符常量,但是但是他它们的实现在不同的编译器编译环境中可能不一样。因此不鼓励使用。但是当我们遇到了应该知道为什么。
既然提到了字符串,那么就顺便说以下字符串常量的内容。
C语言本身是不存在字符串类型的,因为C语言认为字符串通常可以存储在字符数组中。而C++则提供了字符串类型string。不过C语言提供了字符串常量。尽管C语言没有提供字符串类型,但事实上却存在字符串概念。它就是一串以NUL字节(即'\0')结尾的零个或多个字符。
K&R C与ANSI C对字符串常量的存储形式声明是不同的。
K&R C把所有的字符和NUL终止符都存储于内存中的某个位置。它表明具有相同值的不同字符串常量在内存中是分开存储的。因此,许多编译器都允许程序修改字符串常量。
而ANSI C声明如果对一个字符串常量进行修改,其结果是未定义的。它允许把具有相同值的不同字符串存储于一个地方(这样,实际上就只有一个字符串了)。因此,许多ANSI编译器不允许修改字符串常量的原因。因为一修改,其他所有相同字符串的常量也会受到改变。
下面通过一个程序来证明ANSI C编译器对字符串的处理是在内存中只保存一份拷贝。
int _tmain(int argc, _TCHAR* argv[])
{
char* p1 = "hello";
char* p2 = "hello"; // 与p1指向的字符串相同
printf("&p1[0] = %p, &p2[0] = %p\n", &p1[0], &p2[0]); // "hello"第一个字符的地址。
printf("p1 = %p, p2 = %p\n",p1, p2); // p1和p2指向的地址
char* q = "hellos"; // 注意多了一个's'
printf("&q[0] = %p, q = %p\n", &q[0], q); // 打印q指向的地址和"hellos"第一个字符的地址
while(1);
return 0;
}
我们打印其值:
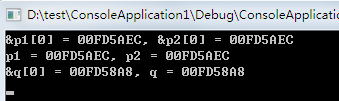
我们看到p2,==p2==&p1[0]==&p2[0],相等的原因就是"hello"这个字符串常量无论出现多少次,它在内存中只有一份。(事实上它的存储位于进程中虚拟存储器的只读常量区)。
因此,大多数编译器不允许你通过指针修改字符串常量的值,因为一旦修改,其它与之相同的字符串也会被修改。
你或许可以这样理解字符指针:
当使用char*仅仅想指代一个字符的地址时,它的类型就是一般意义的char*(字符指针)。
当使用char*指代一个字符串常量的地址时,它的类型确切的说应该是cont char*,因为你无法通过该指针修改字符串常量的值。
另外,你看到一个字符串常量可以赋值给一个字符指针,实际上这样的理解并不正确。字符串常量的直接值是一个指针,char* 指针指代的到底是一个字符的地址,还是一个字符串常量的地址,这得看你如何打印。如果用%c,解引用方式打印,它就代表一个字符的地址,如果用%s的方式打印,它就代表一个字符串常量的地址。并且是直到遇到字符NUL(即'\0')才算该字符串常量的结束。这也是我们有时会产生混乱甚至导致段错误的原因(segmentation fault),因为我们可能访问了不可引用的位置,导致核心转储。这是不安全的。因此C++使用string解决了这一问题。
我们用一段程序来理解:
int _tmain(int argc, _TCHAR* argv[])
{
char* q = "hellos";
char* p_m = &q[1];
printf("p_m = %c, p_m = %s", *p_m, p_m);
char n = 'abc';
char* p_n = &n;
printf("p_n = %c, p_n = %s", *p_n, p_n); // %c解引用打印和%s打印
while(1);
return 0;
}看看执行结果:

我很庆幸没有导致段错误。
可以看到对于char*类型的变量p_m,用%c并解引用的方式正确打印出了"hellos"的第二个字符'e'。用%s则打印出了第二个字符起往后的字符串,直到遇到了"hellos"的最后一个字符NUL结束。
但是对于char*类型的变量p_n就没那么幸运了,p_n本来指向栈内存中的一个字节块,但是,你却用%s打印,它从该字节地址起一直打印后面的字符,直到出现NUL或者到达不可访问地址才结束。一旦到达不可访问的地址,就会出现类似段错误的提示。在这里,你无法理解它为什么会打印出一堆乱码,而且我可以肯定它每次打印出的值都不同。
而且,在程序中我们可以看到,字符串常量直接赋值给了一个字符指针,虽然我们已经习以为常,但是细细想来还是有些困惑,它们是等价的吗?可以直接赋值吗?
事实上, ANSI C中字符串常量的直接值是一个指针,当一个字符串常量出现于一个表达式中时,表达式所使用的值就是这些字符串所存储的地址,而不是这些字符本身,因此你可以把一个字符串常量赋值给一个"指向字符的指针",后者指向这些字符所存储的地址。
看了上面解释,也许名明了了很多,但是不要忘了还有下面一种赋值方式:
char str[] = "nihaoma?";难道此处的"nihaoma?"也是不可修改的吗?不符合逻辑啊。
你的第六感是对的。
不要忘了。str是char[9]类型的字符数组。是在栈中开辟的内存(假设str是局部变量),而并非在只读常量区。
当字符串常量被赋值给一个字符串数组时,它会从只读常量区拷贝该字符串到栈中,并将首地址赋值给该数组名。
其实
char str[] = "nihaoma?";
只是
char str[] = {'n','i','h','a','o','m','a','?','\0'};
和
char str[] = {"nihaoma?"};
的变种,因为C/C++允许这么干。
所以str[]中的元素完全是可以修改的。因为你并没有修改只读区的数据。
二、转义字符
不知你有没有发现,在我们写C程序时,大部分字符是可以直接打印并显示到屏幕的,然而,当我们想换行、回车、退格、制表的时候,怎么办呢?C引入了"控制字符"(Control Character),在ASCII码中,第0~31号及第127号(共33个)是控制字符或通讯专用字符。
在C语言中,构成字符常量的控制字符必须用转义字符表示。转义字符是一种以“\”开头的字符。例如退格符用'\b'表示,换行符用'\n'表示。转义字符中的'\'表示它后面的字符已失去它原来的含义,转变成另外的特定含义。反斜杠与其后面的字符一起构成一个特定的字符。
转义字符是C语言中表示字符的一种特殊形式。转义字符以反斜'\'开头,后面跟一个字符或一个八进制或十六进制数表示。转义字符具有特定的含义,不同于字符原有的意义,故称转义字符。
通常使用转义字符表示ASCII码字符集中不可打印的控制字符和特定功能的字符,如'\n'(换行),'\f'(打印机换页)等。
还有比较特殊的对原字符转义的字符,如单撇号(\'),双撇号(\")和反斜杠(\\)等,为什么要对原字符转义呢?不是多此一举吗?
这是因为它们的原有的字符形式已作它用,其中,单引号用作区分字符常量的括号,双引号用作区分字符串的括号,而反斜杠本身已用来表示转义字符的开头,因此必须对它们用转义字符重新声明。因此当我们想打印'\'时,必须这样做:
printf("\\");否则编译器就会报错。
下面列举了一些常用的转义字符:
|
转义字符
|
意义
|
ASCII码值(十进制)
|
|
\a
|
响铃(BEL)
|
007
|
|
\b
|
退格(BS) ,将当前位置移到前一列
|
008
|
|
\f
|
换页(FF),将当前位置移到下页开头
|
012
|
|
\n
|
换行(LF) ,将当前位置移到下一行开头
|
010
|
|
\r
|
回车(CR) ,将当前位置移到本行开头
|
013
|
|
\t
|
水平制表(HT) (跳到下一个TAB位置)
|
009
|
|
\v
|
垂直制表(VT)
|
011
|
|
\\
|
代表一个反斜线字符''\'
|
092
|
|
\'
|
代表一个单引号(撇号)字符
|
039
|
|
\"
|
代表一个双引号字符
|
034
|
|
\0
|
空字符(NULL)
|
000
|
|
\ddd
|
1到3位八进制数所代表的任意字符
|
三位八进制
|
|
\xhh
|
1到2位十六进制所代表的任意字符
|
二位十六进制
|
\ddd 三位八进制
\xhh 二位十六进制
ASCII码范围表
字符: ASCII码(10进制)
控制字符 :0---31和127
数字字符'0'---'9' : 48--57
大写字母字符'A'---'Z': 65---90
小写字母字符'a'---'z': 97---122
三字母词 : 35、91---94、123---126
换页符(\f)可用于控制打印机换页,但不会导致 PC 机的显示屏换页。
换行符(\n)使活跃位置跳到下一行的开端。
回车符 ( \r )使活跃位置返回当前行的开端。
水平制表符(\t)使活跃位置移动若干个位置(通常是8个)。
垂直制表符(\v)可用于控制打印机换若干行,但是不会导致PC机的显示屏换行。
如果要打印以下句子: "\ is called 'backslash'."
我们需要使用如下语句:
printf("\"\\ is called \'backslash\'.\""); 或者
printf("\"\\ is called 'backslash'.\"");
注意,在字符串字面量中,无论写 \' 还是 ',输出都是一样的。但是,在给字符变量赋值时,一定要写 \'。例如:
char ch = ''';
char ch = '\'';
\0oo 和 \xhh 是ASCII码的两种特殊表示形式。如果想用八进制ASCII码表示字符,可以在八进制数前面加上 \ ,然后用单引号引起来。例如:
beep = '\007';
打头的那些0可以省略,也就是说,写成 '\07' 或者 '\7' 都一样。无论有没有打头的0 ,7 都会被当成八进制数处理。
从 C89 开始,C提供了用十六进制表示字符常量的方法:在反斜杆后面写一个 x ,然后再写 1 到 3 个十六进制数字。例如:
int n = '\xa';
现在分别介绍三种转义字符:
1. 一般转义字符
这种转义字符,虽然在形式上由两个字符组成,但只代表一个字符。常用的一般转义字符为:
\a \n \t \v \b \r \f \\ \’ \"
2. 八进制转义字符
它是由反斜杠'\'和随后的1~3个八进制数字构成的字符序列。例如,'\60'、'\101'、'\141'分别表示字符'0'、'A'和'a'。因为字符'0'、'A'和'a'的ASCII码的八进制值分别为60、101和141。
字符集中的所有字符都可以用八进制转义字符表示。
如果你愿意,可以在八进制数字前面加上一个0来表示八进制转移字符。
3. 十六进制转义字符
它是由反斜杠'\'和字母x(或X)及随后的1~2个十六进制数字构成的字符序列。例如,'\x30'、'\x41'、'\X61'分别表示字符'0'、'A'和'a'。因为字符'0'、'A'和'a'的ASCII码的十六进制值分别为0x30、0x41和0x61。
可见,字符集中的所有字符也都可以用十六进制转义字符表示。
由上可知,使用八进制转义字符和十六进制转义字符,不仅可以表示控制字符,而且也可以表示可显示字符。但由于不同的计算机系统上采用的字符集可能不同,因此,为了能使所编写的程序可以方便地移植到其他的计算机系统上运行,程序中应少用这种形式的转义字符。
使用转义字符时需要注意以下问题:
1)转义字符中只能使用小写字母,每个转义字符只能看作一个字符。
2)\v垂直制表和\f换页符对屏幕没有任何影响,但会影响打印机执行响应操作。
3)在C程序中,使用不可打印字符时,通常用转义字符表示。
4)转义字符’\0’表示空字符NULL,它的值是0。而字符'0'的ASCII码值是48。因此,空字符’\0’不是字符0。另外,空字符不等于空格字符,空格字符的ASCII码值为32而不是0。编程序时,读者应当区别清楚。
5) 如果反斜线之后的字符和它不构成转义字符,则’\’不起转义作用将被忽略。
例如:
printf(“a\Nbc\nDEF\n”);
输出:
aNbc
DEF
6)转义字符也可以出现在字符串中,但只作为一个字符看待。
例 求下面字符串的长度
“\026[12,m” 长度为6 '\026'不会被看成'\0',而是一个8进制转义字符。想想前面带有零的八进制转义字符就知道了。
三、三字母词
C语言中定义了9个特殊三字母词(都是以两个'?'号开头):
C 源程序的源字符集被包含在 7 位的 ASCII 字符集中,但是它是 ISO 646-1983 Invariant Code Set 的超级。三字母词序列允许编写只使用 ISO(International Standards Organization)Invariant Code Set 的 C 程序。三字母词就是三个字符(由两个连续的问号而被引入)的序列,并且编译器会把它们替换成相应的标点字符。你可以用一种没有为部分标点字符包含方便的图形呈现的字符集而在 C 源文件中使用三字母词。
下表说明了九种三字母词序列。所有在源文件出现的第一列中的标点字符都会被替换成第二列中的相应字符。
三字母词序列
| 三字母词 | 标点字符 |
|---|---|
| ??= | # |
| ??( | [ |
| ??/ | \ |
| ??) | ] |
| ??' | ^ |
| ??< | { |
| ??! | | |
| ??> | } |
| ??- | ~ |
三字母词始终被视为一种单独的源字符。三字母词的翻译过程首先会获取第一翻译阶段的位置,并且在字符串中和在字符变量的转义字符之前。
因此,只有上表中所说的这九种三字母符才是被认可的。而所有其他的字符序列都不会被翻译。
现在知道为什么上面打印的不是 “What??!”了吧?
那应该怎么做呢?
如果不会那你就白看了。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









