






上周Stable Diffusion WebUI正式发布了1.9.0版本,我也第一时间把AutoDL镜像升级到了最新版本,有几个比较重要的更新再和大家同步下。
1、为SDXL-Lightning模型使用SGM统一调度器
SDXL-
Lightning由字节跳动开源,是一款闪电般的快速文生图模型,能够在几步之内生成高质量的1024像素图像。模型源自
stable-diffusion-xl-
base-1.0,提供了包含1步、2步、4步和8步的蒸馏模型,目前2步、4步及8步模型已经可以生成高质量的图片,1步模型还是实验性的。
Stable Diffusion WebUI之前的调度器都不能很好的适应这个模型,导致出图质量不佳,现在一个新的调度器来了,sgm-
uniform可以让SDXL-Lightning在SD WebUI中表现的更加完美。
看看效果吧:

对于原版的SDXL,2-4步只能出个大概的面部轮廓,对于闪电模型,4步较为完美。
使用方法如下:
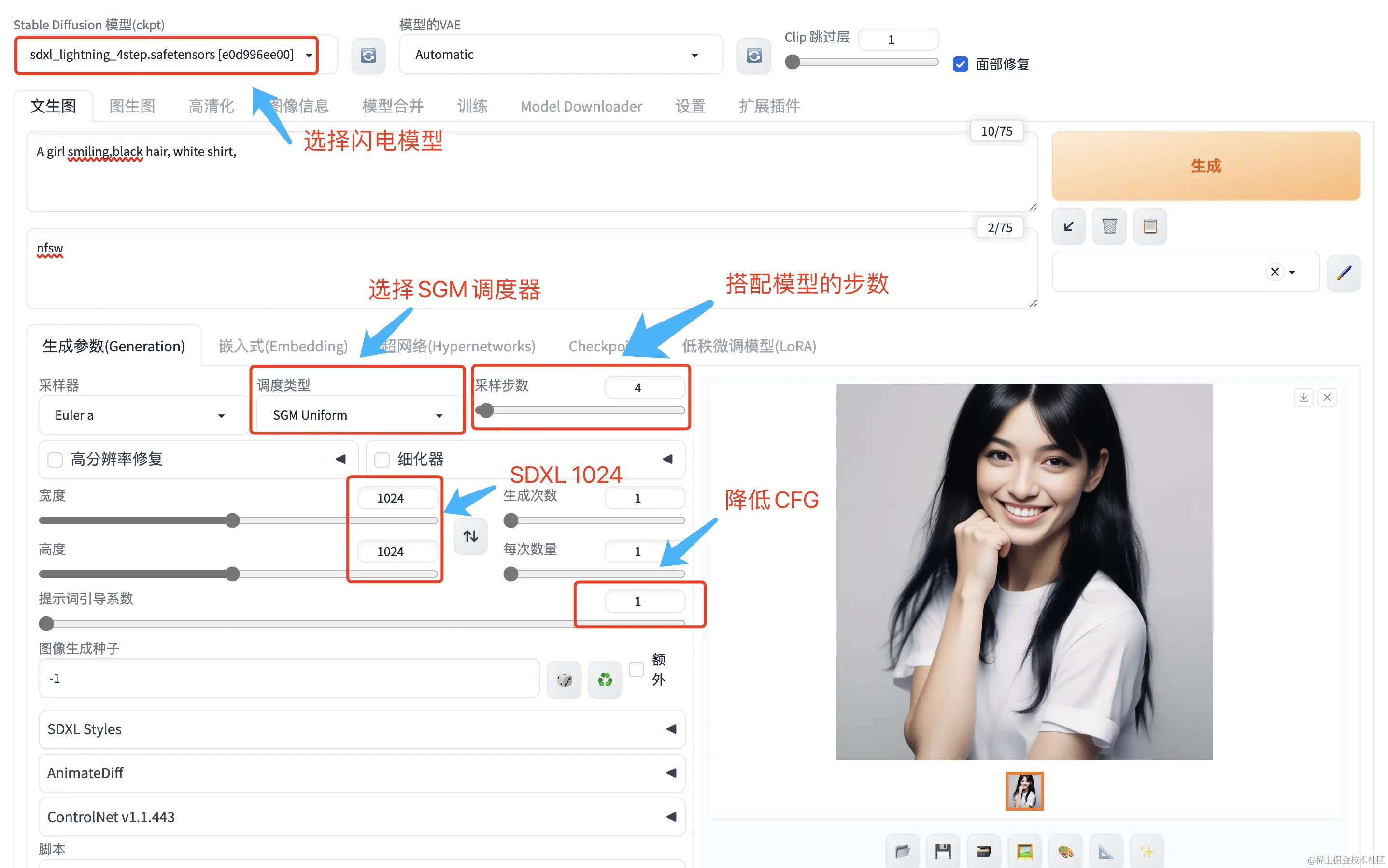
SDXL-Lightning模型下载地址见文末。
2、细化器的切换由依赖采样步改为依赖模型时间步
在Stability AI发布SDXL 1.0时,同时发布了一个精修模型,用户可以先使用SDXL 1.0的基础模型生成一张图片,然后再使用SDXL
1.0的精修模型让图片更加完美。
在 Stable Diffusion WebUI
之前的版本中,从基础模型到精修模型的切换时机依赖的是采样步数,如下图所示:在迭代步数为20,切换点为0.8的设置下,前16步采样将使用基础模型,后4步采样将采用精修模型。
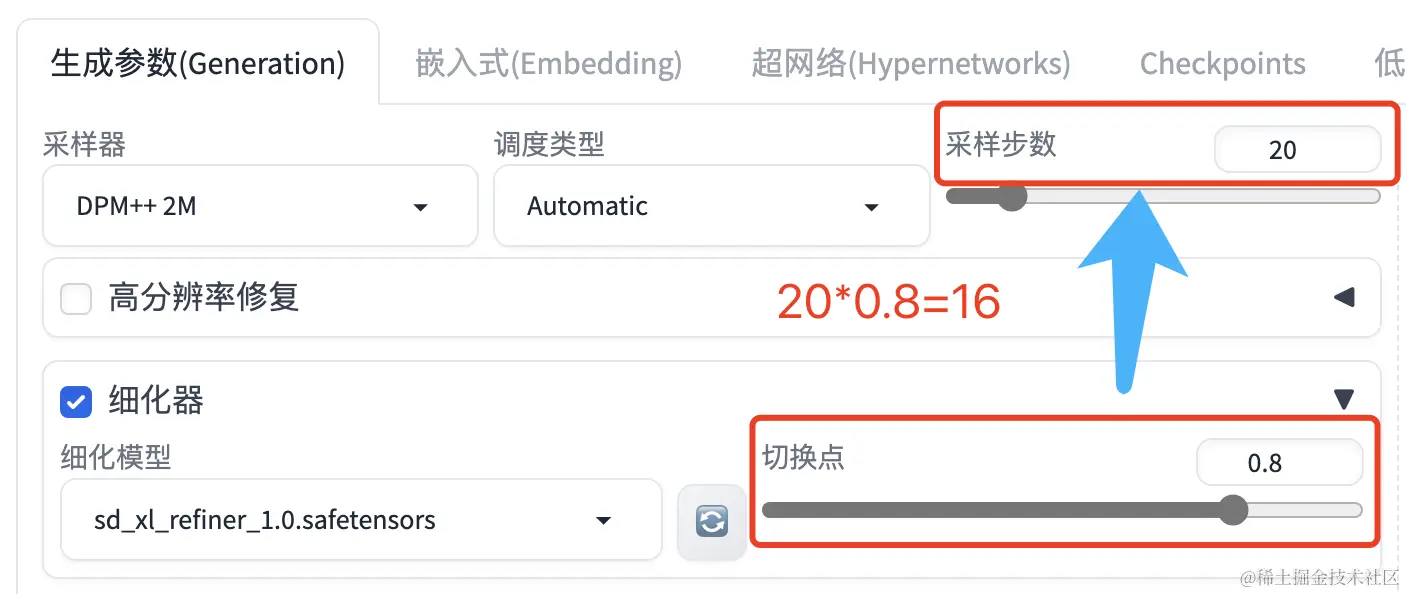
但是依赖采样步存在问题:因为精修模型是在基础模型的最后若干个时间步上训练的,而不是在采样步上训练的,使用不同的调度器时它们俩是不同步的。如果依赖的是采样步,不同的调度器下想要达到同样的图片质量,我们必须修改“切换点”,才能让精修模型更好的发挥作用。比如在文生图时,默认调度器的“切换点”是0.8,但是Karras调度器的“切换点”可能需要是0.88,这不好理解,也不方便使用。
“切换点”依赖时间步后,针对不同的调度器,我们可以统一使用相同的“切换点”取值,让精修模型都能正常发挥作用。现在,对于SDXL 1.0
发布的精修模型,无论采用什么调度器,0.8是个正确值。
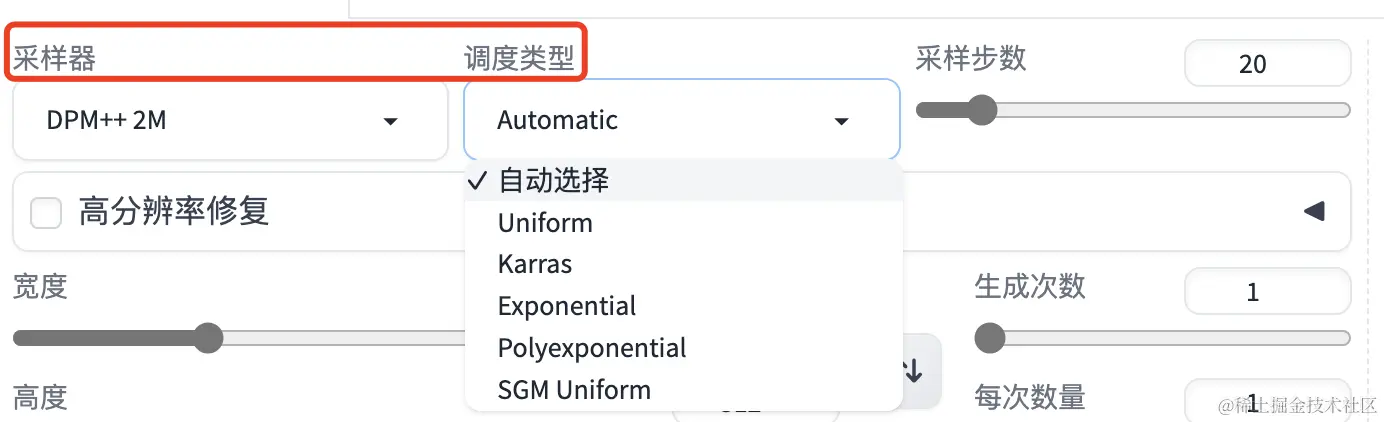
3、调度器从采样方法中独立出来
在生成图片的时间维度上,调度器用来控制噪音水平,也就是控制每次采样时增加多少噪音进去,不同的调度器有不同的噪音控制曲线,对生成图片的质量有一定的影响。
之前它是和采样方法放到一起的,采样方法是去除噪音的算法,比如 DPM++ 2M Karras,其中的Karras就是调度器,DPM++
2M才是真正的采样方法。现在为了更容易控制和理解,它们分家了。
默认是Automatic,也就是自动选择,大家应该也不用太关心。除非是生成图片的效果不佳,你可以试试用不同的调度器,看看会不会有所提升。
4、1.9.0的完整发布说明
功能改进
- 根据模型时间步切换细化器,而非依赖采样步(#14978)
- 增加选项使用旧版目录视图替换树状视图,额外网络排序与搜索控制样式调整
- 添加用户界面以重新排列回调,并支持在扩展元数据中指定回调顺序(#15205)
- 为SDXL-Lightning模型引入统一的调度器(#15325)
- 主界面中新增调度器选择功能(#15333, #15361, #15394)
细节优化
- “打开图片目录”按钮现在直接打开实际目录(#14947)
- 支持使用LyCORIS BOFT网络进行推理(#14871, #14973)
- 默认将额外网络卡片描述设为纯文本,提供选项恢复原HTML格式
- 额外网络添加调整大小手柄(#15041)
- 命令行参数:–unix-filenames-sanitization 和 --filenames-max-length(#15031)
- 以HTML表格形式显示额外网络参数,而非原始JSON(#15131)
- 为LoRA/LoHa/LoKr添加DoRA(权重分解)支持(#15160, #15283)
- 添加–no-prompt-history命令行参数以禁用上一代提示历史记录(#15189)
- 在“替换预览”时更新预览(#15201)
- 仅针对扩展插件活跃Git分支获取更新(#15233)
- 将额外网络的上采样后处理UI放入折叠面板(#15223)
- 支持拖放URL以读取信息文本(#15262)
- 使用diskcache库进行缓存(#15287, #15299)
- 允许在“额外”标签页使用PNG-RGBA格式(#15334)
- 支持在safetensors元数据中嵌入封面图像(#15319)
- 使用NN上采样时加快中断速度(#15380)
- 额外上采样器:添加输入字段限制输出图像最大边长(#15293, #15415, #15417, #15425)
- 增加选项隐藏“额外”标签页中的后处理选项
扩展与API
- ResizeHandleRow:允许覆盖列缩放参数(#15004)
- 提前调用script_callbacks.ui_settings_callback;修复内置扩展插件因使用不存在的设置导致UI崩溃问题
- 使在WebUI外部环境使用zoom.js成为可能(#15286, #15288)
- 允许metadata.ini中使用扩展名称的变体(#15290)
- 使重新加载UI时脚本重载变为可选且默认关闭
- 类似txt2img函数,在img2img函数开头添加gr.Request请求
- 将open_folder作为实用工具(#15442)
- 支持以import scripts.方式导入扩展插件的脚本文件(#15423)
性能优化
- 额外网络HTML页面性能优化
- 额外网络过滤性能优化
- 额外网络排序性能优化
漏洞修复
- 防止在尚未生成图像时按Esc键触发中断
- [修复]避免在修复图像时双重上采样(#14966)
- 可能修复某些情况下额外网络“刷新”按钮不出现的问题
- 修复运行“分割过大图像”时split_threshold参数无效(#15006)
- 修复垂直布局(移动设备)中调整大小手柄的可见性(#15010)
- 为mtime添加register_tmp_file(#15012)
- 在细化器切换过程中保护alpas_cumprod(#14979)
- 修复API加载图像时EXIF方向问题(#15062)
- 只有在提示中实际使用时才覆盖强调(#15141)
- 修复params.txt中缺少强调信息文本(#15142)
- 修复extract_style_text_from_prompt #15132(#15135)
- 修复AnimateDiff的Soft Inpaint(#15148)
- 编辑注意力:取消选中周围空格(#15178)
- 修复字体未加载(#15183)
- 在按路径排序额外网络时使用自然排序
- 修复内置LoRA系统因torch.nn.MultiheadAttention引发的问题(#15190)
- 避免从get_learned_conditioning获取None值引发错误(#15191)
- 写入元数据后向MassFileLister添加条目(#15199)
- 修复使用高分辨率提示时的Styles问题(#15269, #15276)
- 去除高分辨率修复提示中的注释(#15263)
- 使imageviewer事件监听器与浏览器保持一致(#15261)
- 修复OFT尝试获取MultiheadAttention权重时的AttributeError(#15260)
- 恢复缺失的.mean()(#15239)
- 修复“恢复进度”按钮(#15221)
- 修复InputAccordion [custom_script_source]的ui-config(#15231)
- 处理wheel deltaY为0的情况(#15268)
- 防止Firefox显示Alt菜单(#15267)
- 修复语法错误(#15179)
- 恢复输出路径(#15307)
- 转义btn_copy_path中的文件名(#15316)
- 修复文件名包含撇号时额外网络按钮问题(#15331)
- 转义LoRA随机提示生成器中的括号(#15343)
- 修复Python版本检查以确保与PyTorch安装兼容性(#15390)
- 修复call_queue.py中的拼写错误(#15386)
- 修复通过数组索引查找已加载模型时的问题(#15382)
- 修复SD模型内存管理的小问题(#15350)
- 修复CodeFormer权重(#15414)
- 修复:移除ordered_callbacks_map中的脚本回调(#15428)
- 修复由Sylwia提出的文件写入限制问题
- 修复额外单张图像API上采样失败(#15465)
- 处理paste_field可调用对象的错误(#15470)
硬件支持
- 添加对Ascend NPU的训练支持并更改lspci(#14981)
- 更新至ROCm5.7和PyTorch(#14820)
- 对Navi1提供更佳解决方案,移除Navi3的–pre标记(#15224)
- Ascend NPU维基页面(#15228)
其他
- 更新Pad prompt/negative prompt v0的注释,加入关于截断的警告,并使其覆盖v1实现
- 支持触屏(平板电脑)调整列宽(#15002)
- 通过使用翻译内容解决类别映射问题来修复#14591(#14995)
- 使用绝对路径表示规范化文件路径(#15035)
- resizeHandle处理双击(#15065)
- 添加–dat-models-path命令行标志(#15039)
- 添加直接链接至二进制发行版(#15059)
- upscaler_utils:减少日志记录(#15084)
- 修复多个拼写错误(使用crate-ci/typos)(#15116)
- 修复jpeg
针对各位AIGC初学者,这里列举了一条完整的学习计划,感兴趣的可以阅读看看,希望对你的学习之路有所帮助,废话不多说,进入正题:目标应该是这样的:
第一阶段(30天):AI-GPT从入门到深度应用
该阶段首先通过介绍AI-GPT从入门到深度应用目录结构让大家对GPT有一个简单的认识,同时知道为什么要学习GPT使用方法。然后我们会正式学习GPT深度玩法应用场景。
-----------
- GPT的定义与概述
- GPT与其他AI对比区别
- GPT超强记忆力体验
- 万能GPT如何帮你解决一切问题?
- GPT表达方式优化
- GPT多类复杂应用场景解读
- 3步刨根问底获取终极方案
- 4步提高技巧-GPT高情商沟通
- GPT深度玩法应用场景
- GPT高级角色扮演-教学老师
- GPT高级角色扮演-育儿专家
- GPT高级角色扮演-职业顾问
- GPT高级角色扮演-专业私人健身教练
- GPT高级角色扮演-心理健康顾问
- GPT高级角色扮演-程序UX/UI界面开发顾问
- GPT高级角色扮演-产品经理
- GPT高级技巧-游戏IP角色扮演
- GPT高级技巧-文本冒险游戏引导
- GPT实操练习-销售行业
- GPT实操练习-菜谱推荐
- GPT实操练习-美容护肤
- GPT实操练习-知识问答
- GPT实操练习-语言学习
- GPT实操练习-科学减脂
- GPT实操练习-情感咨询
- GPT实操练习-私人医生
- GPT实操练习-语言翻译
- GPT实操练习-作业辅导
- GPT实操练习-聊天陪伴
- GPT实操练习-育儿建议
- GPT实操练习-资产配置
- GPT实操练习-教学课程编排
- GPT实操练习-活动策划
- GPT实操练习-法律顾问
- GPT实操练习-旅游指南
- GPT实操练习-编辑剧本
- GPT实操练习-面试招聘
- GPT实操练习-宠物护理和训练
- GPT实操练习-吸睛爆款标题生成
- GPT实操练习-自媒体爆款软件拆解
- GPT实操练习-自媒体文章创作
- GPT实操练习-高效写作推广方案
- GPT实操练习-星座分析
- GPT实操练习-原创音乐创作
- GPT实操练习-起名/解梦/写诗/写情书/写小说
- GPT提升工作效率-Word关键字词提取
- GPT提升工作效率-Word翻译实现
- GPT提升工作效率-Word自动填写、排版
- GPT提升工作效率-Word自动纠错、建议
- GPT提升工作效率-Word批量生产优质文章
- GPT提升工作效率-Excel自动化实现数据计算、分析
- GPT提升工作效率-Excel快速生成、拆分及合并实战
- GPT提升工作效率-Excel生成复杂任务实战
- GPT提升工作效率-Excel用Chat Excel让效率起飞
- GPT提升工作效率–PPT文档内容读取实现
- GPT提升工作效率–PPT快速批量调整PPT文档
- GPT提升工作效率-文件批量创建、复制、移动等高效操作
- GPT提升工作效率-文件遍历、搜索等高效操作
- GPT提升工作效率-邮件自动发送
- GPT提升工作效率-邮件自动回复
- GPT接入QQ与QQ群实战
- GPT接入微信与微信群实战
- GPT接入QQ与VX多用户访问实战
- GPT接入工具与脚本部署实战
第二阶段(30天):AI-绘画进阶实战
该阶段我们正式进入AI-绘画进阶实战学习,首先通过了解AI绘画定义与概述 ,AI绘画的应用领域 ,PAI绘画与传统绘画的区别 ,AI绘画的工具分类介绍的基本概念,以及AI绘画工具Midjourney、Stable Diffusion的使用方法,还有AI绘画插件和模板的使用为我们接下来的实战设计学习做铺垫。
- -----------
AI绘画定义与概述 - AI绘画的应用领域
- AI绘画与传统绘画的区别
- AI绘画的工具分类介绍
- AI绘画工具-Midjourney
- AI绘画工具-百度文心一格
- AI绘画工具-SDWebUI
- AI绘画工具-Vega AI
- AI绘画工具-微信中的AI绘画小程序
- Midjourney学习-Discord账号的注册
- Midjourney Bot界面讲解
- Midjourney提示词入门
- Midjourney高级提示词
- Midjourney版本参数学解读
- Midjourney功能参数
- Midjourney上采样参数
- AI绘画组合应用1-Midjourney + GPT
- AI绘画组合应用2-Stable Diffusion + GPT
- AI绘画组合应用3-AI绘画+ GPT +小红书
- AI绘画组合应用4-AI绘画+ GPT +抖音
- AI绘画组合应用5-AI绘画+ GPT +公众号
- AI绘画组合应用6-AI绘画+ GPT + AI视频
- AI绘画组合应用7-AI绘画+ GPT + 小说人物/场景
- AI绘画设计-Logo设计
- AI绘画设计-套用万能公式
- AI绘画设计-引用艺术风格
- AI绘画设计-GPT加速设计方案落地
- AI绘画设计-Vega AI渲染线稿生成设计
- AI绘画设计-摄影
- AI绘画设计-头像设计
- AI绘画设计-海报设计
- AI绘画设计-模特换装
- AI绘画设计-家具设计
- AI绘画设计-潘顿椅设计
- AI绘画设计-沙发设计
- AI绘画设计-电视柜设计
- AI绘画设计-包装设计的提示词构思
第三阶段(30天):AI-视频高段位
恭喜你,如果学到这里,你基本可以找到一份AIGC副业相关的工作,比如电商运营、原画设计、美工、安全分析等岗位;如果新媒体运营学的好,还可以从各大自媒体平台收获平台兼职收益。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- -----------
AI视频定义与概述 - AI视频制作-方案与创新
- AI视频制作-各种工具实操
- AI视频制作-美学风格(油画/插画/日漫/水墨)
- AI视频制作-形象设定(人物形象服装/造型/表情)
- AI视频画面特效处理
- AI视频画面拼接
- AI视频画面配音
- AI视频画面包装
- AI视频锁定人物逐一精修
- 多种表情动作/情节
- 动态模型转换-视频内部元素关键帧
- 动态模型转换-图像整体运动
- 动态模型转换-虚拟人
- 动态模型转换-表面特效
- AI自媒体视频-深问GPT,获取方案
- AI自媒体视频-风格设置(诗歌/文言文等)
- AI自媒体视频-各行业创意视频设计思路
- AI视频风格转换
- AI视频字数压缩
- AI视频同类型衍生
- AI视频Pormpt公式
第四阶段(20天):AI-虚拟数字人课程
- -----------
AI数字人工具简介 - AI工作台界面功能展示及介绍
- AI数字人任务确定
- AI数字人素材准备
- AI知识、语料的投喂
- AI模型训练
- AI训练成果展示及改进
- AI数字人直播系统工具使用
- AI人物在各平台直播
- AI数字人在OBS平台直播
第五阶段(45天以上):AIGC-多渠道变现课程
该阶段是项目演练阶段,大家通过使用之前学习过的AIGC基础知识,项目中分别应用到了新媒体、电子商务等岗位能帮助大家在主流的新媒体和电商平台引流和带货变现。
-----------
- AI-小红书引流变现
- AI-公众号引流变现
- AI-知乎引流变现
- AI-抖音引流/带货变现
- AI-写作变现
- AI-B站引流变现
- AI-快手引流变现
- AI-百家号引流变现
- AI-制作素材模板出售变现
- AI-周边定制变现
- AI-手机壳图案定制变现
- AI-周边产品定制变现
- AI-服装图案定制变现
- AI-个性头像定制变现
- AI-起号与知识付费变现
- AI-实现淘宝销售变现
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名AIGC的正确特征了。
这份完整版的AIGC资料我已经打包好,需要的点击下方二维码,即可前往免费领取!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









