







随着大型互联网应用的发展,海量数据的存储和访问成为系统设计的瓶颈,分布式处理成为不二选择。数据库拆分,特别是水平分库是个高难度的活,涉及一系列技术决策。
本人有幸负责1号店订单水平分库的方案设计及实施落地,本人结合项目实践,对水平分库做一个系统地剖析,希望为大家水平分库(包括去IOE)改造提供总体思路,主要内容包括:
水平分库说明
分库维度-- 根据哪个字段分库
分库策略-- 记录如何分配到不同库
分库数量-- 初始库数量及库数量如何增长
路由透明-- 如何实现库路由,支持应用透明
分页处理-- 跨多个库的分页case如何处理
Lookup映射—非分库字段映射到分库字段,实现单库访问
整体架构-- 分库的整体技术架构
上线步骤-- 分库改造实施上线
项目总结
水平分库说明
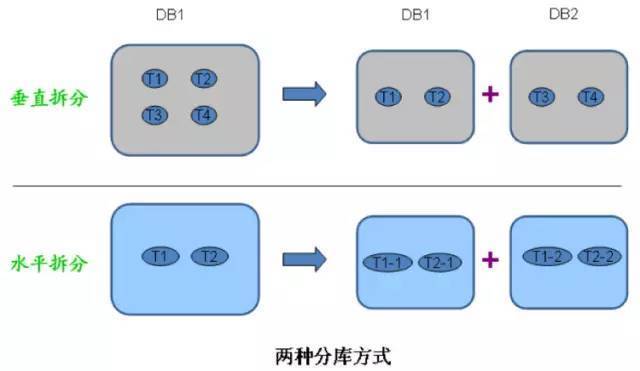
1) 垂直分库
数据库里的表太多,拿出部分到新的库里,一般是根据业务划分表,关系密切的表放同一数据库,应用修改数据库连接即可,比较简单。
2) 水平分库
某张表太大,单个数据库存储不下或访问性能有压力,把一张表拆成多张,每张表存放部分记录,保存在不同的数据库里,水平分库需要对系统做大的改造。
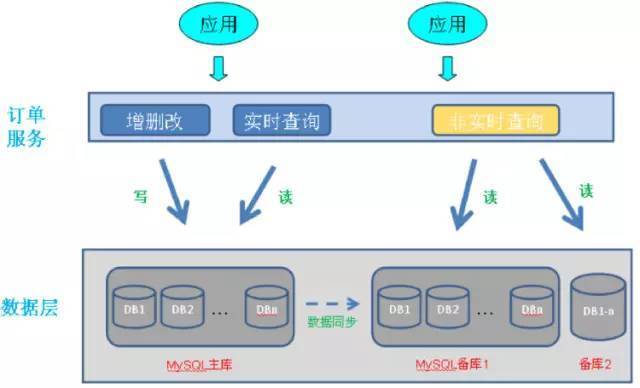
1号店核心的订单表存储在Oracle数据库,记录有上亿条,字段有上百个,访问的模式也是复杂多样,随着业务快速增长,无论存储空间或访问性能都面临巨大挑战,特别在大促时,订单库已成为系统瓶颈。
通常有两种解决办法:
Scale up,升级Oracle数据库所在的物理机,提升内存/存储/IO性能,但这种升级费用昂贵,并且只能满足短期需要。
Scale out ,把订单库拆分为多个库,分散到多台机器进行存储和访问,这种做法支持水平扩展,可以满足长远需要。1号店采取后一种做法,它的订单库主要包括订单主表/订单明细表(记录商品明细)/订单扩展表,水平分库即把这3张表的记录分到多个数据库中,订单水平分库效果如下图所示:















 2871
2871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









