







参考代码:https://nbviewer.jupyter.org/github/python-visualization/folium/tree/master/examples/
初次接触阿里云的天池实验室,对【入门级-用Pandas揭秘美国选民的总统喜好】中的热力图可视化各州捐款数,进行 菜鸟 实践,特别用到了python中的Folium库,打开了新世界的大门。由于之前实践过高德API,也发现Folium库算是地图的底层。(有关地图的库,实际应该还有其他,还未逐一实践)
以下主要总结个人针对Folium库的实践经历,特别是热力图、时间轴和时序数据的绘制,其中也会掺杂其他一些pandas,datetime小tip。
具体请结合【参考代码】
1.地图初始化:
m = folium.Map([43, -100], tiles="stamentonerbackground", zoom_start=4)
对应:中心点位置,地图样式,地图放大级别
【地图样式选择:stamentonerbackground,cartodbpositron,OpenStreetMap…(第24条)】
2.地图自定义–Colormaps.ipynb
def my_color_function(feature):
"""Maps low values to green and high values to red."""
if unemployment_dict[feature["id"]] > 6.5:
return "#ff0000"
else:
return "#008000"
m = folium.Map([43, -100], tiles="cartodbpositron", zoom_start=4)
folium.GeoJson(
geo_json_data,
style_function=lambda feature: {
"fillColor": my_color_function(feature),
"color": "black",
"weight": 2,
"dashArray": "5, 5", #边界线设置
},
).add_to(m)
自定义地图层颜色,引入geo_json_date数据集,是对美国各州边界的划分。设置颜色函数,对区域进行填充。
针对geo_json_date数据集的格式如下;
import json
import folium
import pandas as pd
import requests
url = (
"https://raw.githubusercontent.com/python-visualization/folium/master/examples/data"
)
us_states = f"{url}/us-states.json"
geo_json_data = json.loads(requests.get(us_states).text) #边界
folium对于美国各州绘制的数据格式为:
{‘type’: ‘FeatureCollection’,
‘features’: [{‘type’: ‘Feature’,
‘id’: ‘AL’, –州简称
‘properties’: {‘name’: ‘Alabama’},–州全称
‘geometry’: {‘type’: ‘Polygon’,–州的形状
‘coordinates’: [[[-87.359296, 35.00118], –边界点
[-85.606675, 34.984749],
[-85.431413, 34.124869],
[-85.184951, 32.859696]…]]}},
{‘type’: ‘Feature’,
‘id’: ‘AK’,
‘properties’: {‘name’: ‘Alaska’},
‘geometry’: {‘type’: ‘MultiPolygon’,
‘coordinates’: [[[[-131.602021, 55.117982],…
3.渐变色选择–Colormaps.ipynb
OrRd_09 等等
4.放置标记–ContinuousWorld.ipynb
folium.Marker(
location=[0, 0], popup="I will disapear when moved outside the wrapped map domain."
).add_to(m)
对应 放置位置,点击后marker的话语,
5.放置图片–CustomIcon.ipynb
※6. 放置标签–CustomPanes.ipynb
(1)未放置标签:
m = folium.Map([43, -100], zoom_start=4, tiles="stamentoner")
folium.GeoJson(geo_json_data).add_to(m)
m
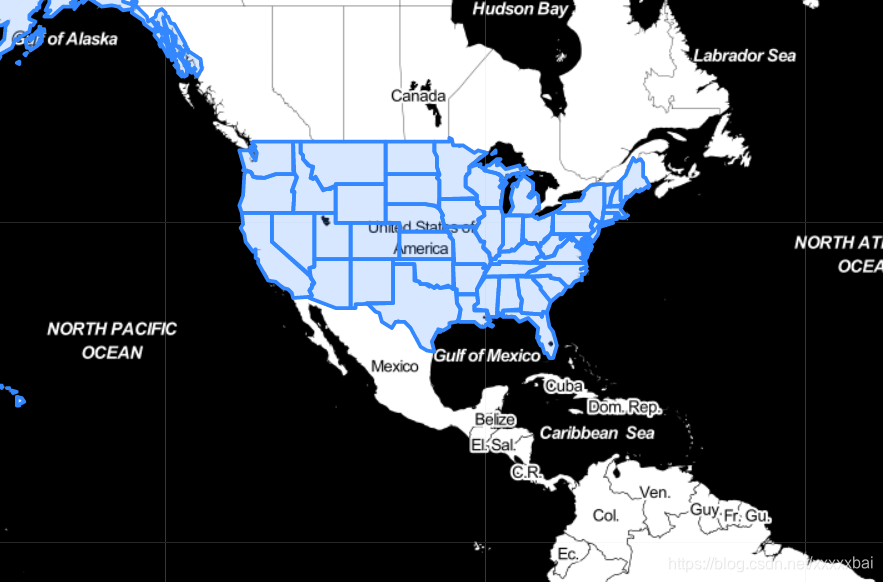
(2) 放置标签
m = folium.Map([43, -100], zoom_start=4, tiles="stamentonerbackground")
folium.GeoJson(geo_json_data).add_to(m)
folium.map.CustomPane("labels").add_to(m) #放置1
# Final layer associated to custom pane via the appropriate kwarg
folium.TileLayer("stamentonerlabels", pane="labels").add_to(m) #放置2
m
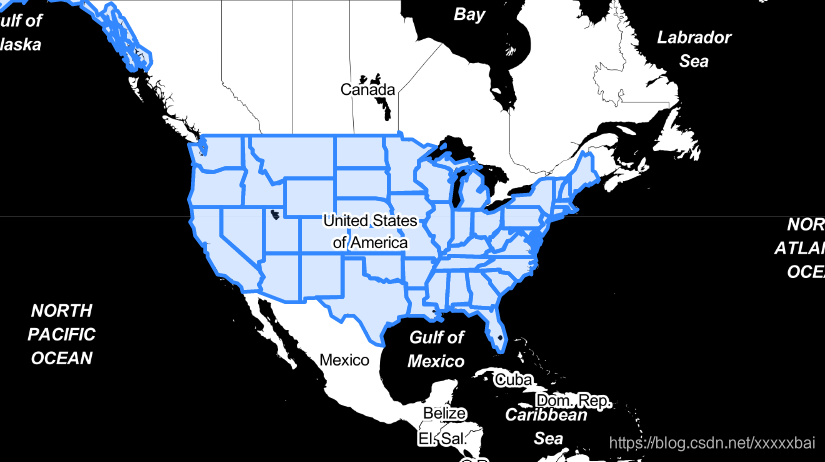
逐步放大可显示各个州的名称。
7.图标分层–FeatureGroup.ipynb
LayerControl()–使得图标可展示可不展示
8.加各种形状图标以及画子图—Features.ipynb
(1)画图标:ColorLine–画圆
(2)Marker:标记属性,标记大小,位置,标记点击显示提示内容…
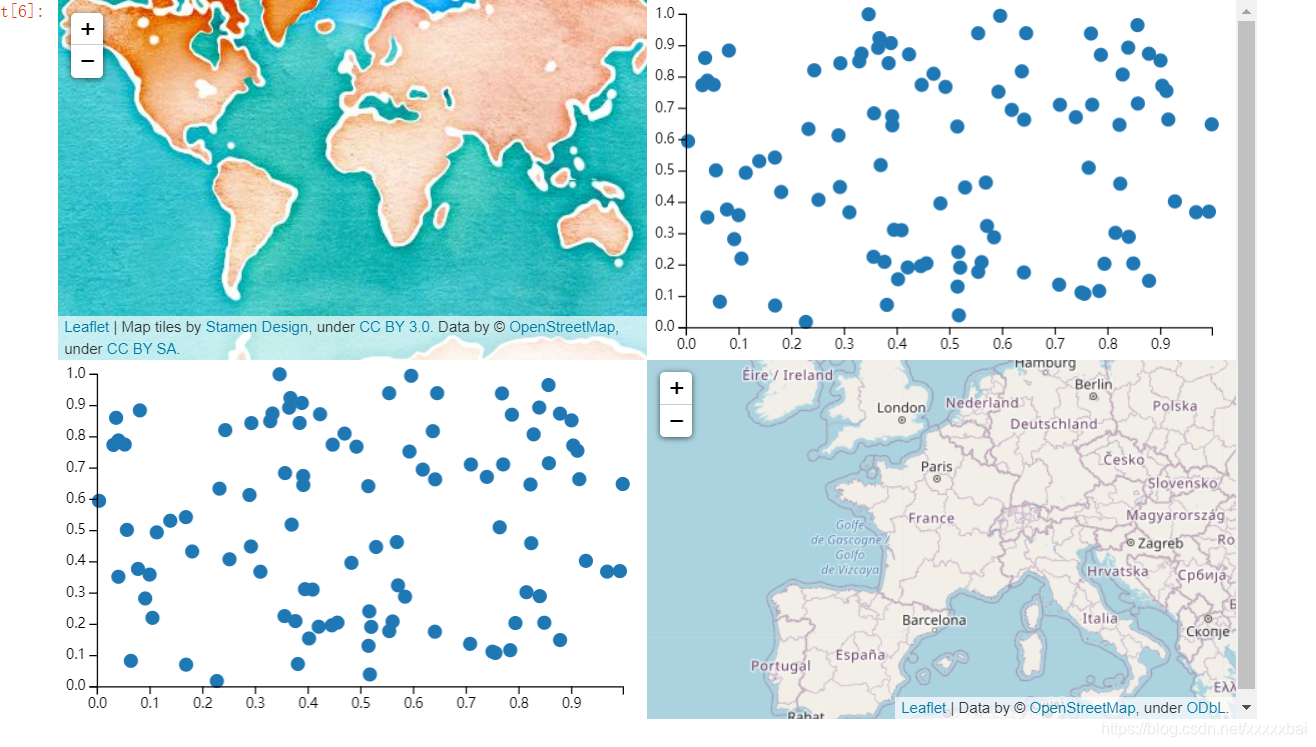
(3)子图:
mport branca
N = 100
multi_iter2 = {
"x": np.random.uniform(size=(N,)),
"y": np.random.uniform(size=(N,)),
}
scatter = vincent.Scatter(multi_iter2, iter_idx="x", height=250, width=420)
data = json.loads(scatter.to_json())
f = branca.element.Figure()
# Create two maps.
m = folium.Map(
location=[0, 0],
tiles="stamenwatercolor",
zoom_start=1,
position="absolute",
left="0%",
width="50%",
height="50%",
)
m2 = folium.Map(
location=[46, 3],
tiles="OpenStreetMap",
zoom_start=4,
position="absolute",
left="50%",
width="50%",
height="50%",
top="50%",
)
# Create two Vega.
v = features.Vega(data, position="absolute", left="50%", width="50%", height="50%")
v2 = features.Vega(
data, position="absolute", left="0%", width="50%", height="50%", top="50%"
)
f.add_child(m)
f.add_child(m2)
f.add_child(v)
f.add_child(v2)
f
两个地图+两个散点图
(4)GeoJson:一次性添加多个marker
9.FloatImage.ipynb–地图上添加图片
10.GeoJSONWithoutTitles.ipynb–背景自定义(可以加栅格,但是栅格大小会变)
※11. 地理数据处理及热力图(区域)-- GeoJSON_and_choropleth.ipynb
(1)数据准备:上面的GeoJson或者geopandas库
geopandas库包含地理数据:
import geopandas
gdf = geopandas.read_file(us_states)
m = folium.Map([43, -100], zoom_start=4)
folium.GeoJson(
gdf,
).add_to(m)
m
(2)点击地图某一位置,自动放大-- zoom_on_click
m = folium.Map([43, -100], zoom_start=4)
folium.GeoJson(geo_json_data, zoom_on_click=True).add_to(m)
m
(3)自定义显示颜色
#提供函数的好处在于,您可以根据特性指定样式。例如,如果你想用绿色显示所有名字中包含字母“E”的州,只需:
m = folium.Map([43, -100], zoom_start=4)
folium.GeoJson(
geo_json_data,
style_function=lambda feature: {
"fillColor": "green"
if "e" in feature["properties"]["name"].lower()
else "#ffff00",
"color": "black",
"weight": 2,
"dashArray": "5, 5",
},
).add_to(m)
m
※(4)热力图(区域)–Choropleth
m = folium.Map([43, -100], zoom_start=4)
folium.Choropleth(
geo_data=us_states,
fill_opacity=0.3,
line_weight=2,
).add_to(m)
m
这个类可以将GeoJSON的图形覆盖到地图上。如果不绑定数据则显示单色的地图,如果绑定数据则通过值得大小显示不同颜色。具体使用方法:
class folium.features.Choropleth(geo_data, data=None, columns=None, key_on=None, bins=6, fill_color=None, nan_fill_color='black', fill_opacity=0.6, nan_fill_opacity=None, line_color='black', line_weight=1, line_opacity=1, name=None, legend_name='', overlay=True, control=True, show=True, topojson=None, smooth_factor=None, highlight=None, **kwargs)
参数说明:
geo_data:指定GeoJSON,可以是JsonURL、file path或其他类型 (json、dict、geopandas等)的GeoJSON几何数据
data:需要绑定的GeoJSON的数据,默认为空。传入的数据可以是Pandas DataFrame或Series,具体Series没有使用过,拆测如果传Series需要将index设置为匹配项。
columns:当数据传入的时Pandas DataFrame设定想要的值,第一列需要与GeoJSON匹配的列,第二列为具体的值
key_on:GeoJSON中需要绑定的列,默认为空。格式中需要以feature对象开头,如id或 feature.properties.statename
bins:设定对值要划分的数量,默认为6,如果传入的是数值,则传入数字时,会使用data中的最大值和最小值进行平均划分。如果传入的是一个序列,则会按序列定义边界。同时也可以传入字符串,可传入的字符串可以从histogram的文档中找到。
fill_color:区域需要填充的颜色,默认为blue,可以传入16进制的颜色代码或颜色名称,如果绑定了数据,则可以传入“颜色地图”,比如:‘BuGn’, ‘BuPu’, ‘GnBu’, ‘OrRd’, ‘PuBu’, ‘PuBuGn’, ‘PuRd’, ‘RdPu’, ‘YlGn’, ‘YlGnBu’, ‘YlOrBr’, and ‘YlOrRd’.
nan_fill_color:NaN区域填充的颜色,默认为’black’,即GeoJSON中没有匹配到的图形填充的颜色。
fill_opacity :填充颜色的透明度,默认为6,可选值为0-1
nan_fill_opacity:NaN区域填充颜色透明度,默认取fill_opacity的值。
line_color:区域边框颜色,默认为’black’
line_weight:区域边框款对,默认为1
line_opacity:区域边框透明度,默认为1
legend_name:图例标识名称
topojson:除了GeoJson外,同时也支持TopoJSON格式的的边界数据。 (string, default None) – If using a TopoJSON, passing “objects.yourfeature” to the topojson keyword argument will enable conversion to GeoJSON. TopoJSONs can be passed as “geo_data”, but the “topojson” keyword must also be passed with the reference to the topojson objects to convert. See the topojson.feature method in the TopoJSON API reference: https://github.com/topojson/topojson/wiki/API-Reference
smooth_factor:平滑因子,主要为了简化每个缩放级别的折线。数值越大表示越平滑,同时性能也更好,数值越小说明越精确,Leaflet中的默认值为0
highlight:当鼠标悬停在区域上时是否要突出显示,默认为False
name:层的名字,可选。如果设置了可以在LayerControls中出现。
overlay:添加层的设置,默认为True(覆盖层),如果传False则为基础层。
control:是否将图层包含到LayerControls中,默认为True
show:是否在地图打开时就显示层,默认为True
e.g.:
import folium
import pandas as pd
geo_json_data = "data/china_city.json"
df = pd.read_excel("data/orders.xlsx")
m = folium.Map(location=[32, 120], zoom_start=5)
folium.Choropleth(
geo_data=geo_json_data,
data=df,
columns=["cityname", "order_count"],
key_on="feature.properties.name",
fill_color="BuPu",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="Order Count",
).add_to(m)
12.在每个边界对象上显示注释–GeoJsonPopupAndTooltip.ipynb
【这里主要涉及对DataFrame对象的处理】
(觉得画出来的还挺好看的,但是未实践,待补)
13.热力图(点状)–HeatMapWithTime.ipynb,Heatmap.ipynb
可以随时间变化显示点的热力情况
后续会有基于区域热力图进行详细试验,主要涉及时序数据的处理。
14.地图画线-- Highlight_Function.ipynb
15.ImageOverlay.ipynb
16.画多组Marker–MarkerCluster.ipynb
17.添加多个圆–MinMaxLimits.ipynb
18.地图中加小地图–MiniMap.ipynb
19.在设定位置上加图表式的图标–Minicharts.ipynb
可以直观反映这个地方某方面的占比
20.点聚合–Plugins.ipynb
放置多个Marker,放大zoom时,可以将点聚合,显示这一区域有对应几个Marker
21.加各种形状的线以及流动的线-- PolyLineTextPath_AntPath.ipynb
import folium
from folium import plugins
m = folium.Map([30, 0], zoom_start=3)
##流动线的数据形式,注意经纬度放置顺序
wind_locations = [
[59.35560, -31.992190],
[55.178870, -42.89062],
[47.754100, -43.94531],
[38.272690, -37.96875],
[27.059130, -41.13281],
[16.299050, -36.56250],
[8.4071700, -30.23437],
[1.0546300, -22.50000],
[-8.754790, -18.28125],
[-21.61658, -20.03906],
[-31.35364, -24.25781],
[-39.90974, -30.93750],
[-43.83453, -41.13281],
[-47.75410, -49.92187],
[-50.95843, -54.14062],
[-55.97380, -56.60156],
]
wind_line = folium.PolyLine(wind_locations, weight=15, color="#8EE9FF").add_to(m)
m = folium.Map()
folium.plugins.AntPath(
locations=wind_locations, reverse="True", dash_array=[20, 30]
).add_to(m)
m.fit_bounds(m.get_bounds())
m
22.画封闭图形(点连线成面)–Polygons_from_list_of_points.ipynb
23.SmoothFactor.ipynb–边界线平滑
默认情况下,单张中的折线对象是平滑的。这将从行中删除点,在绘图时减少浏览器的负载。
平滑的级别可以在创建任何Polyline对象时通过smoothFactor作为一个选项来指定。在folium中,平滑的级别可以在初始化GeoJson、TopoJson和Choropleth对象时通过传递smooth_factor作为参数来确定。平滑水平没有上界和下界;传单的默认值是1。
folium.TopoJson(
data=topo,
object_path="objects.antarctic_ice_shelf",
name="default_smoothing",
smooth_factor=10, #1的时候不平滑,10的时候,在放大时是很平滑
style_function=lambda x: {"color": "#004c00", "opacity": "0.7"},
).add_to(m)
smooth_factor为平滑程度,随着地图的放大加载,边界显示越来越曲折。
24.地图样式类型–TilesExample.ipynb
※25.时间轴热力图(区域)–TimeSliderChoropleth.ipynb
后续以入门赛为背景详讲
26.在图层上画圆–VectorLayers.ipynb
27.自定义画图形–plugin-Draw.ipynb
28.地图宽高设置-- WidthHeight.ipynb
29.搜索功能–plugin-Search.ipynb
输入城市名字,会地图展现至对应地方
感觉高德API中很多功能和Folium如出一辙,只是高德有更准确的地理数据,操作简洁,页面美观。Folium库的功能,高德上大部分都有对应的(时间轴的好像没有,一般例如加标记,搜索,路线图,热力图,聚合等等高德都是有的)。
但是高德只能做固定结果的呈现。对Folium,可以自己改代码,跑代码,更进一步体会Python的魅力~
后面写Folium在【入门级-用Pandas揭秘美国选民的总统喜好】的应用~~
(加※号的在里面有更具体的实践)















 2503
2503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









