






- 在学习《Web Scraping with Python》,发现第32页下面这段代码报错。这段代码的意思是将某个页面全部爬下来。
#!/usr/bin/env python
#coding=utf8
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon")
bsObj = BeautifulSoup(html)
for link in bsObj.findAll("a"):
if "href" in link.attrs:
print (link.attrs['href'])经查询,在python3.5版本中是使用urllib.request,而在python2.7中则是urllib2
修改后,在python2.7中运行上面的代码会有警告:
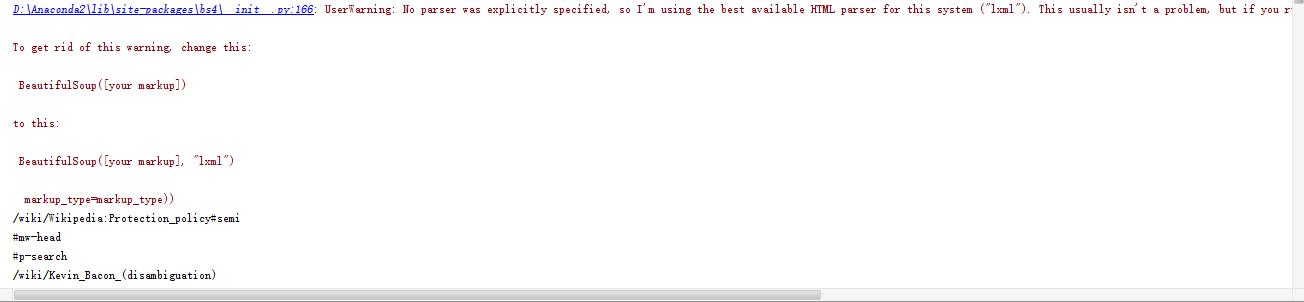
- 这里的警告,并不是说有错误,只是习惯在使用时加上lxml
修改后
#!/usr/bin/env python
#coding=utf8
from urllib2 import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon")
bsObj = BeautifulSoup(html,"lxml")
for link in bsObj.findAll("a"):
if "href" in link.attrs:
print (link.attrs['href'])













 32
32











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









