







要用好链表的首要前提就是要理解什么是链表。
链表是用任意存储单元来存放数据的,这个存储单元可以使连续的,也可以是不连续的。为了正确的表示元素间的逻辑关系,在存储每个元素值得同时还必须存储指示其后继或是前驱元素的地址信息。这两部分信息组成数据元素的存储映像即结点。包含两个域,数据域和指针域。故而可以用结构体来表示链表中的结点,并且每个新结点使用前都要动态分配存储空间。
如果想要了解清楚p->next,p=r;p=p->next;p->next=r->next;等的具体含义,可以在程序语言中设置断点并调试,在调试变量窗口中查看它们的变化与不同,从而深入的理解链表的基本用法。其他的就是思维上的问题了,比如在某个节点p前插入元素,形象的说就是在这个链表该元素的位置切开,将新元素放进去,再连接好这条链表的断裂处(将p的link域地址改为新节点地址,将新节点link域改为p的下一节点地址,这样就连接好了断裂处,这是对单链表而言的,双链表情况是类似的)。
下面就先看看单链表及其构建、元素查找、插入、删除等操作的函数是怎么实现的吧。代码后的运行结果展示可以很清楚的看到各个操作之后新链表的情况。
#include "iostream"
using namespace std;
//单链表用法
typedef struct node
{
int data;
struct node *next;
}linklist;
linklist* creat(int n)//尾插法建立单链表,即头结点非空,为第一个节点
{
linklist*head,*New,*tail;
head=NULL;
tail=NULL;
for (int i=1;i<=n;i++)
{
New=(linklist*)malloc(sizeof(linklist));
New->data=i;
if(head==NULL) head=New;
else tail->next=New;
tail=New;
}
if(tail!=NULL) tail->next=NULL;
return head;
}
void print(linklist*head)//输出链表元素值
{
while (head)
{
printf("%d ",head->data);
head=head->next;
}
}
linklist*Get(linklist*head,int i) //按序号查找链表的值
{
int j=1;
linklist*p=head;
while (p!=NULL&&j<i)
{
p=p->next;
j++;
}
if(i==j) return p;
else return NULL;
}
linklist*Locate(linklist*head,int key) //按值查找单链表数据
{
linklist*p=head; //要从第一个节点开始查找,因为head为第一个节点(非空)
while (p!=NULL&&p->data!=key)
p=p->next;
if(p==NULL) return NULL;
else return p;
}
void InsertAfter(linklist*p,int x)//将值为x的新节点插入p节点后
{
linklist*s;
s=(linklist*)malloc(sizeof(linklist));
s->data=x;
s->next=p->next; //将数据插入最后一个元素之后会出问题吗??
//答:不会!
p->next=s;
}
void InsertBefore(linklist*head,linklist*p,int x)//将值为x的新节点插入p节点前
{
linklist*s,*q;
s=(linklist*)malloc(sizeof(linklist));
s->data=x;
q=head;
//不能在第一个节点前插入数据吗??
//答:不能,因为第一个节点在此为头结点,而头结点没有前驱节点
//如果将q->next改为q,那么当在头结点插入元素x时就形成了无限的循环链表,节点数为2:head和s
while(q->next!=p)
q=q->next;
s->next=p;
q->next=s;
}
void Delete(linklist*head,linklist*p)//删除链表元素
{
linklist*q;
q=head;
while (q->next!=p)//能删除最后一个,但是不能删除第一个,理由和InsertBefore类似
q=q->next;
q->next=p->next;
free(p);
}
int main()
{
linklist*p=(linklist*)malloc(sizeof(linklist));
linklist*q=(linklist*)malloc(sizeof(linklist));
linklist*r=(linklist*)malloc(sizeof(linklist));
int n;
cout<<"输入创建单链表的节点个数n:";
cin>>n;
cout<<"建立的新链表如下所示:"<<endl;
p=creat(n);
print(p);
cout<<endl;
cout<<"输入按序号查找法想要查找的元素,输入序号小于等于"<<n<<endl;
int m;
cin>>m;
q=Get(p,m);
printf("查找成功:元素为%d\n",q->data);
r=q;
cout<<"输入在链表上述查找元素前插入的数据"<<endl;
int fn;
cin>>fn;
InsertBefore(p,r,fn);
cout<<"插入数据后的新链表为:"<<endl;
print(p);
cout<<endl;
cout<<"在链表上述查找元素之后插入的数据"<<endl;
int an;
cin>>an;
InsertAfter(r,an);
cout<<"插入后新链表为:"<<endl;
print(p);
cout<<endl;
cout<<"删除上述查找的元素"<<m<<endl;
cout<<endl;
Delete(p,r);
cout<<"删除后链表为"<<endl;
print(p);
cout<<endl;
return 0;
}
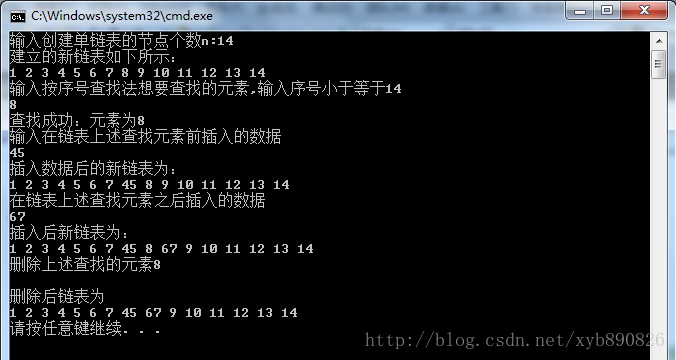
结合上述运行结果图、提示,在对照代码看一遍,基本上单链表的基本用法就掌握了。
双链表在Get、Locate等只涉及一个方向的指针时,是基本一样的。而在删除与插入节点时却大不相同,下面只简略介绍双链表的不同之处,以代码的形式展现,可以对比单链表的相关操作进行学习。
void DeleteNode(linklist*p)
{
p->pre->next=p->next;
p->next->pre=p->pre;
free(p);
}
void InsertBefore(linklist*p,int x)
{
linklist*s;
s=(linklist*)malloc(sizeof(linklist));
s->data=x;
s->pre=p->pre;
s->next=p;
p->pre->next=s;
p->pre=s;
}














 5045
5045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









