







提到肯尼迪遇刺案,中国网友们最先想到什么?是不是脑洞大开?

不过这个梗已经比较过时了,因为咱们的建国同志,每天都在整活。
近日,特朗普依据其竞选承诺,公开了肯尼迪遇刺事件的绝密文件。
文件包含2300多个PDF、总计8万多页,可以在美国国家档案馆网站上下载(地址:https://www.archives.gov/research/jfk/release-2025)。
这些文件不仅包含政府内部通信、目击者证词,还有大量未曾曝光的照片和证据。它们或许能揭示更多关于肯尼迪遇刺事件的细节,甚至挑战我们对这一历史时刻的传统认知。
比如有美国网友看完后感叹,肯尼迪原来是美国最后一任总统呀。

对此,各路吃瓜群众早已各显神通,在AI加持下,对数千份文档进行抓取、解读、联想,以期发现更多细节,证实或证伪几十年来坊间的种种猜测。
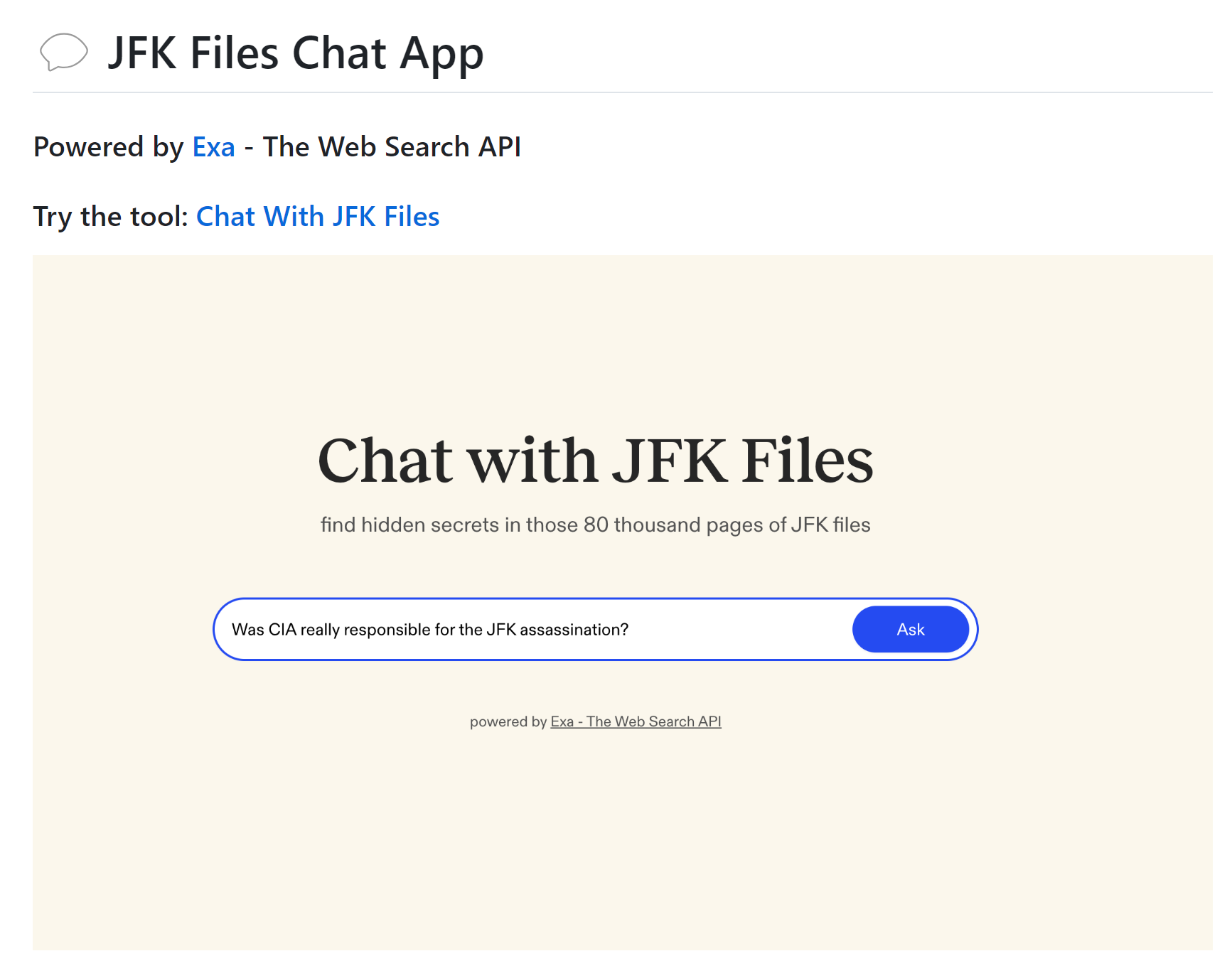
有速度快的专业团队火速发布了基于该文档的聊天应用“Chat With JFK Files”(地址:https://github.com/exa-labs/jfk-files-app),让吃瓜群众可以针对文档内容进行问答(可以中文交互)。
为了更有技术含量地吃瓜,获取案件相关文档是必需的,这就要用到一些爬虫技术。
在本篇文章中,我们将介绍如何使用Python构建一个简单的网络爬虫,从美国国家档案馆网站上下载肯尼迪案件解密文档。
我们将从最基本的下载单个文件开始,逐步扩展功能,直到实现自动解析HTML页面并批量下载多个文件的能力。
0、准备工作
打开肯尼迪遇刺事件记录页面(地址:[https://www.archives.gov/research/jfk/release-2025](https://www.archives.gov/research/jfk/release-2025)),下拉到“Accessing the Records”那部分。这里展示了一个表格,每条记录都包含了文档名称及对应的超链接。点击这些链接可以在浏览器中查看相应文档。值得注意的是,该表格支持显示所有记录,这对后续全量下载非常有帮助。
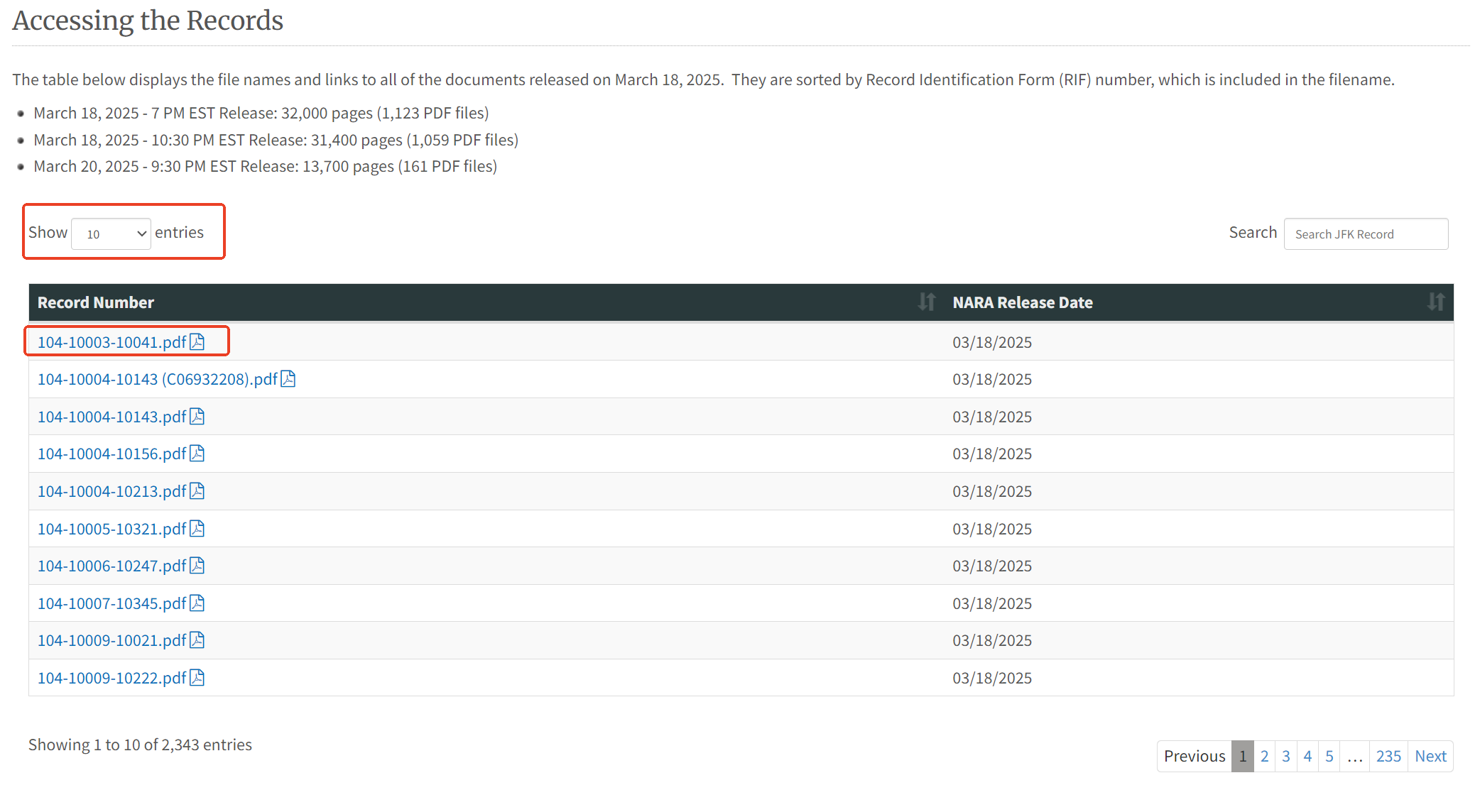
将鼠标放置在具体的记录上,右键-复制链接,即可得到相应文档的链接地址。
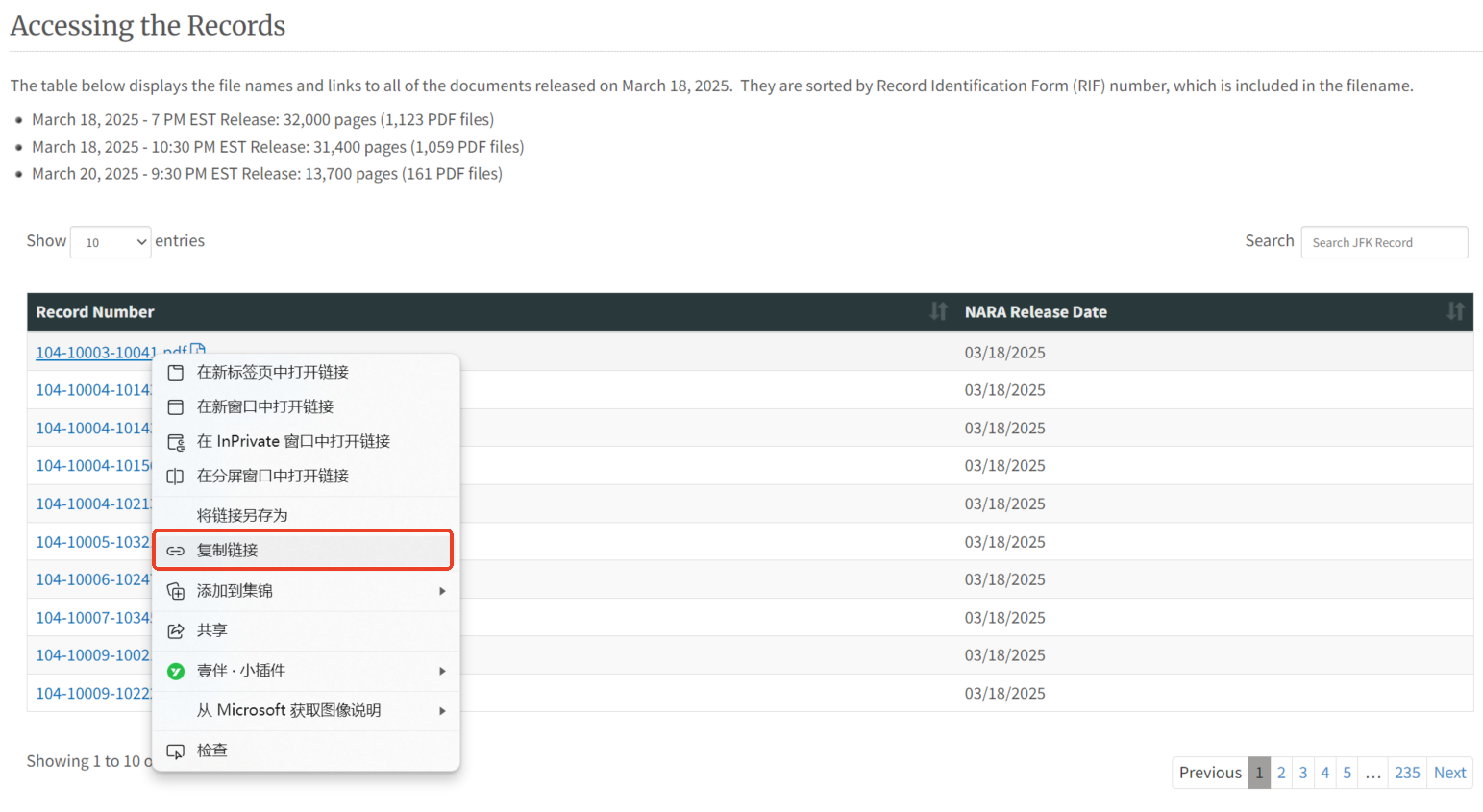
第1个文件复制出来的地址链接如下:
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041.pdf
1、最简单的抓取与下载
我们先用一段最简单的代码,尝试下载单个PDF文件,将第1份文档保存到本地文件夹。建立一个Jupyter Notebook,名为jfk_files_download.ipynb,代码如下:
import requests
# 文件的URL地址
url = 'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041.pdf'
# 保存文件的本地路径(包括文件夹和文件名)
path = 'jfk_files/104-10003-10041.pdf'
# 使用requests库发送HTTP GET请求,获取文件内容
response = requests.get(url)
# 打开本地文件,准备写入内容
# 'wb' 表示以二进制写模式打开文件(因为下载的是PDF文件,属于二进制数据)
with open(path, 'wb') as f:
# 将响应内容(即文件的二进制数据)写入到本地文件中
f.write(response.content)
同时在相同文件夹下创建一个名为jfk_files的文件夹。
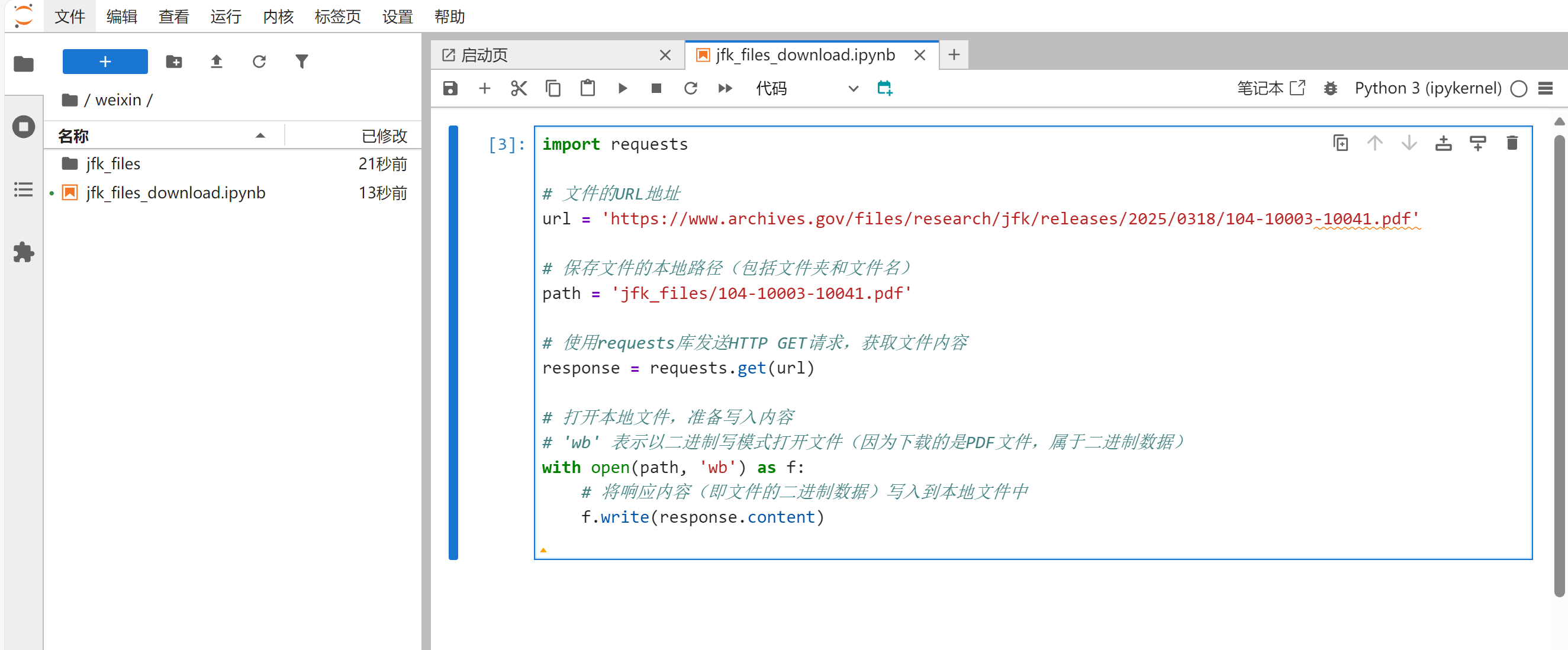
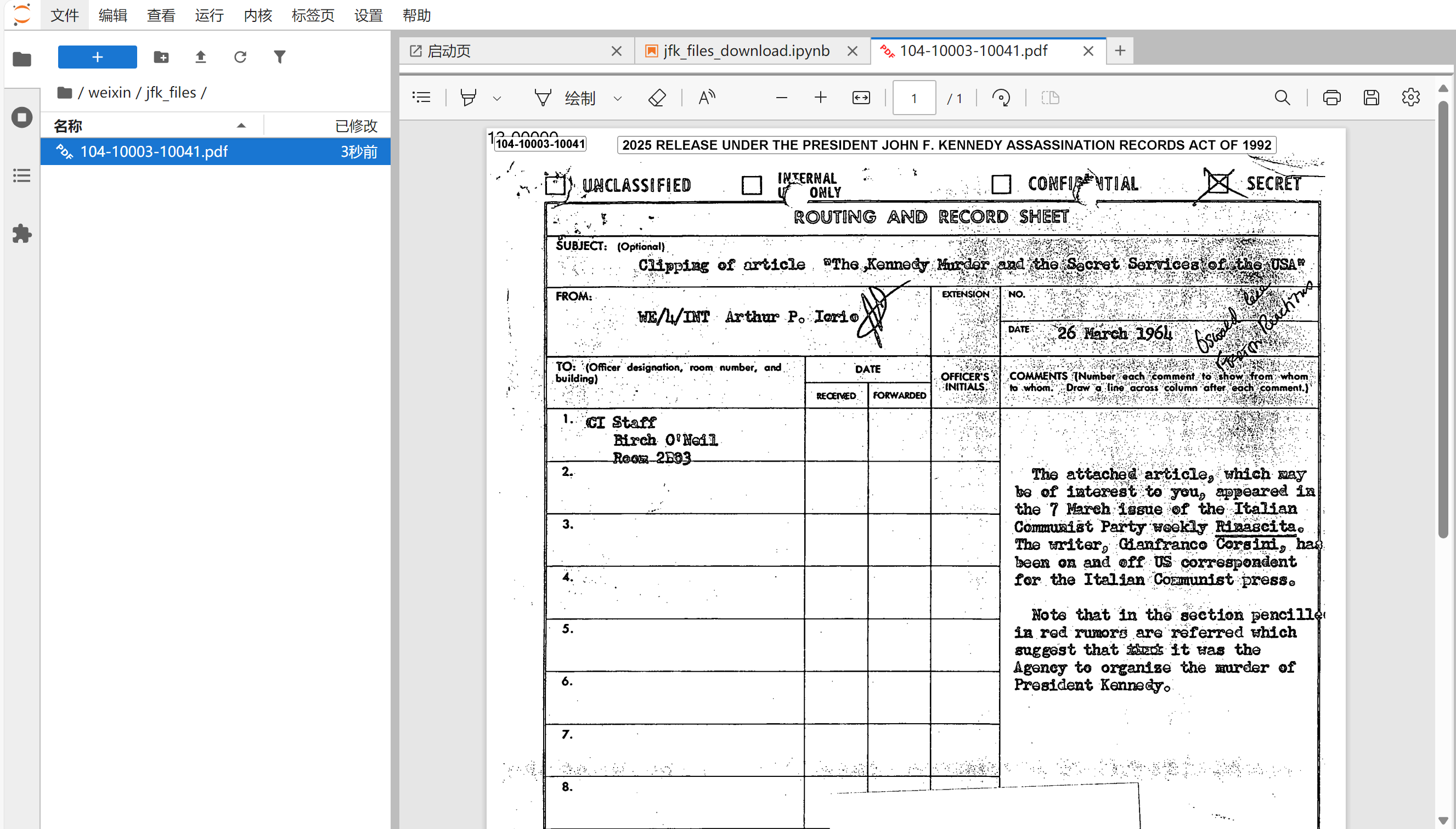
运行代码,随后打开jfk_files文件夹,会发现第1个文档104-10003-10041.pdf已经保存到了本地。可以使用JupyterLab直接打开这个PDF文档。
2、确保文件夹存在
上述代码虽然简单,但存在一个问题:如果目标文件夹`jfk_files`不存在,则会抛出错误。我们把下载的文档删掉,jfk_files文件夹也删掉,重新运行代码。
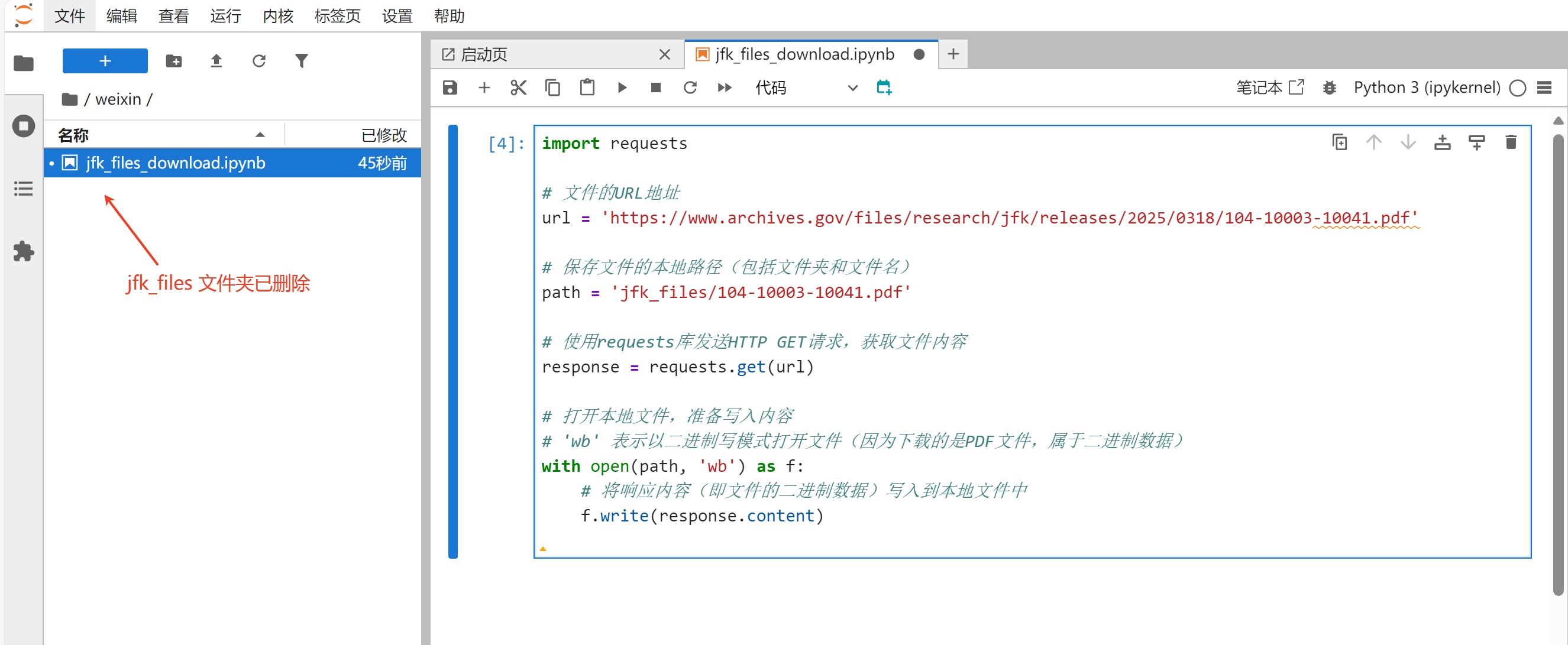
代码抛出了异常:
FileNotFoundError: [Errno 2] No such file or directory: 'jfk_files/104-10003-10041.pdf'
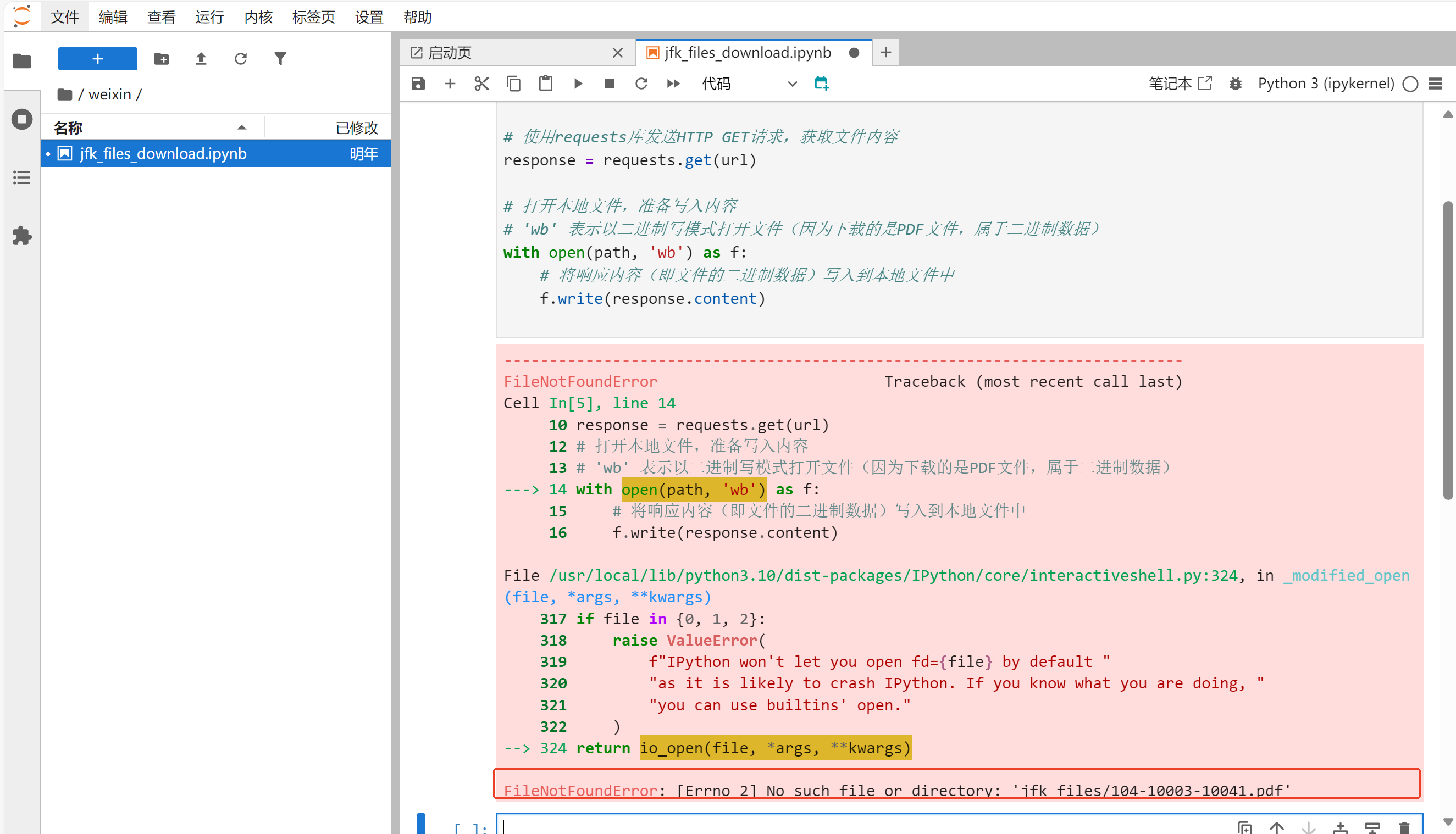
因此,我们需要确保文件夹已经存在:下载前检查并创建必要的目录结构。
第2版代码如下,新增判断文件夹是否存在;如果不存在,则执行创建命令。
import os
import requests
# 文件的URL地址
url = 'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041.pdf'
# 保存文件的本地路径(包括文件夹和文件名)
path = 'jfk_files/104-10003-10041.pdf'
# 确保文件夹存在
if not os.path.exists('jfk_files'):
os.makedirs('jfk_files')
# 使用requests库发送HTTP GET请求,获取文件内容
response = requests.get(url)
# 打开本地文件,准备写入内容
# 'wb' 表示以二进制写模式打开文件(因为下载的是PDF文件,属于二进制数据)
with open(path, 'wb') as f:
# 将响应内容(即文件的二进制数据)写入到本地文件中
f.write(response.content)
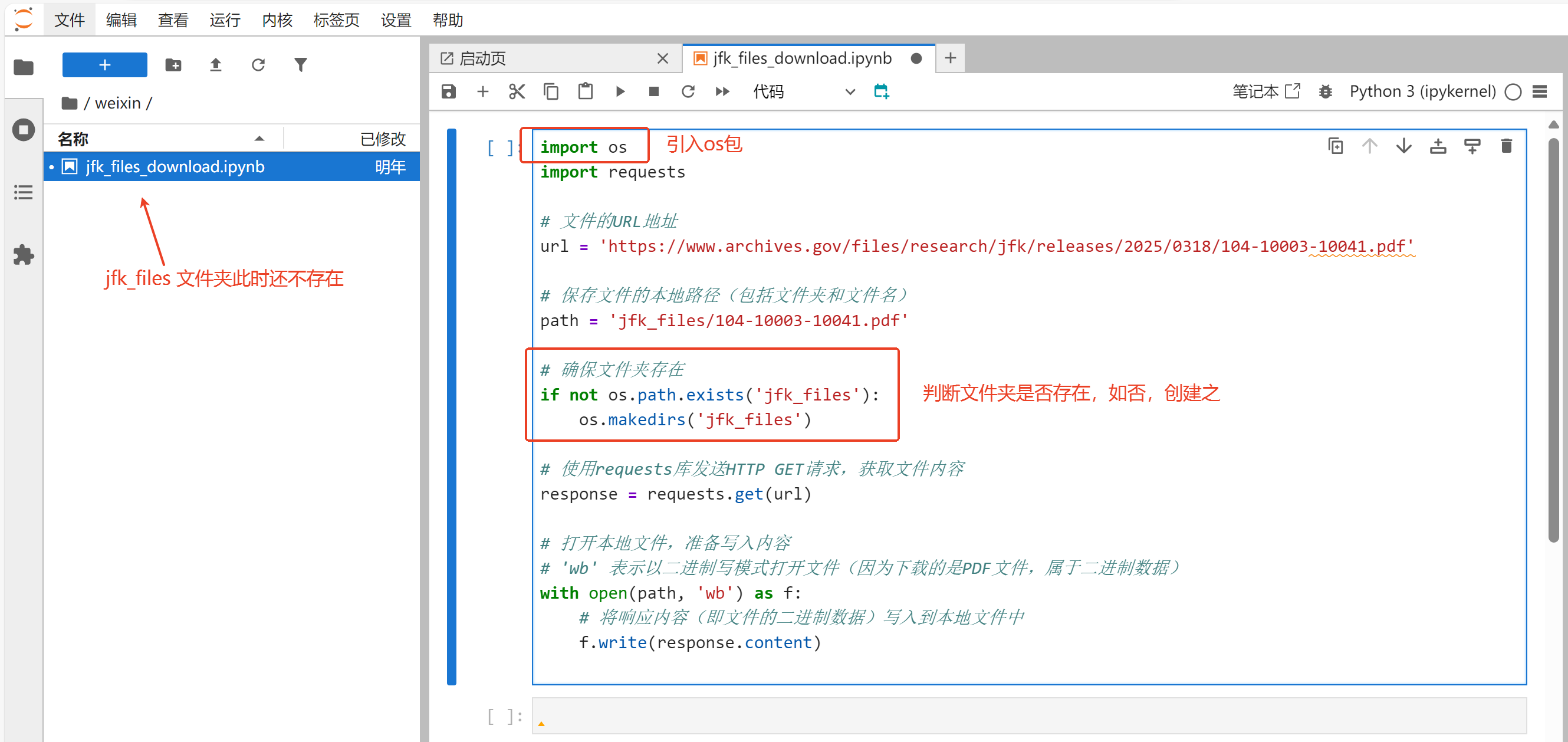
重新运行代码,程序正常结束,并自动创建了jfk_files文件夹。
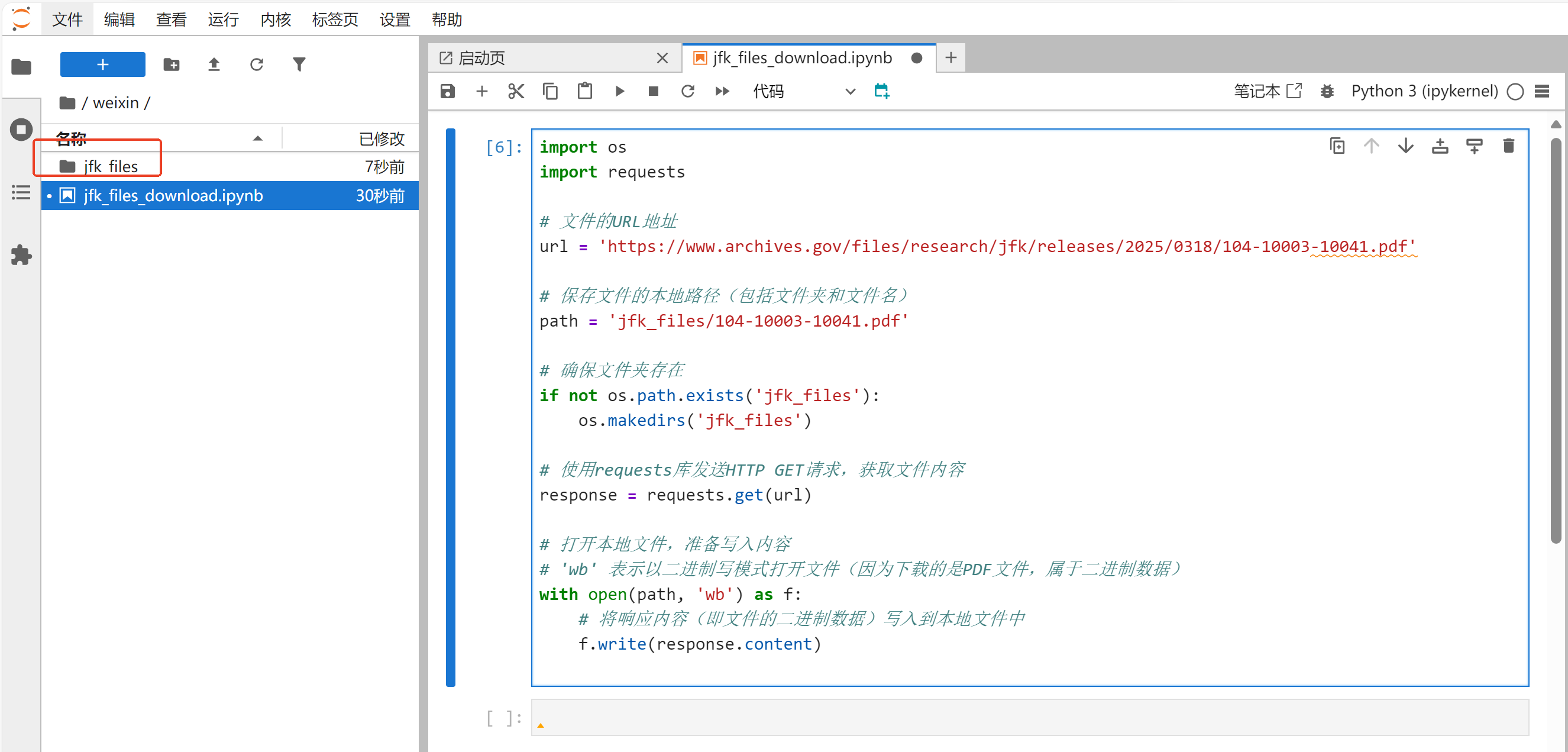
打开jfk_files文件夹,第1个文档104-10003-10041.pdf已经保存到了本地,并且可以使用JupyterLab直接打开。
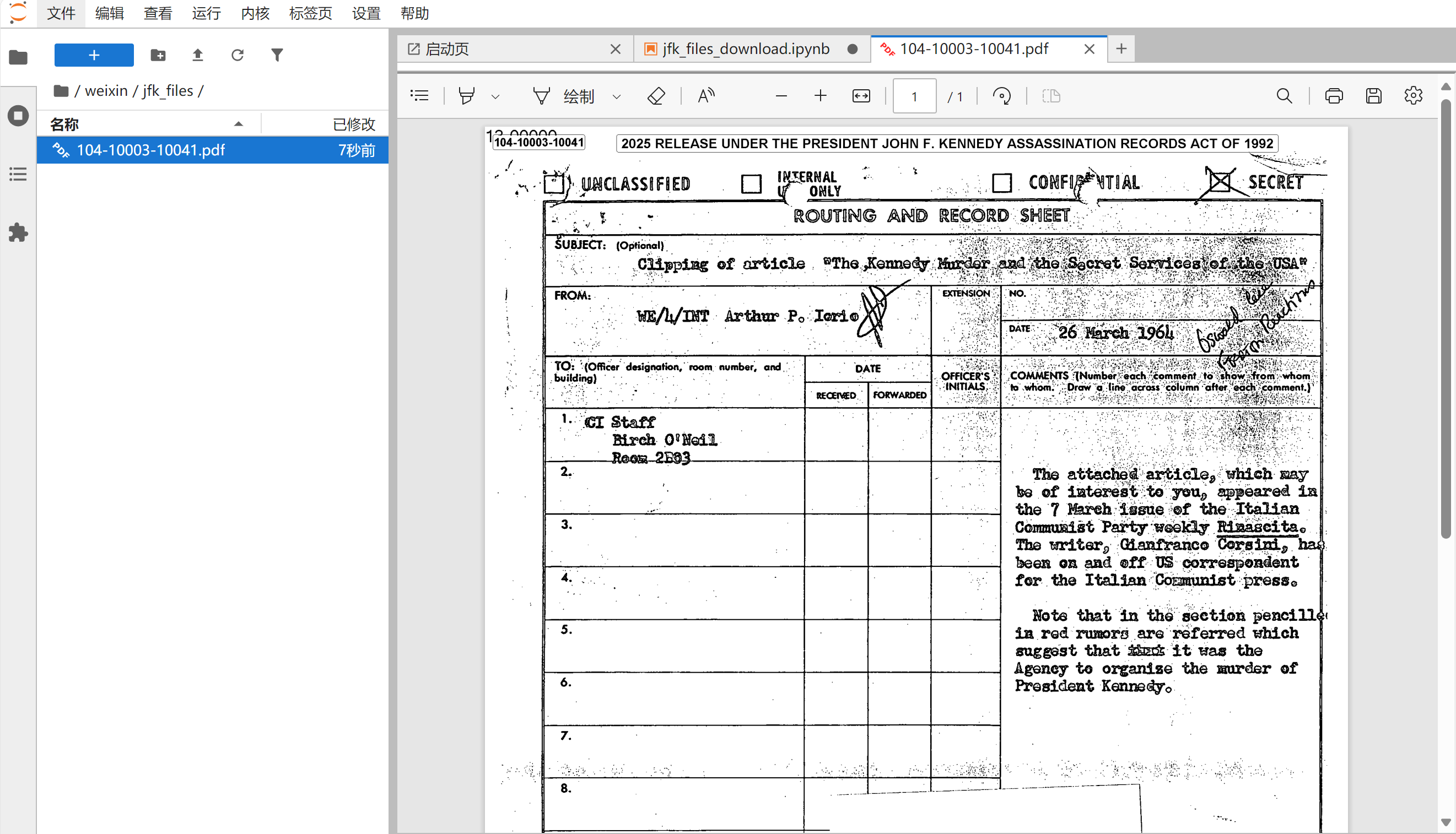
3、处理网络请求失败的情况
在网络编程中,请求可能会由于各种原因失败,如服务器不可达或资源不存在等。因此,加入异常处理机制是十分必要的。我们将requests.get(url)的操作,放在一个try-except代码块中,以便捕获异常requests.exceptions.RequestException。
使用response.raise_for_status()用于检查请求是否成功。
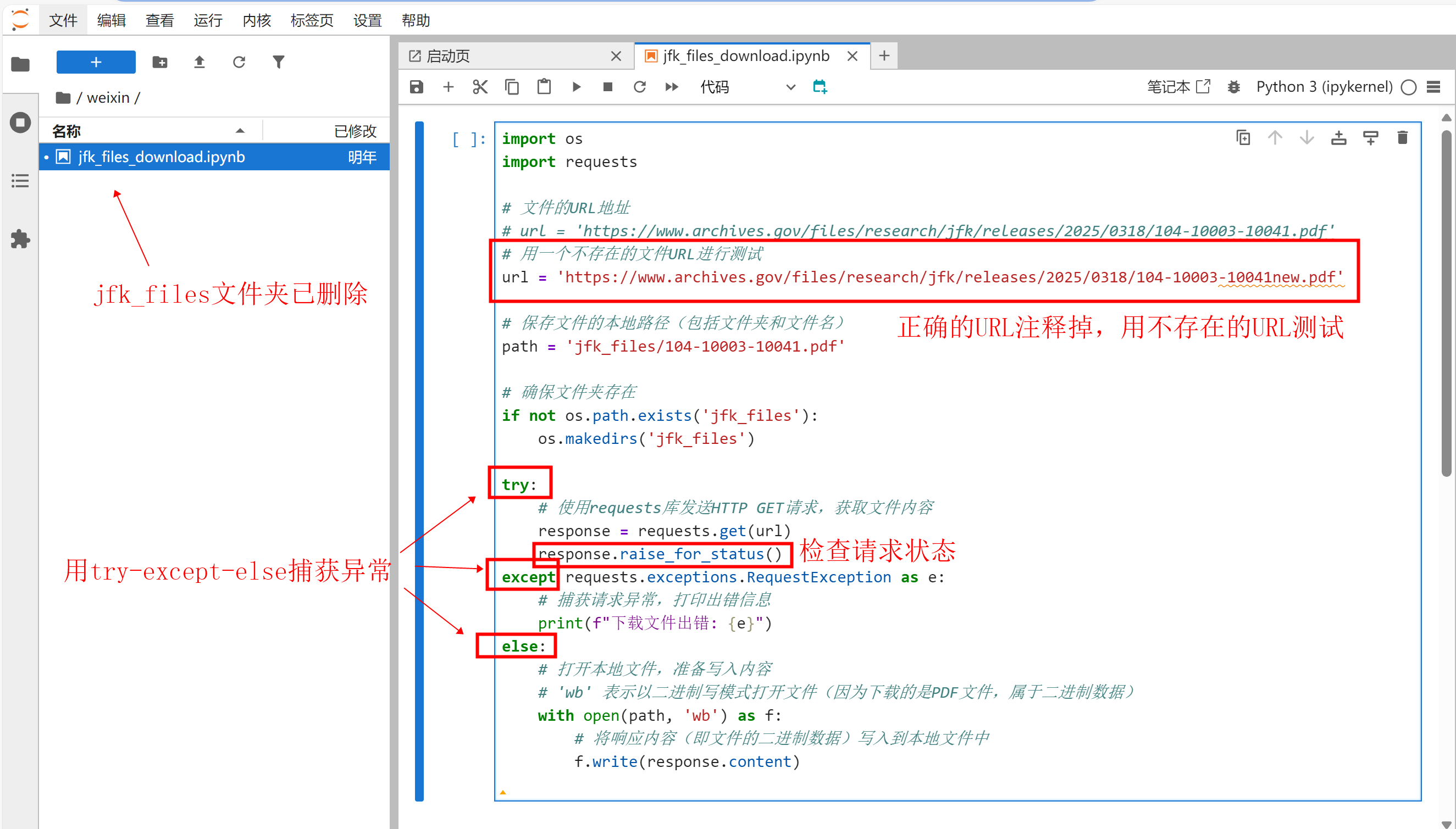
将104-10003-10041.pdf文件、jfk_files文件夹删除,代码修改如下:
import os
import requests
# 文件的URL地址
# url = 'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041.pdf'
# 用一个不存在的文件URL进行测试
url = 'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041new.pdf'
# 保存文件的本地路径(包括文件夹和文件名)
path = 'jfk_files/104-10003-10041.pdf'
# 确保文件夹存在
if not os.path.exists('jfk_files'):
os.makedirs('jfk_files')
try:
# 使用requests库发送HTTP GET请求,获取文件内容
response = requests.get(url)
response.raise_for_status()
except requests.exceptions.RequestException as e:
# 捕获请求异常,打印出错信息
print(f"下载文件出错: {e}")
else:
# 打开本地文件,准备写入内容
# 'wb' 表示以二进制写模式打开文件(因为下载的是PDF文件,属于二进制数据)
with open(path, 'wb') as f:
# 将响应内容(即文件的二进制数据)写入到本地文件中
f.write(response.content)
注意,这里我们先试用一个不存在的URL来测试异常捕获情况。
运行代码,提示:
下载文件出错: 404 Client Error: Not Found for url: https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041new.pdf
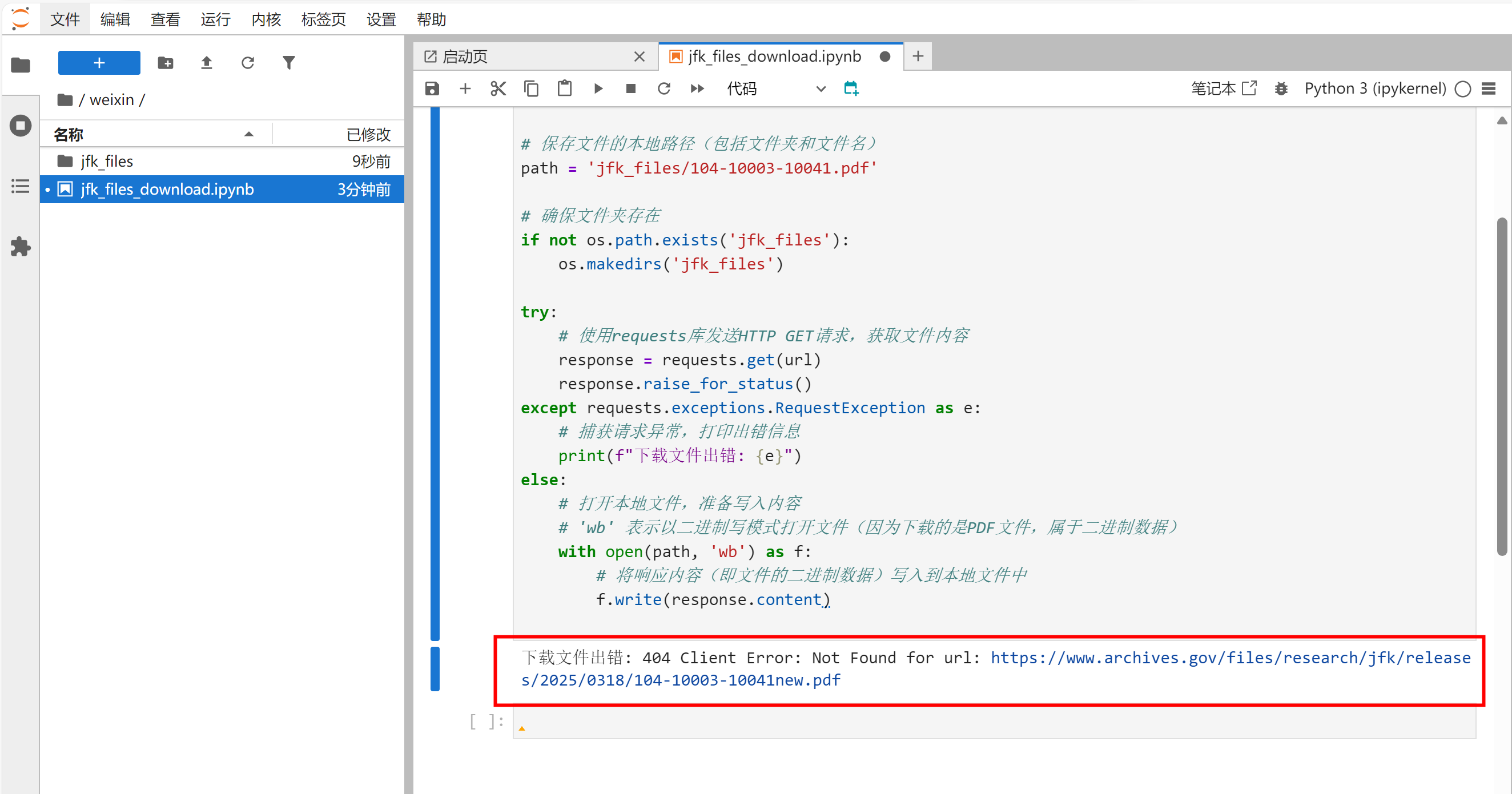
而jfk_files文件夹里也为空,意味着没有下载到具体的文件。
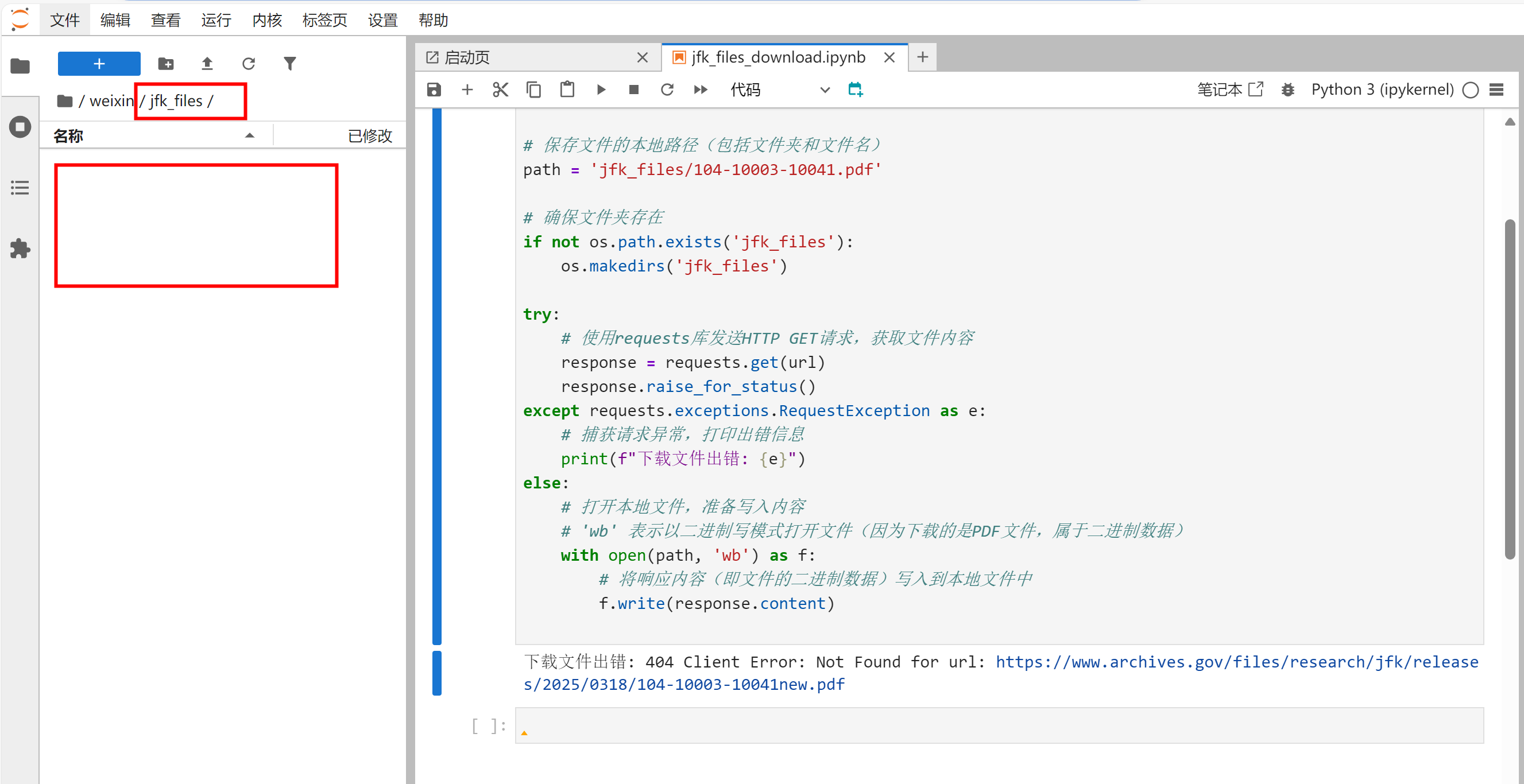
换成正确的URL地址,重新运行代码,没有提示请求错误,且可以正常下载文件。
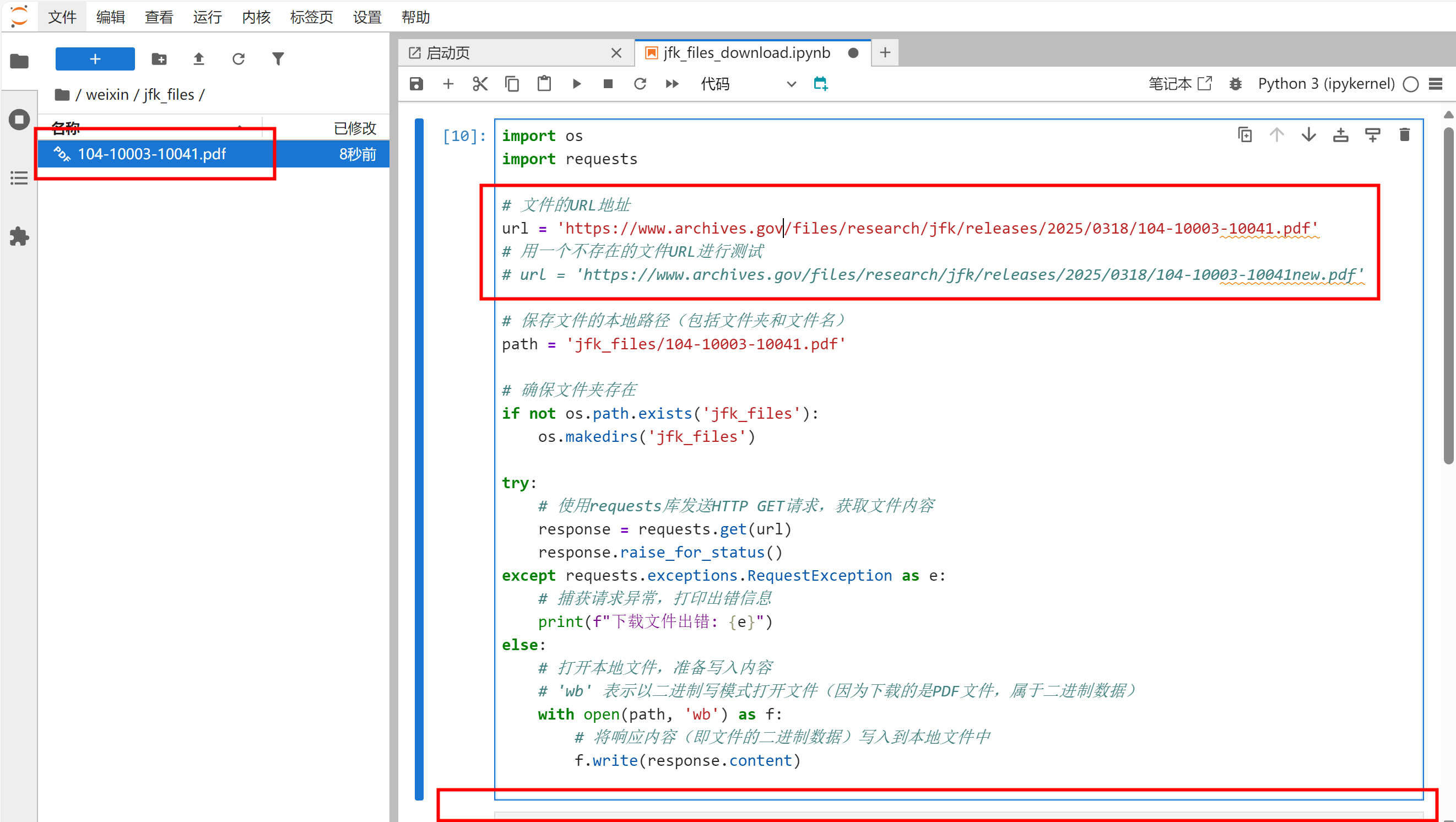
文件正常打开。
4、封装下载函数
由于后续我们要批量下载JFK文件,因此这一步我们先将上述单文件下载的代码,封装成一个函数`download_file`,其功能为:根据输入的URL,以及用于保存文件的本地文件夹名,构造保存文件的路径。并且,保存本地的文件名,与网页上的文件名相同。
函数代码如下:
def download_file(url, folder):
# 从URL中提取文件名
filename = url.split('/')[-1]
# 构造保存文件的路径
path = os.path.join(folder, filename)
# 确保文件夹存在
if not os.path.exists(folder):
os.makedirs(folder)
try:
# 使用requests库发送HTTP GET请求,获取文件内容
response = requests.get(url)
response.raise_for_status()
# 打开本地文件,准备写入内容
# 'wb' 表示以二进制写模式打开文件(因为下载的是PDF文件,属于二进制数据)
with open(path, 'wb') as f:
# 将响应内容(即文件的二进制数据)写入到本地文件中
f.write(response.content)
print(f"{filename} 文件下载成功。")
except Exception as e:
# 捕获请求异常,打印出错信息
print(f"下载文件出错: {e}")
新的完整代码如下:
import os
import requests
def download_file(url, folder):
# 从URL中提取文件名
filename = url.split('/')[-1]
# 构造保存文件的路径
path = os.path.join(folder, filename)
# 确保文件夹存在
if not os.path.exists(folder):
os.makedirs(folder)
try:
# 使用requests库发送HTTP GET请求,获取文件内容
response = requests.get(url)
response.raise_for_status()
# 打开本地文件,准备写入内容
# 'wb' 表示以二进制写模式打开文件(因为下载的是PDF文件,属于二进制数据)
with open(path, 'wb') as f:
# 将响应内容(即文件的二进制数据)写入到本地文件中
f.write(response.content)
print(f"{filename} 文件下载成功。")
except Exception as e:
# 捕获请求异常,打印出错信息
print(f"下载文件出错: {e}")
# 文件的URL地址
url = 'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041.pdf'
# 保存文件的本地文件夹
folder = 'jfk_files'
# 调用函数,下载文件
download_file(url, folder)
运行代码,如果url正确的话,运行结束输出:
104-10003-10041.pdf 文件下载成功。
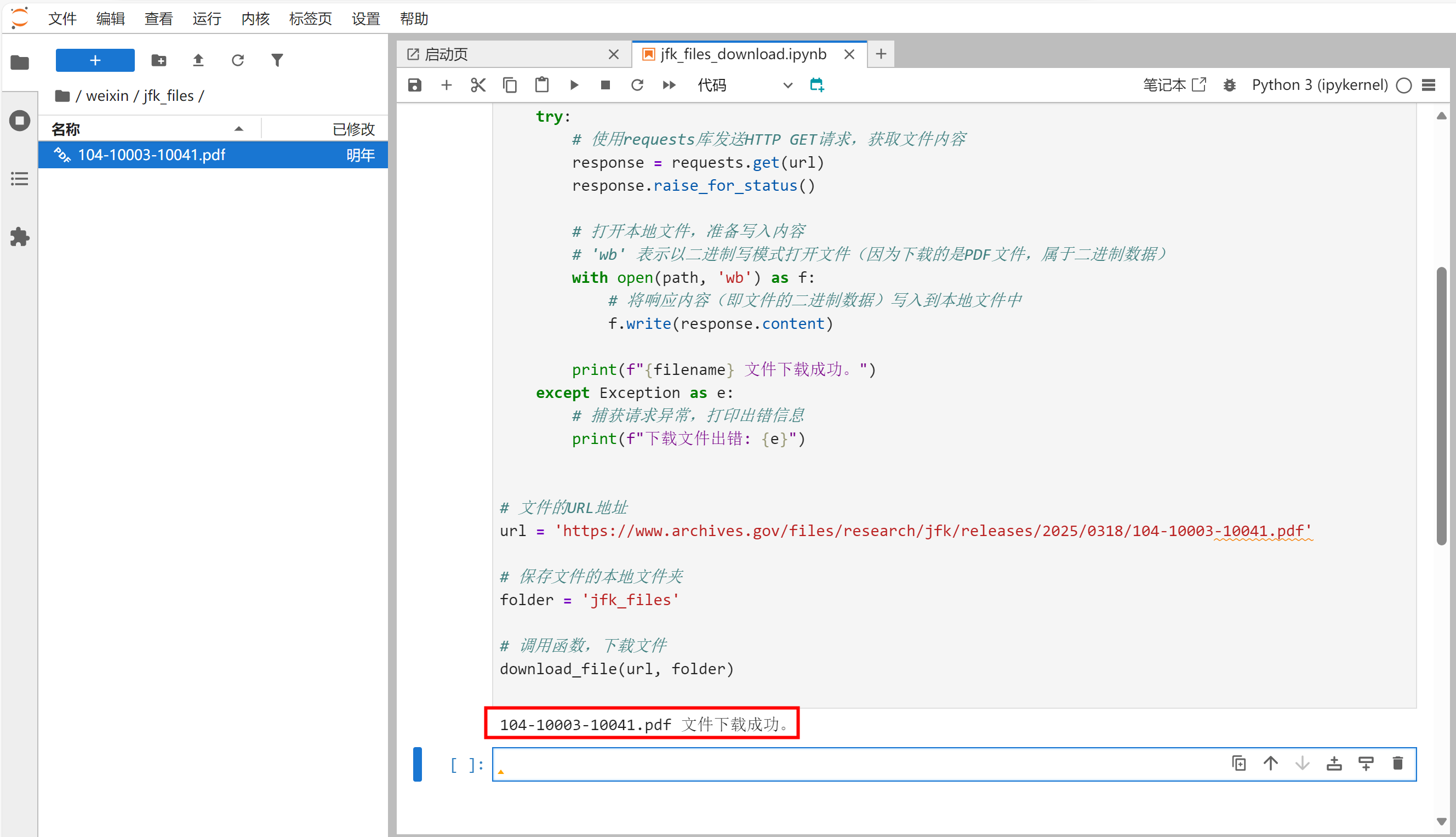
5、批量下载多个文件
现在,我们要来批量下载多个文件。先把网页表格第1页10条记录的地址都记录下来:
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041.pdf
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10143%20(C06932208).pdf
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10143.pdf
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10156.pdf
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10213.pdf
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10005-10321.pdf
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10006-10247.pdf
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10007-10345.pdf
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10009-10021.pdf
https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10009-10222.pdf
这些复制下来的URL,我们将其存放在一个list类型的变量urls中:
urls = [
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10143%20(C06932208).pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10143.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10156.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10213.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10005-10321.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10006-10247.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10007-10345.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10009-10021.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10009-10222.pdf'
]
遍历urls,分别执行download_file函数:
for url in urls:
download_file(url, folder)
完整代码:
import os
import requests
def download_file(url, folder):
# 从URL中提取文件名
filename = url.split('/')[-1]
# 构造保存文件的路径
path = os.path.join(folder, filename)
# 确保文件夹存在
if not os.path.exists(folder):
os.makedirs(folder)
try:
# 使用requests库发送HTTP GET请求,获取文件内容
response = requests.get(url)
response.raise_for_status()
# 打开本地文件,准备写入内容
# 'wb' 表示以二进制写模式打开文件(因为下载的是PDF文件,属于二进制数据)
with open(path, 'wb') as f:
# 将响应内容(即文件的二进制数据)写入到本地文件中
f.write(response.content)
print(f"{filename} 文件下载成功。")
except Exception as e:
# 捕获请求异常,打印出错信息
print(f"下载文件出错: {e}")
# 文件的URL地址列表
urls = [
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10003-10041.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10143%20(C06932208).pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10143.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10156.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10004-10213.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10005-10321.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10006-10247.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10007-10345.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10009-10021.pdf',
'https://www.archives.gov/files/research/jfk/releases/2025/0318/104-10009-10222.pdf'
]
# 保存文件的本地文件夹
folder = 'jfk_files'
# 遍历urls,调用函数,下载文件
for url in urls:
download_file(url, folder)
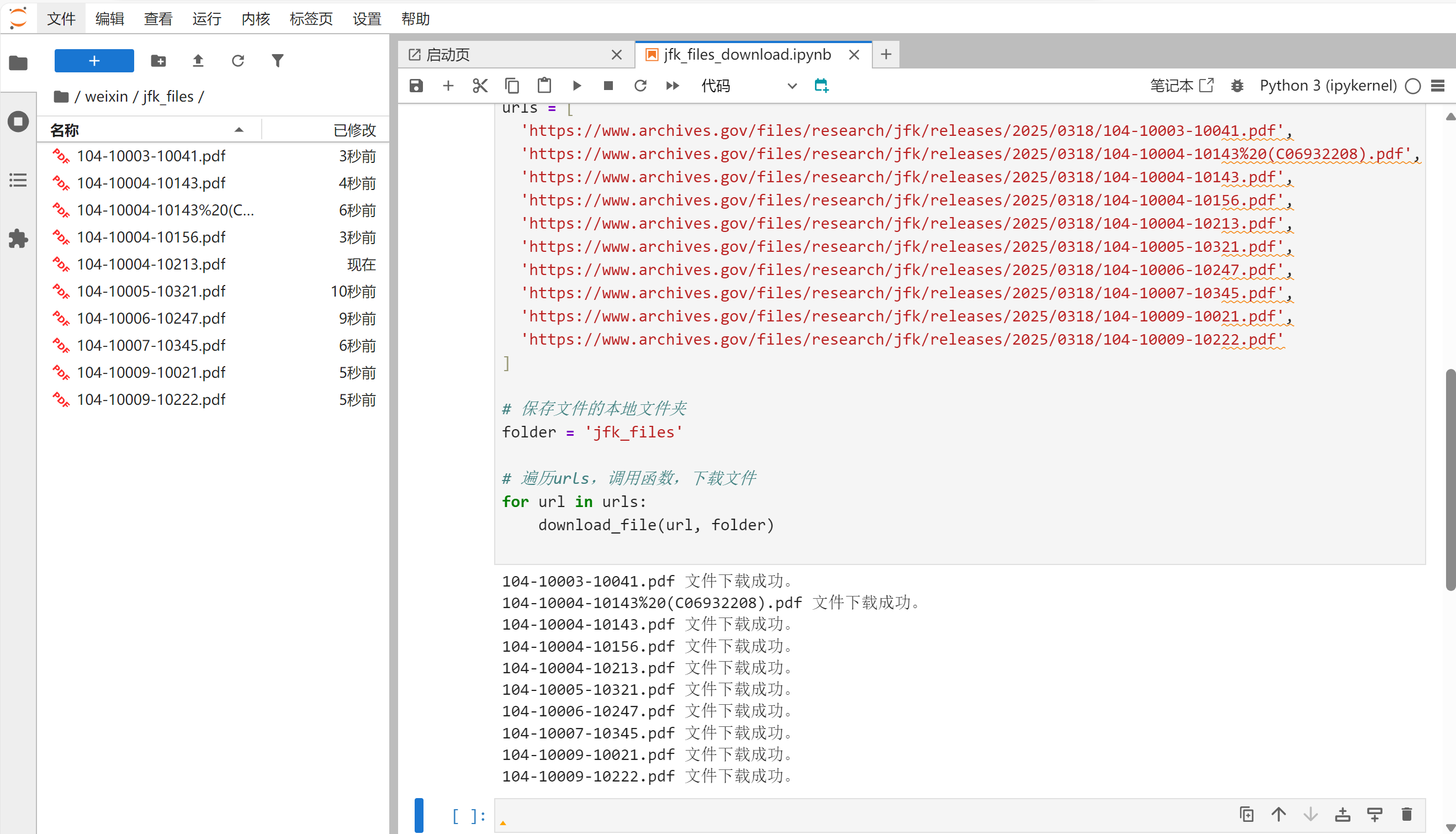
运行程序,可以看到10个文件成功下载。
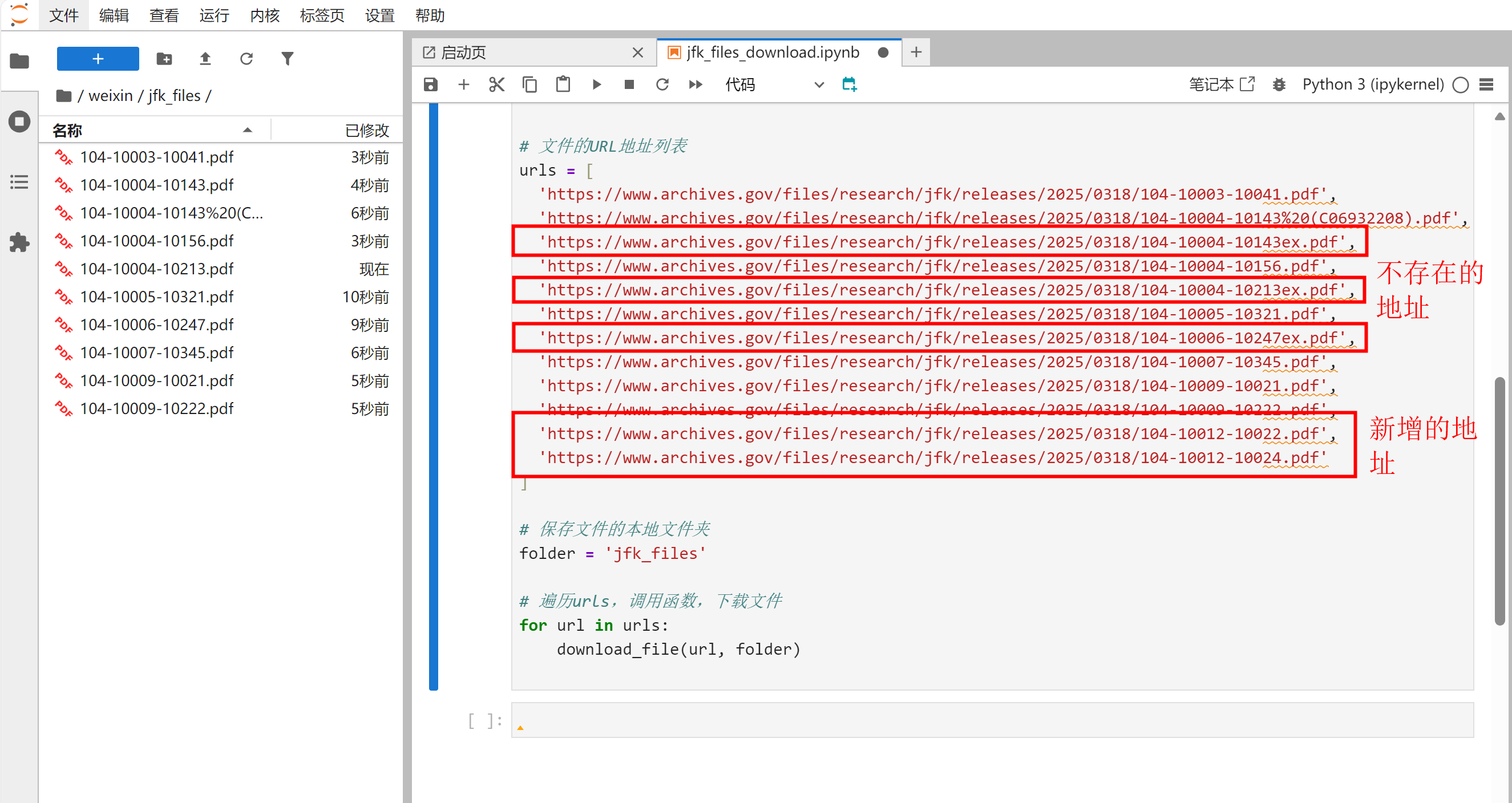
为了验证程序的健壮性,我们执行以下操作后重新运行试试:
- 已下载的文件不删除;
- 修改
urls列表中某几个URL地址,将其改为不存在的地址; - 从网页表格第2页中获取链接地址,新增几条URL记录。
运行程序,可以看到,不存在的文件会被跳过,新增的文件也正常下载。
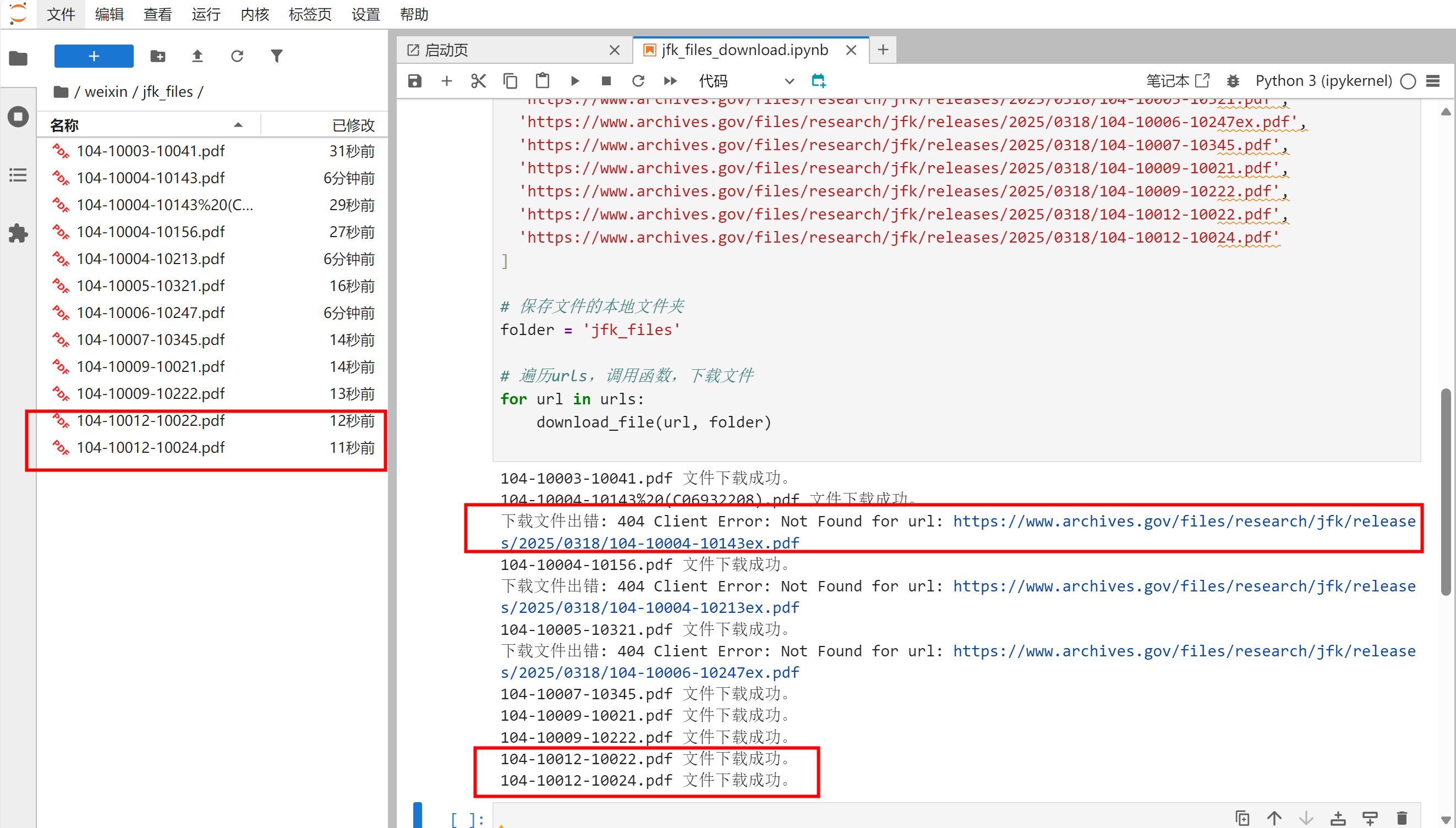
但是这里有个小问题:已经下载过的文件,会重复下载。
为了避免这种资源浪费,我们在download_file函数中增加一个判断:如果文件已经下载过了,那么就跳过。
def download_file(url, folder):
# 从URL中提取文件名
filename = url.split('/')[-1]
# 构造保存文件的路径
path = os.path.join(folder, filename)
# 如果文件已存在,不再重复下载
if os.path.exists(path):
print(f"{filename} 文件已存在。")
return
# 确保文件夹存在
if not os.path.exists(folder):
os.makedirs(folder)
try:
# 使用requests库发送HTTP GET请求,获取文件内容
response = requests.get(url)
response.raise_for_status()
# 打开本地文件,准备写入内容
# 'wb' 表示以二进制写模式打开文件(因为下载的是PDF文件,属于二进制数据)
with open(path, 'wb') as f:
# 将响应内容(即文件的二进制数据)写入到本地文件中
f.write(response.content)
print(f"{filename} 文件下载成功。")
except Exception as e:
# 捕获请求异常,打印出错信息
print(f"下载文件出错: {e}")
6、获取所有待下载文件的URL
在第5步中,我们通过一个个复制的笨办法,获取到了10个文件的URL,并将它们放置在一个`list`变量中。然而这一批文件一共有2300多个PDF,我们不可能一个个复制。因此,得想办法将所有文件的URL获取到,并通过某种简洁的方式将其放置到`list`变量`urls`中。在准备工作中,我们提到,表格支持显示所有记录,这为我们后续的全量下载提供了很大便利。
(1)查看表格数据标签
我们回到网页表格,选择“Show All entries”,如图所示。这样所有的记录将会一个很长的表格的形式完整展示在页面上。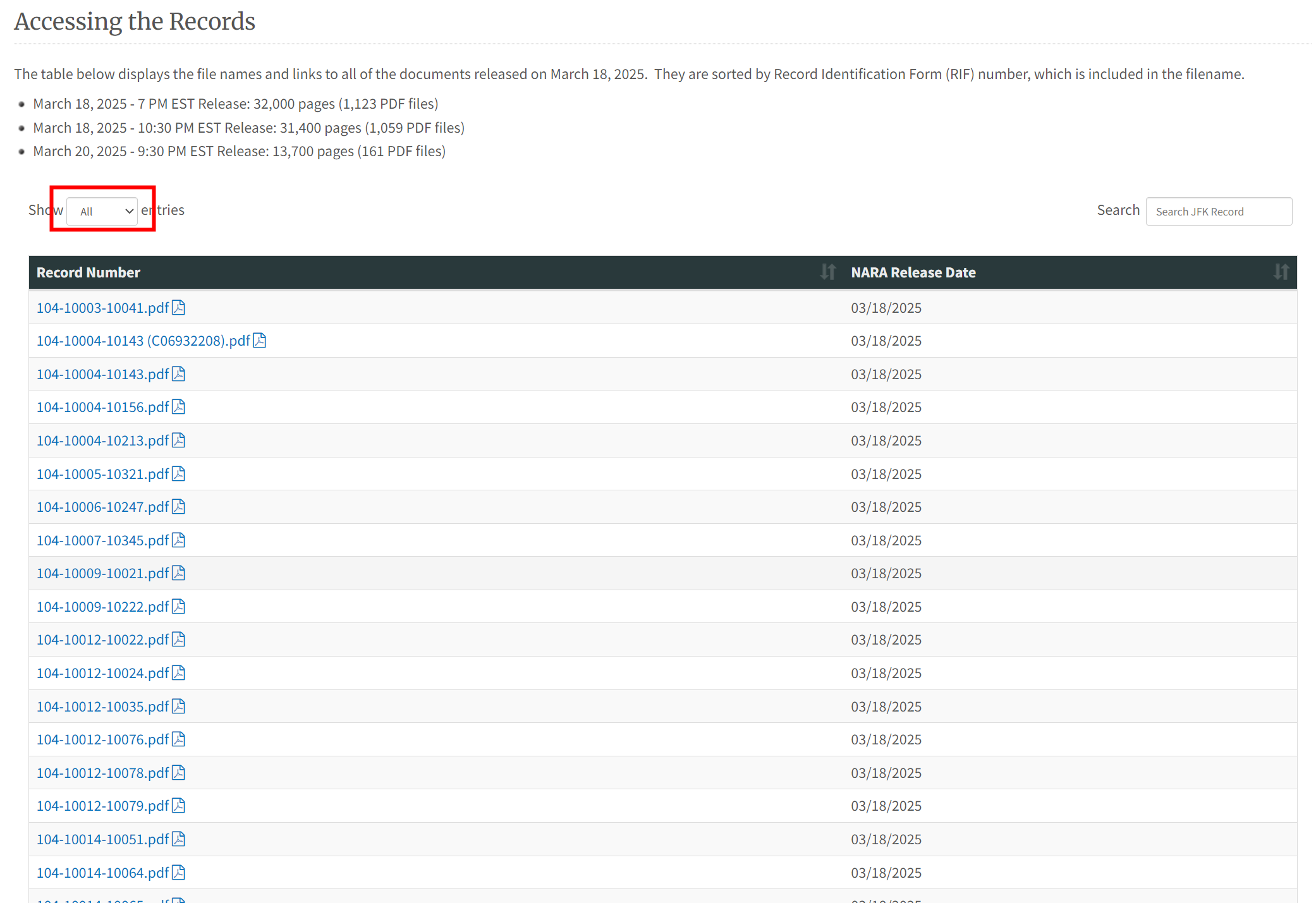
将鼠标放置在表格上,右键-检查,打开开发者调试工具,并直接定位到表格元素所在位置。
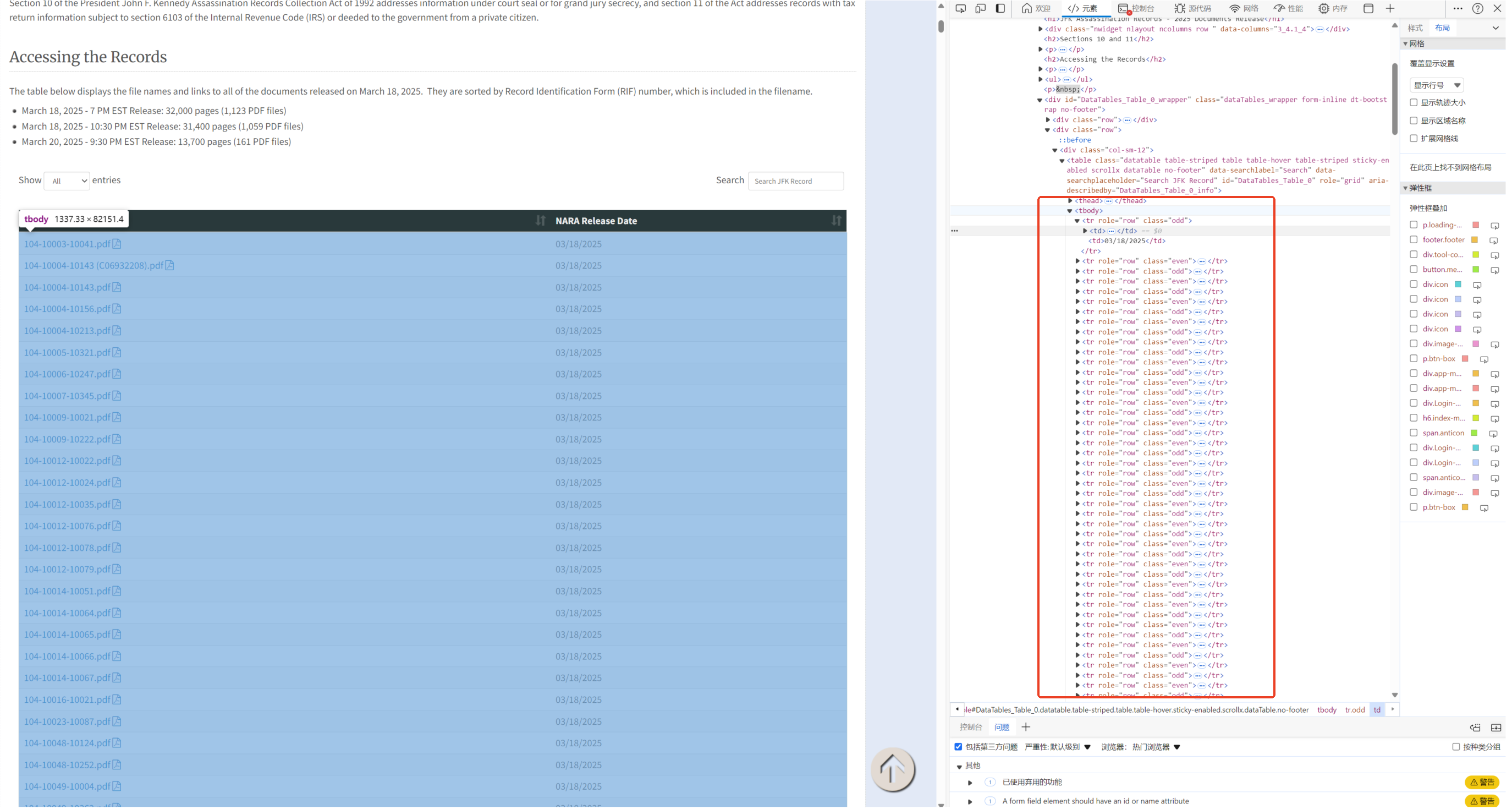
在开发者调试工具中,可以看到表格的HTML结构。表格的主要部分位于<table>的<tbody>标签内。每一行数据由<tr>标签表示,其中包含多个<td>标签来展示具体的列数据。第一个<font style="color:rgb(44, 44, 54);"><td></font>标签包含一个链接,该链接指向具体的PDF文件。
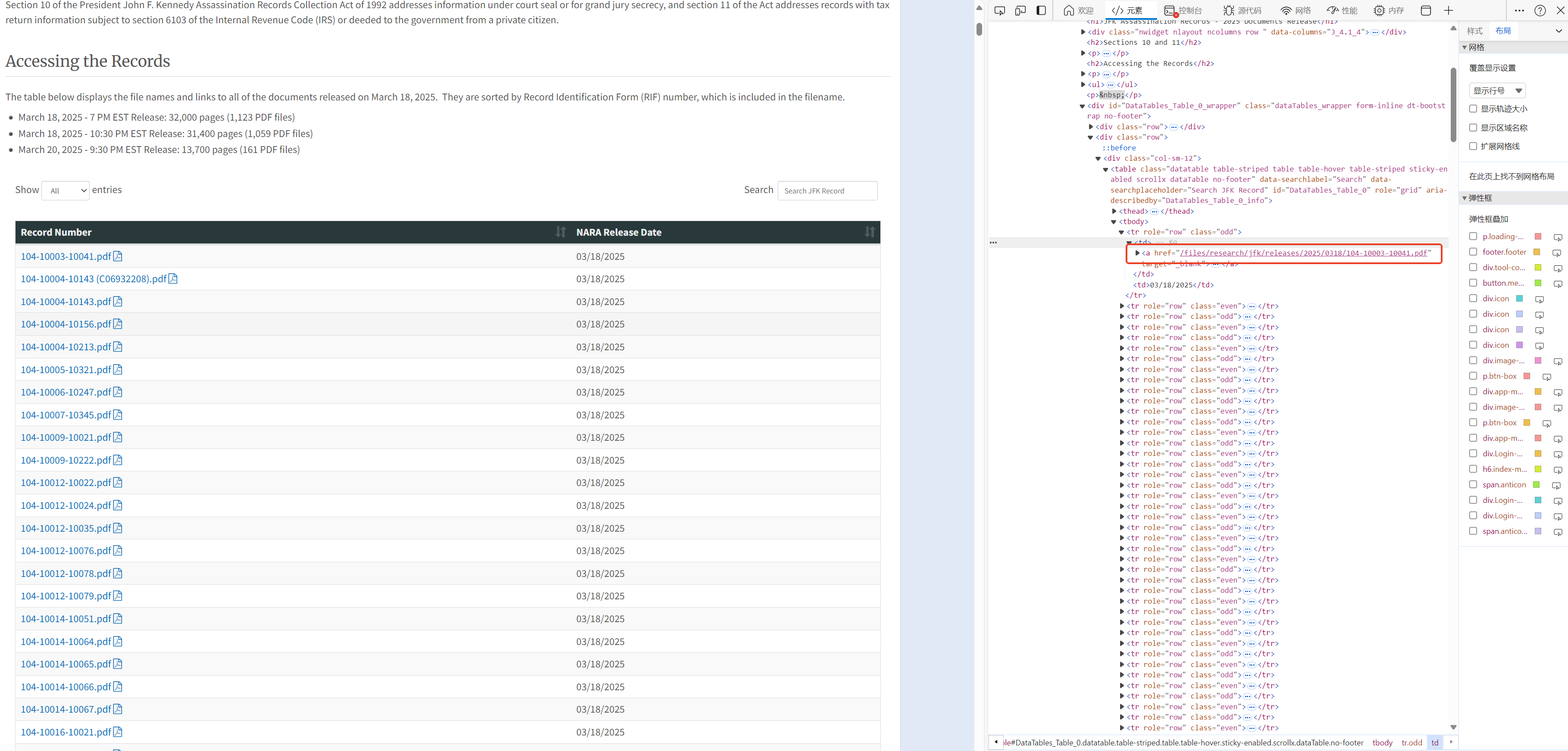
(2)提取资源路径
结合前面的工作,我们可以得知,文档URL由两部分组成:- 主域名:https://www.archives.gov
- 资源路径:类似“/files/research/jfk/releases/2025/0318/+文件名”,可通过
<font style="color:rgb(44, 44, 54);"><td></font>标签获取。
所以,现在我们的目的就是:将<tbody标签所包含的数据块中,每个<tr>标签下的记录,第一个<font style="color:rgb(44, 44, 54);"><td></font>标签所包含的链接,提取出来,与主域名https://www.archives.gov合并之后,放置在一个<font style="color:rgb(44, 44, 54);">list</font>变量<font style="color:rgb(44, 44, 54);">urls</font>中。
首先,要建立正则表达式,将类似href="/files/research/jfk/releases/2025/0318/104-10003-10041.pdf"这样的字符串匹配出来:
pattern = r'href="(/files/research/jfk/releases/2025/0318/.*?\.pdf)"'
其次,把<tbody标签的内容复制出来。我们先复制几条记录,以供测试:
<tr role="row" class="odd">
<td><a href="/files/research/jfk/releases/2025/0318/104-10003-10041.pdf" target="_blank">104-10003-10041.pdf</a></td>
<td>03/18/2025</td>
</tr><tr role="row" class="even">
<td><a href="/files/research/jfk/releases/2025/0318/104-10004-10143 (C06932208).pdf" target="_blank">104-10004-10143 (C06932208).pdf</a></td>
<td>03/18/2025</td>
</tr><tr role="row" class="odd">
<td><a href="/files/research/jfk/releases/2025/0318/104-10004-10143.pdf" target="_blank">104-10004-10143.pdf</a></td>
<td>03/18/2025</td>
</tr><tr role="row" class="even">
<td><a href="/files/research/jfk/releases/2025/0318/104-10004-10156.pdf" target="_blank">104-10004-10156.pdf</a></td>
<td>03/18/2025</td>
</tr>
测试代码如下:
import re
pattern = r'href="(/files/research/jfk/releases/2025/0318/.*?\.pdf)"'
tbody = '''
<tr role="row" class="odd">
<td><a href="/files/research/jfk/releases/2025/0318/104-10003-10041.pdf" target="_blank">104-10003-10041.pdf</a></td>
<td>03/18/2025</td>
</tr><tr role="row" class="even">
<td><a href="/files/research/jfk/releases/2025/0318/104-10004-10143 (C06932208).pdf" target="_blank">104-10004-10143 (C06932208).pdf</a></td>
<td>03/18/2025</td>
</tr><tr role="row" class="odd">
<td><a href="/files/research/jfk/releases/2025/0318/104-10004-10143.pdf" target="_blank">104-10004-10143.pdf</a></td>
<td>03/18/2025</td>
</tr><tr role="row" class="even">
<td><a href="/files/research/jfk/releases/2025/0318/104-10004-10156.pdf" target="_blank">104-10004-10156.pdf</a></td>
<td>03/18/2025</td>
</tr>
'''
res_paths = re.findall(pattern, tbody)
print(type(res_paths))
print(res_paths)
测试结果:
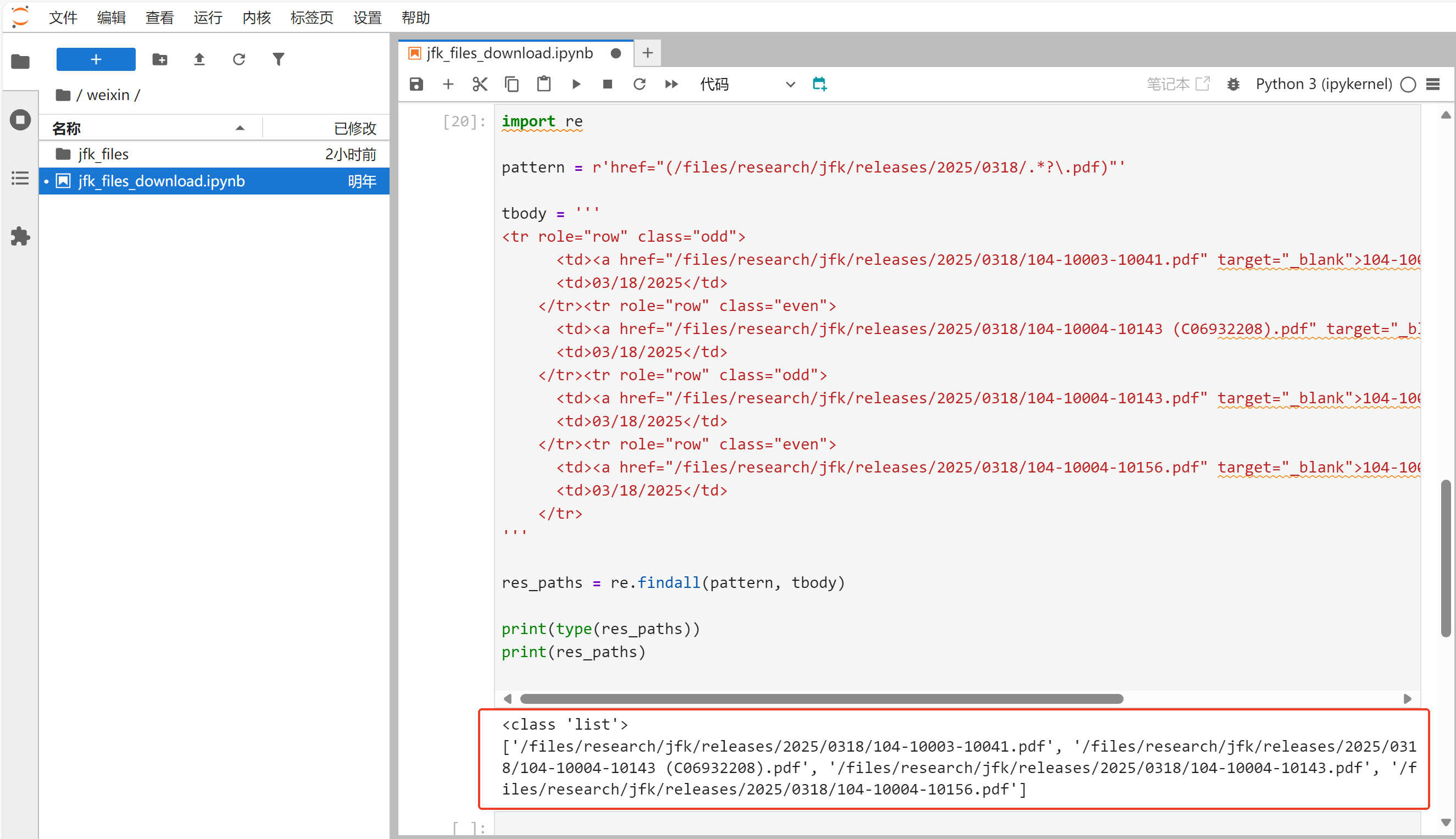
可以看到,测试数据中的资源路径,已成功提取到,并放入res_paths列表中。
(3)批量提取资源路径
现在,我们把``的内容复制到一个文本文件`jfk_files_tbody.txt`中,通过文件读取的形式将其读入`tbody`变量中。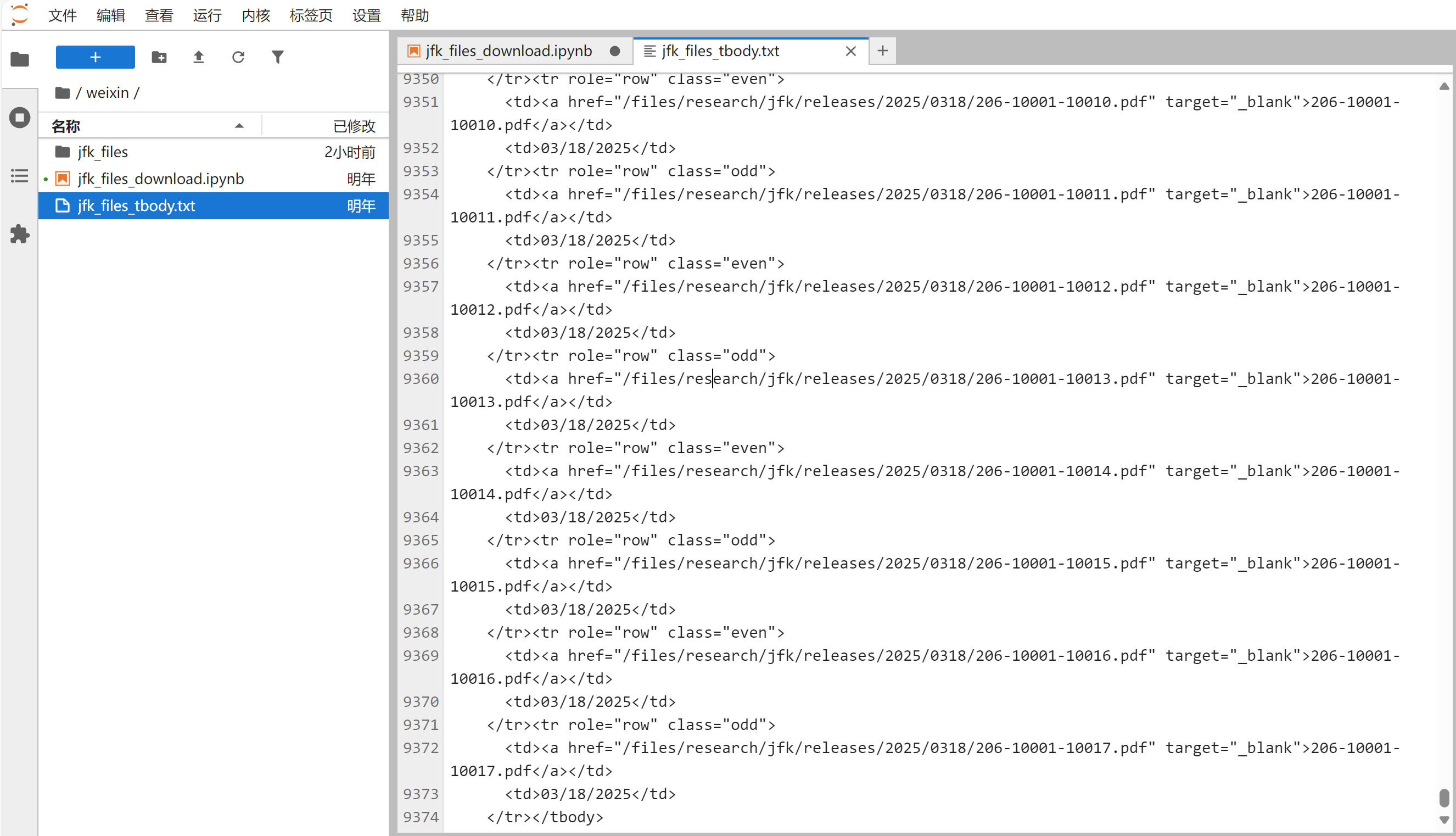
新的代码如下:
import re
pattern = r'href="(/files/research/jfk/releases/2025/0318/.*?\.pdf)"'
with open('jfk_files_tbody.txt', 'r') as f:
tbody = f.read()
res_paths = re.findall(pattern, tbody)
print(type(res_paths))
print(len(res_paths))
print(res_paths[0:4])
运行代码,结果如下:
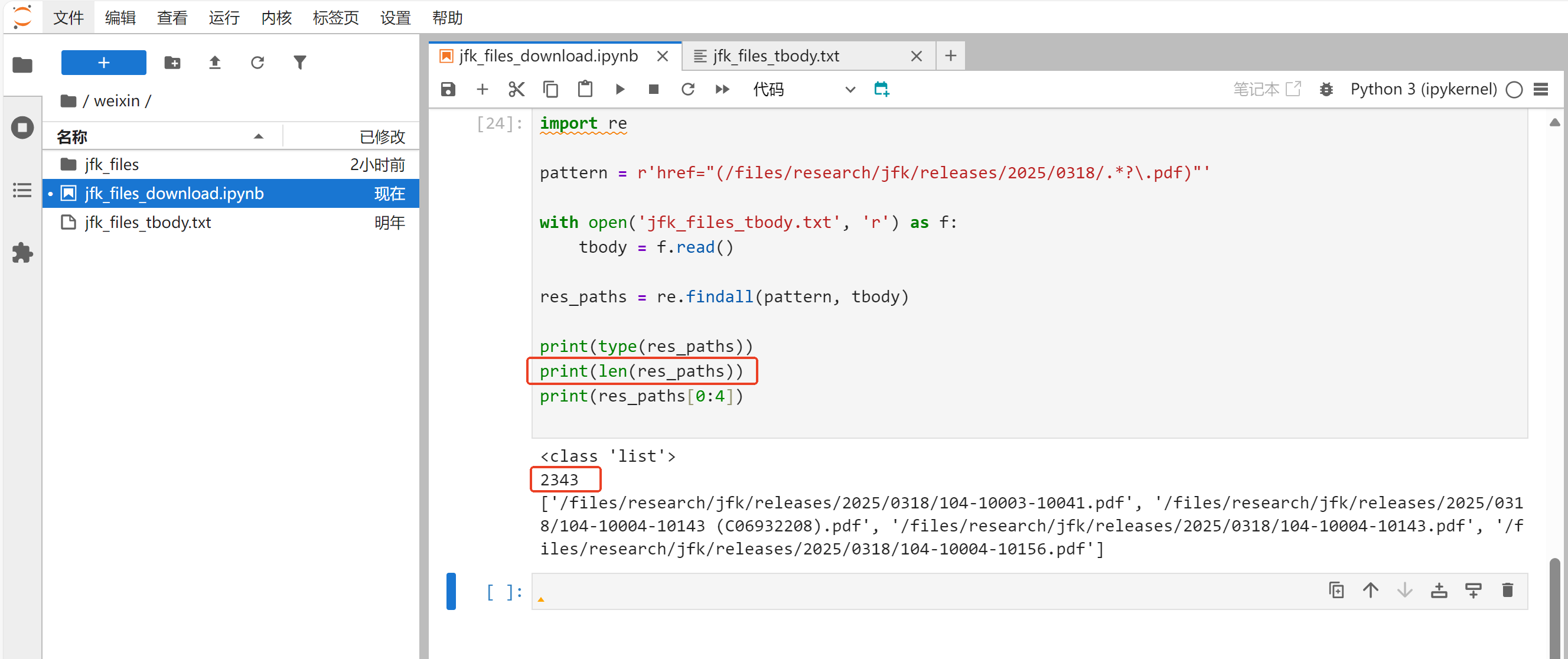
可以看到,全部2343个链接均已取到。
(4)构造完整文档链接
下一步,将`res_paths`中的资源路径,和主域名串联起来,构造完整的链接列表`urls`。代码如下:import re
main_url = 'https://www.archives.gov'
pattern = r'href="(/files/research/jfk/releases/2025/0318/.*?\.pdf)"'
with open('jfk_files_tbody.txt', 'r') as f:
tbody = f.read()
res_paths = re.findall(pattern, tbody)
urls = [main_url+path for path in res_paths]
print(type(urls))
print(len(urls))
print(urls[0:4])
测试结果:
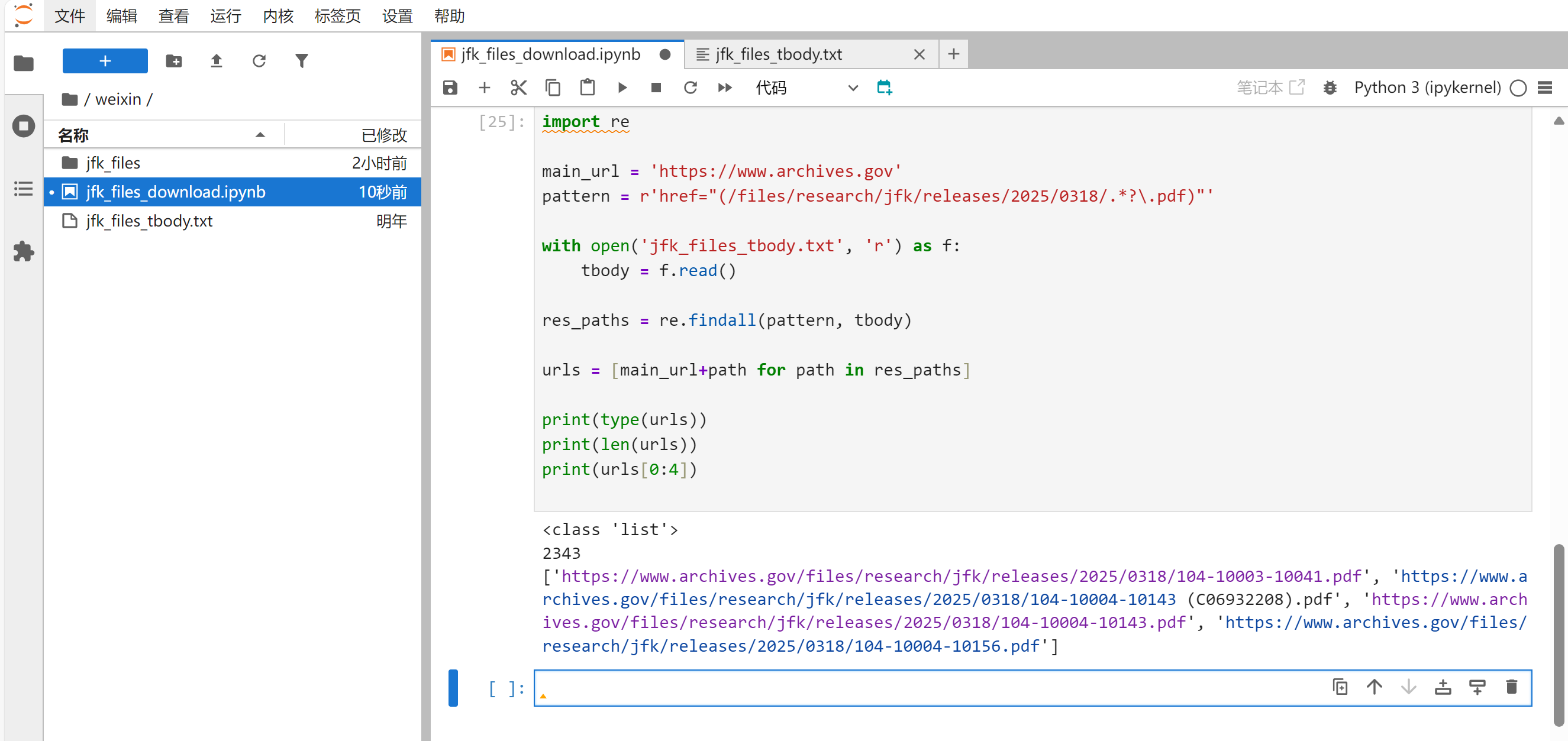
(5)合并代码
将代码与前面的代码合并,结果如下:import os
import requests
def download_file(url, folder):
# 从URL中提取文件名
filename = url.split('/')[-1]
# 构造保存文件的路径
path = os.path.join(folder, filename)
# 如果文件已存在,不再重复下载
if os.path.exists(path):
print(f"{filename} 文件已存在。")
return
# 确保文件夹存在
if not os.path.exists(folder):
os.makedirs(folder)
try:
# 使用requests库发送HTTP GET请求,获取文件内容
response = requests.get(url)
response.raise_for_status()
# 打开本地文件,准备写入内容
# 'wb' 表示以二进制写模式打开文件(因为下载的是PDF文件,属于二进制数据)
with open(path, 'wb') as f:
# 将响应内容(即文件的二进制数据)写入到本地文件中
f.write(response.content)
print(f"{filename} 文件下载成功。")
except Exception as e:
# 捕获请求异常,打印出错信息
print(f"下载文件出错: {e}")
# 文件的URL地址列表
main_url = 'https://www.archives.gov'
pattern = r'href="(/files/research/jfk/releases/2025/0318/.*?\.pdf)"'
with open('jfk_files_tbody.txt', 'r') as f:
tbody = f.read()
res_paths = re.findall(pattern, tbody)
urls = [main_url+path for path in res_paths]
# 保存文件的本地文件夹
folder = 'jfk_files'
# 遍历urls,调用函数,下载文件
for url in urls:
download_file(url, folder)
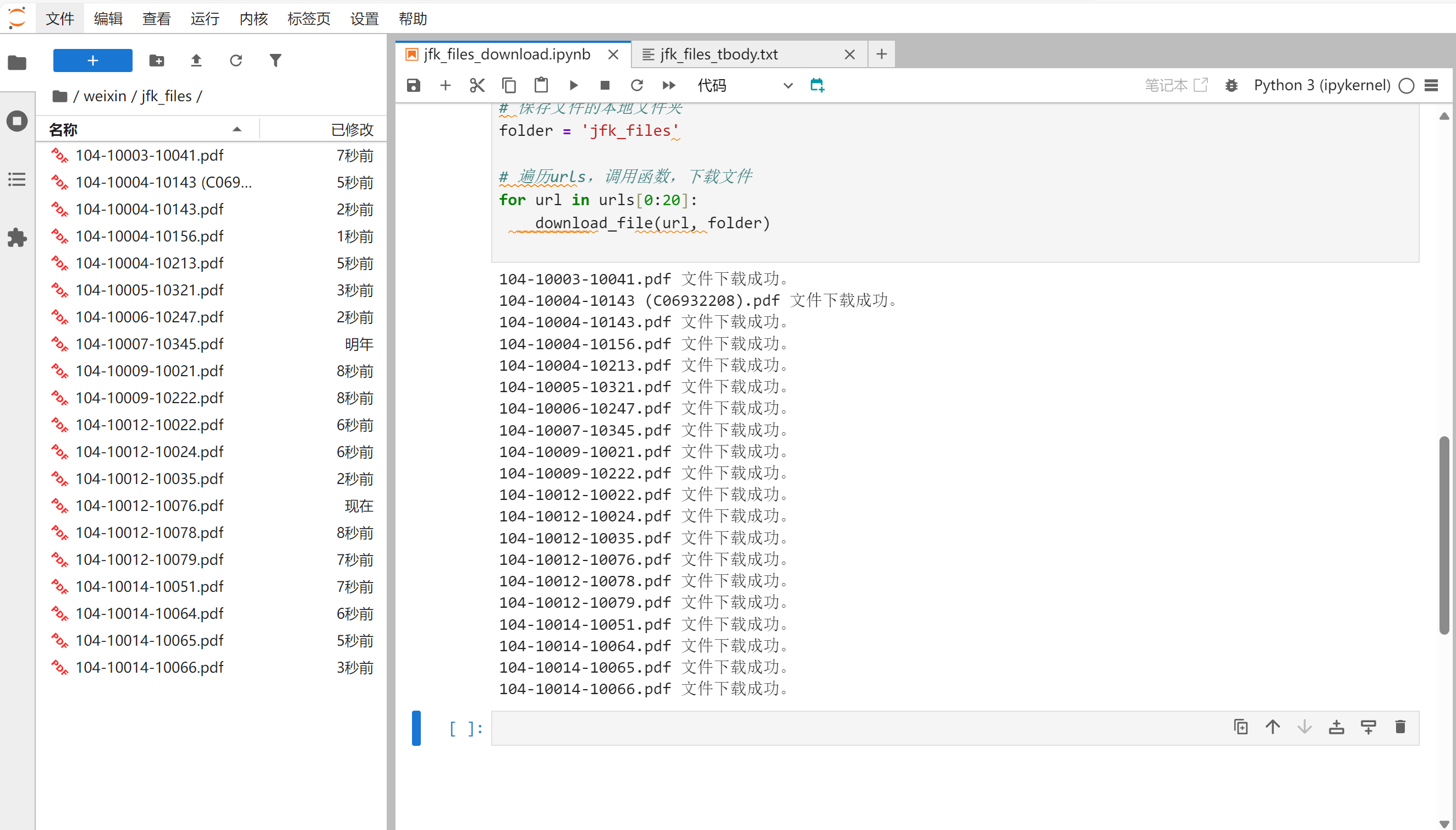
作为测试,我们取urls中前20个链接,进行文件下载
结果如下:
7、整理最终代码
到目前为止,我们已经有了一个完整的方案了。接下来我们额外做几件事,以使得最终代码更优雅、有可读性。- 封装一个主函数
main; - 将“确保文件夹存在”的操作,提拎出来放置在主函数中;
- 使用
urllib.parse包中的urljoin函数来构造完整链接。比起字符串直接的拼接的方式,采用urljoin函数来处理,鲁棒性更强,能避免手动拼接可能导致的错误(如缺少/或重复/); - 两次下载文件之间,程序沉睡1秒钟,以避免IP地址被封。
最终代码如下:
import os
import requests
from urllib.parse import urljoin
import time
def download_file(url, folder):
# 从URL中提取文件名
filename = url.split('/')[-1]
# 构造保存文件的路径
path = os.path.join(folder, filename)
# 如果文件已存在,不再重复下载
if os.path.exists(path):
print(f"{filename} 文件已存在。")
return
try:
# 使用requests库发送HTTP GET请求,获取文件内容
response = requests.get(url)
response.raise_for_status()
# 打开本地文件,准备写入内容
# 'wb' 表示以二进制写模式打开文件(因为下载的是PDF文件,属于二进制数据)
with open(path, 'wb') as f:
# 将响应内容(即文件的二进制数据)写入到本地文件中
f.write(response.content)
print(f"{filename} 文件下载成功。")
except Exception as e:
# 捕获请求异常,打印出错信息
print(f"下载文件出错: {e}")
def main():
# 文件的URL地址列表
main_url = 'https://www.archives.gov'
pattern = r'href="(/files/research/jfk/releases/2025/0318/.*?\.pdf)"'
with open('jfk_files_tbody.txt', 'r') as f:
tbody = f.read()
res_paths = re.findall(pattern, tbody)
urls = [urljoin(main_url, path) for path in res_paths]
# 保存文件的本地文件夹
folder = 'jfk_files'
# 确保文件夹存在
if not os.path.exists(folder):
os.makedirs(folder)
# 遍历urls,调用函数,下载文件
for url in urls:
download_file(url, folder)
time.sleep(1)
if __name__ == "__main__":
main()
好了,现在可以开始正式执行下载任务,下载所有文档了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









