






【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
目录
一、DeepSeek-V3 技术介绍
- 目标:提高模型性能,降低训练和推理成本(储存和时间)
- 改进点:
- FP8 混合精度训练(降低储存,提高速度)【大模型训练精度解释见第二节⬇️】
- 混合专家(MoE) 方法(提高模型性能)【MoE 解释见第三节⬇️】
- 使用多头潜在注意力机制(MLA) (减少缓存)
- 多Token预测 (MTP) (提高模型性能)
- Architecture (Transformer 架构):
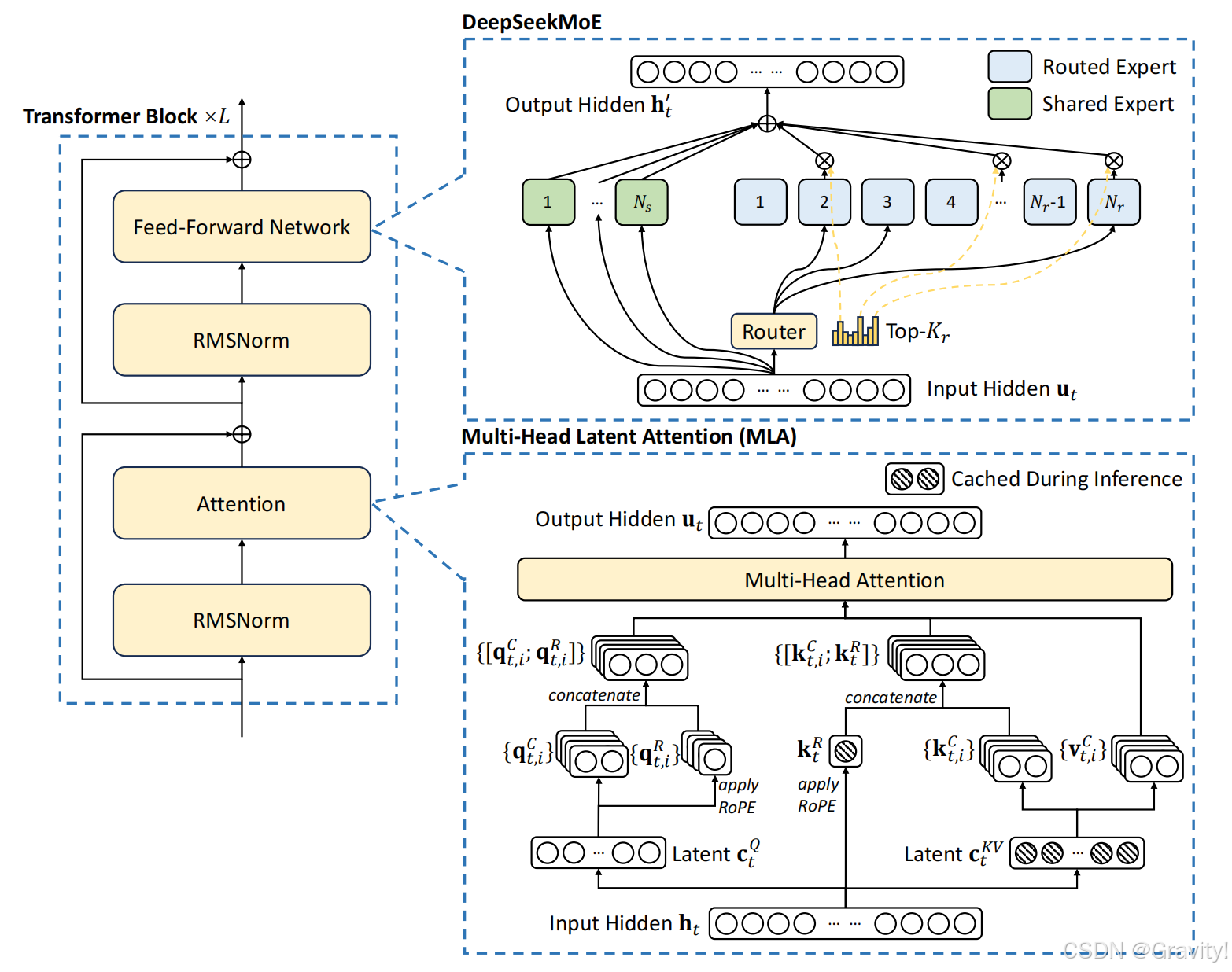
- 核心要点1: 多头潜在注意力机制 Multi-Head Latent Attention (MLA)
- Low-rank低秩压缩:将Key和Value压缩到低维潜空间(latent space)
- 核心要点2: DeepSeekMoE
- Routed专家 & Shared专家 【最终被激活8个专家】
- Routed专家(256个):常规负责不同领域的专家(由Router选择)
- Shared专家(1个):每个输入都会处理
- 负载均衡(load balance)实现
- 什么是负载均衡:合理分配输入数据到各个专家模型中,以确保每个专家的计算负载大致相等
- 无辅助损失策略(auxiliary-loss-free) :动态调整专家的偏置项来实现,无损失函数
- Routed专家 & Shared专家 【最终被激活8个专家】
- 核心要点3:多Token预测 (MTP)
- k个串行模型:主模型 + MTP模块 * (k-1)
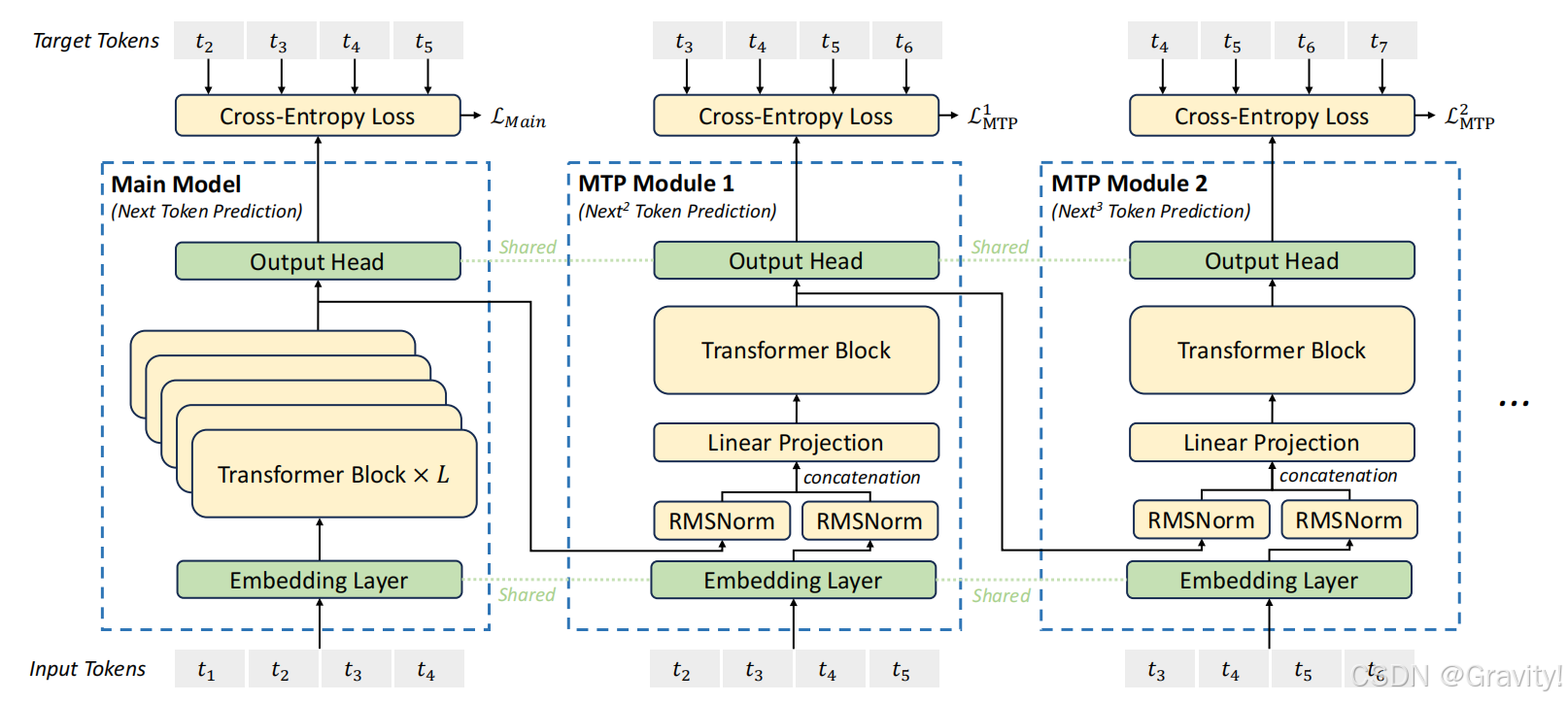
- 预测过程:输入 → 主模型预测下一token(k=1) → 输入+ token(k=1) 【拼接】→ MTP模块预测再下一token (k=1) → 输入+ token(k=1) + token(k=2) 【拼接】→ MTP模块 → ……
- k个串行模型:主模型 + MTP模块 * (k-1)
- 核心要点4: 混合精度训练
- 大部分计算用 FP8 精度,关键计算保持原始精度(BF16 或 FP16)
二、混合专家模型(MoE)
- 理解:由多个“专家”模型组成,每个“专家”负责其特定领域;由“门控网络“来控制哪个“专家”来回答问题
- 实现:
- 输入数据 → GateNet【分配专家模型(概率权重)】→ 选中的专家模型输出结果 → 加权结果输出
- GateNet的分配依据? 根据输入划分(类似分类)
三、大模型训练精度
- 精度介绍:
- 浮点数(flaot):双精度(FP64)、单精度(FP32)、半精度(FP16)
【如FP64为8个字节,共64位】 - BF精度:通常指BF16(为深度学习优化的16位浮点数格式)
- 浮点数(flaot):双精度(FP64)、单精度(FP32)、半精度(FP16)
- 神经网络模型默认:单精度(FP32);大模型训练常用:半精度(FP16);DeepSeek-V3使用:FP8混合精度
- 使用小精度存在的问题
- 数据溢出:如FP16的有效数据范围比FP32小,计算梯度时容易下溢
- 舍入误差:很小的反向梯度会被舍弃,如0.00000xx
DeepSeek-V3技术报告:
DeepSeek-V3/DeepSeek_V3.pdf at main · deepseek-ai/DeepSeek-V3 · GitHub

















 2773
2773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









