






科普知识
机器学习中一个重要的话题便是模型的泛化能力,泛化能力强的模型才是好模型,对于训练好的模型,若在训练集表现差,在测试集表现同样会很差,这可能是欠拟合导致。欠拟合是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。

# 前言
SEP.
理论篇的上一期文章中我们分享了AlexNet网络,该网络比之前的深度学习网络又加深了一点,同时采用了大尺寸的卷积,这些较之前都是新颖的改进。今天我们继续来学习一种新的网络架构--VGG,基础部件还是卷积层,但是深度和组合方式却不太一样,最终在公开数据集也提升到了一个新的高度,同时,这个网络将深度学习又推进了一个新的步伐。

VGG网络

今天分享的论文是:Very Deep Convolutional Networks for Large-Scale Image Recognition,一听名字就大概知道啥意思了,翻译过来就是用于大规模图像识别的深度卷积神经网络,这个网络有多深呢?通常来说,最为公认的,包括16层和19层两个版本,最终的网络架构为:VGG16与VGG19。
论文截图:

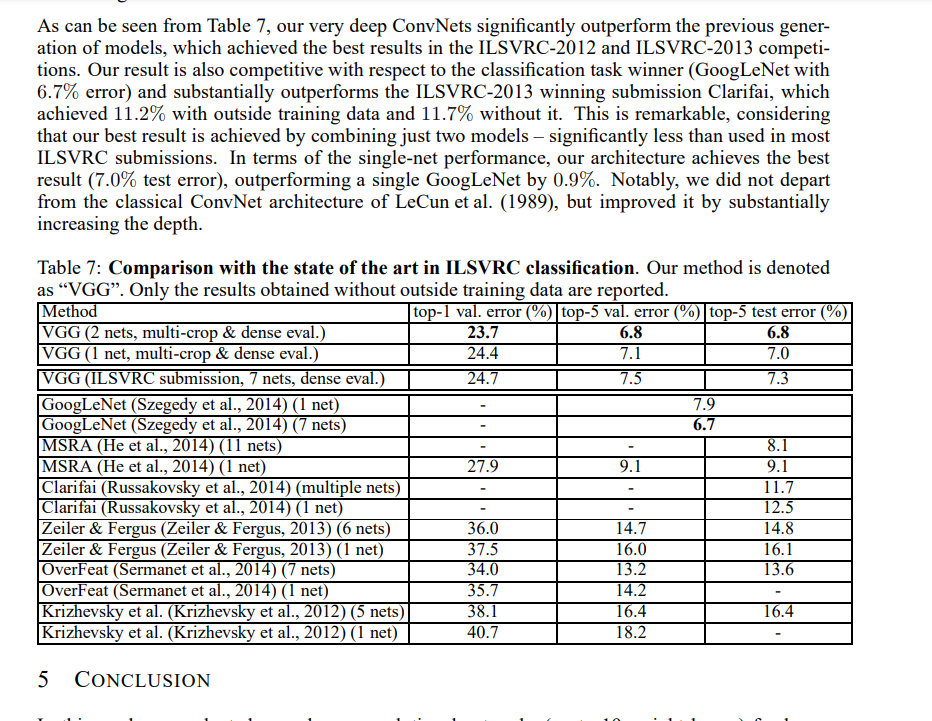
1.网络结构图

论文中的网络配置图:

图一
网上的网络结构图:
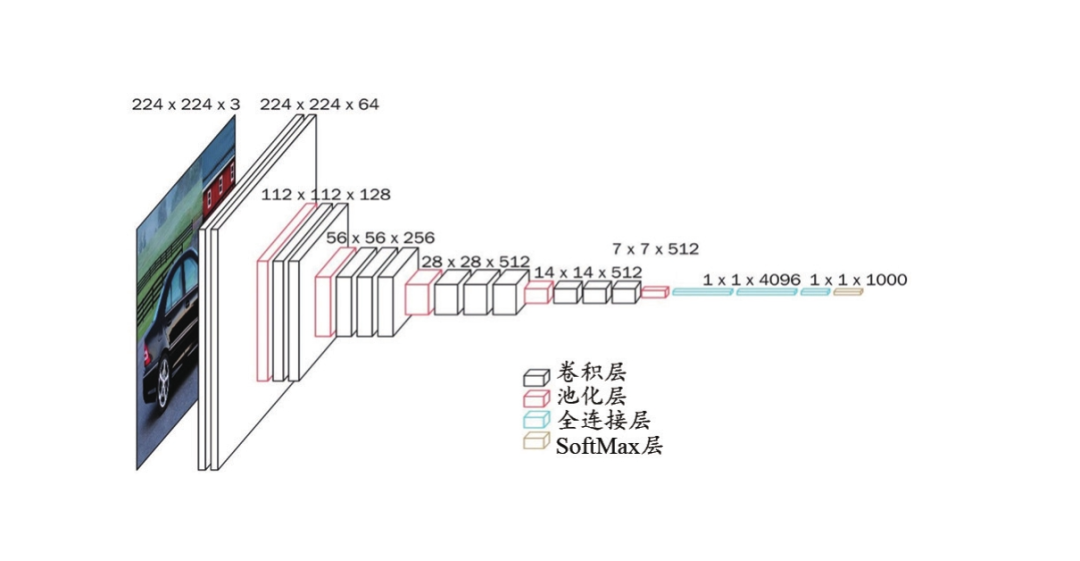
图二
论文地址:https://arxiv.org/pdf/1409.1556.pdf
2.网络解析

今天我们只分享VGG16就好,因为VGG19是差不多的架构,只是网络的深度多一点罢了。仔细观察,图一中的conv3代表的是卷积核为3x3大小的卷积操作,通道数量从3-64-128-256-512的变化,从图二中我们可以看到,原始图像经过网络之后尺寸越来越小,但是中间特征图的通道数却越来越增加,这是什么原理呢?通俗一点的解释是用通道数量的增加来弥补空间信息的减少(因为特征图越来越小)。
VGG16一共包含16层(13层卷积+3层全连接),这里需要记住一点的是通常所说的网络层数是指可以训练的层,池化一类的不算在内哦,因为它只包含了计算操作,没有训练操作哦。
输入层:224x224x3
64通道卷积层块:2层3x3x64的卷积结构,同时采用了padding操作,这样就会保持卷积操作前后特征图大小不变,输出:64x224x224。
maxpooling1: 特征图的尺寸变为原来的一半,输出:64x112x112。
128通道卷积块:2层3x3x128的卷积结构,同时采用了padding操作,这样就会保持卷积操作前后特征图大小不变,输出:128x112x112。
maxpooling2: 特征图的尺寸变为原来的一半,输出:128x56x56。
256通道卷积块:3层3x3x256的卷积结构,同时采用了padding操作,这样就会保持卷积操作前后特征图大小不变,输出:256x56x56。
maxpooling3: 特征图的尺寸变为原来的一半,输出:256x28x28。
512通道卷积块:3层3x3x256的卷积结构,同时采用了padding操作,这样就会保持卷积操作前后特征图大小不变,输出:512x28x28。
maxpooling4: 特征图的尺寸变为原来的一半,输出:512x14x14。
512通道卷积块:3层3x3x256的卷积结构,同时采用了padding操作,这样就会保持卷积操作前后特征图大小不变,输出:512x14x14。
maxpooling5: 特征图的尺寸变为原来的一半,输出:512x7x7。
全连接层1:输入:512*7*7,输出:4096。
全连接层2:输入:4096,输出:4096。
全连接层3:输入:4096,输出:1000。因为是100分类。
以上就是整个VGG16的结构解析啦,该网络主要证明了越深的网络可以学到的信息越多,也就提升了最终的分类精度,但是网络是不是越深就越好呢?或者说越深有什么限制吗?这个问题我们后期再说。此外,越深的网络所消耗的显存也越多,特别是最后两个4096的全连接层,因此这样的网络最好在1080以上的显卡跑起来才会比较好,不然速度非常慢。
END
结语
今天分享就到这里啦,认真学习的同学们可以好好看下VGG网络原始论文哦,了解下作者设计这个网络的初衷,以及最终如何证明该网络的有效性的,下周我们继续VGG16之TensorFlow实践。
再会!
编辑:玥怡居士|审核:小圈圈居士

IT进阶之旅
往期回顾
深度学习理论篇之 ( 十四) -- AlexNet之更上一楼
深度学习理论篇之 ( 十三) -- LetNet-5之风起云涌
过去的一年,我们都做了啥:

点个"赞"再走吧~














 3811
3811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









