







 本文探讨了如何使用Trie数据结构优化LeetCode上的Word Search II问题,避免因暴力搜索导致的时间超限错误。通过建立Trie树,可以一次性遍历棋盘并找出所有匹配的单词,提高效率。同时,文章提到了Trie树的节点结构和删除操作,并提供了相关参考资料链接。
本文探讨了如何使用Trie数据结构优化LeetCode上的Word Search II问题,避免因暴力搜索导致的时间超限错误。通过建立Trie树,可以一次性遍历棋盘并找出所有匹配的单词,提高效率。同时,文章提到了Trie树的节点结构和删除操作,并提供了相关参考资料链接。
https://leetcode.com/problems/word-search-ii/
最直观的思路就是对于每个word,都对board进行一次dfs搜索。这样在words太多的情况下会TLE. 这里考虑到board上有些point,对于任意word或者任意word的后缀都没有再继续搜索的必要,所以这里采用trie字典树存储所有带搜索的word。这样就只用dfs board一遍,就可以把所有的在board里的word搜出来。因为如果是每个word挨个搜的话,那么对于每个word都要scan一次这个board,如果但是其实对于相同前缀的word,例如abcd和abce这样的两个word其实是可以在一次scan的时候都找到的。所以这里用trie 树。
这里dfs的子节点就是上下左右的相邻节点,还要加visit 这个mask matrix。
参考:
http://bookshadow.com/weblog/2015/05/19/leetcode-word-search-ii/
这里的trie用child dict表示子节点,key是letter,value是node。我们要理解成每个node是没有value的,所以父节点到子节点的path才对应一个letter,即这里child dict的key。
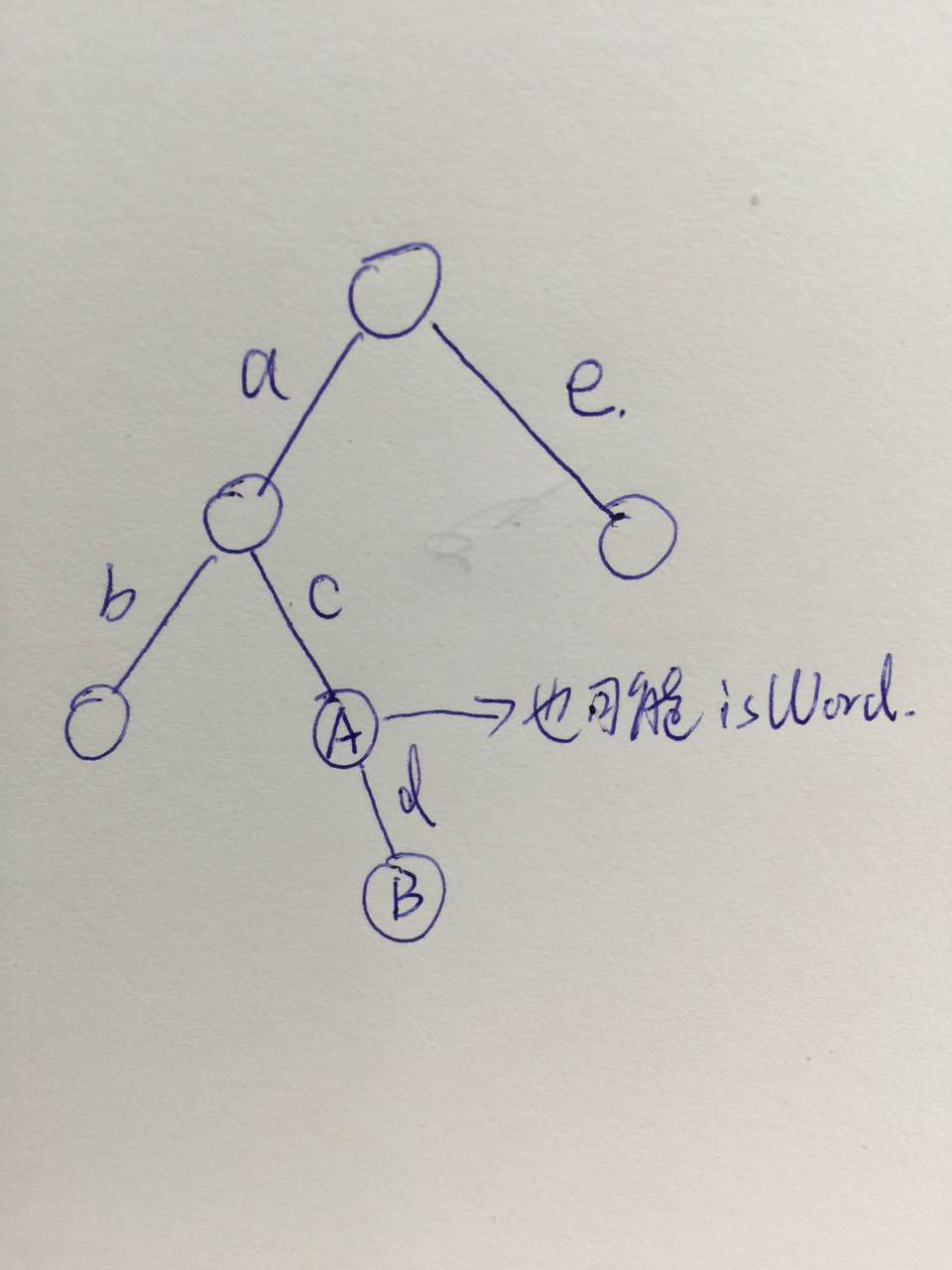
借由下图,解释一下trie的delete操作。以前以为isWord只可能在叶子节点才会是true,其实不是,这里如果有ac,以及acd,那么A节点以及B节点的isWord都是True。那么在删除一个word的时候,就是先用queue记住一个(node, letter), 即node以及下面一条path,然后一直到叶子节点
class Solution:
# @param {character[][]} board
# @param {string[]} words
# @return {string[]}
def findWords(self, board, words):
w, h = len(board[0]), len(board)
trie = Trie()
for word in words:
trie.insert(word)
visited = [[False] * w for x in range(h)]
dz = zip([1, 0, -1, 0], [0, 1, 0, -1])
ans = []
def dfs(word, node, x, y):
node = node.childs.get(board[x][y])#check是否有word + board[x][y]这样一个prefix
if node is None:#即在字典树中,没有word + board[x][y]这样一个prefix了,所以可以停止搜索了。
return
visited[x][y] = True
for z in dz:
nx, ny = x + z[0], y + z[1]
if nx >= 0 and nx < h and ny >= 0 and ny < w and not visited[nx][ny]:
dfs(word + board[nx][ny], node, nx, ny)
if node.isWord:
ans.append(word)
trie.delete(word)#这里为什么要删除?因为以免从其他地方出发也能搜到这个word,但是其实已经没必要了。只要确定某个word在board里就行。
visited[x][y] = False#承接上面的visited[x][y] = True,回溯用的。跟在word search I 中, 把board[x][y]置为#一样的道理。
for x in range(h):
for y in range(w):
dfs(board[x][y], trie.root, x, y)
return sorted(ans)
class TrieNode:#这里要注意,跟普通的tree node不一样的是,这个trie node是没有val的,
# Initialize your data structure here.
def __init__(self):
self.childs = dict()
self.isWord = False
class Trie:
def __init__(self):
self.root = TrieNode()
# @param {string} word
# @return {void}
# Inserts a word into the trie.
def insert(self, word):
node = self.root
for letter in word:
child = node.childs.get(letter)
if child is None:
child = TrieNode()
node.childs[letter] = child
node = child
node.isWord = True
def delete(self, word):#过程见上图解释
node = self.root
queue = []
for letter in word:
queue.append((letter, node))#一开始node是root,所以这里存的是node + node下面一个path
child = node.childs.get(letter)#node -> letter -> child这个顺序
if child is None:#不存在这个word
return False
node = child
if not node.isWord:#如果不是叶子节点,例如按照上图,删除ac之后,A的isWord变成了False,如果又要删除ac的话,那么就要return False
return False
if len(node.childs):#这里就是如果是A点,那么直接把isWord变成False就行
node.isWord = False
else:#如果是叶子节点,那么就要回溯到上一个公共节点。
for letter, node in reversed(queue):
del node.childs[letter]
if len(node.childs) or node.isWord:#len(node.childs)>0的时候就到了公共节点,或者像上图一样,从B回溯到A点的时候,发现A的isWord是True,那么也就不用再继续删除了。
break
return True














 1550
1550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









