







数据库管理系统体系结构
DBMS内核
内核自上而下
1.编译器,语法分析器:分析结果产生语法树
2.授权检查模块:看其是否有权限进行此类操作
3.语义分析和查询处理模块:调用具体函数,以及下层访问管理(即物理层提供的访问原语)对系统进行文件操作
4.并发控制,访问管理,恢复机制
再往下就是操作系统,再往上就是各种接口。
DBMS运行状态下的进程结构
单进程结构
应用程序和DBMS核心捆绑连接成一个exe,作为一个单独的进程运行
多进程结构
当我们connect某个数据库时,为当前应用创建一个DBMS核心进程,一个应用程序进程对应于一个DBMS核心进程,构建pipe、socket
多线程结构(Multi threads)
只有一个进程,每个应用进程都对应在同一进程里为其创建一个DBMS核心线程。
进程/线程之间的通信协议
线程的本质实际上是一种轻量级的进程,属于同一个进程的多个线程,可以共享这个进程的资源。
应用程序通过DBMS提供的API或嵌入式SQL访问数据库(管道0发送SQL语句,内部命令),DBMS核心通过管道1返回结果,实现同步控制。
DDBMS核心组件(分布式数据库管理系统的核心组件)
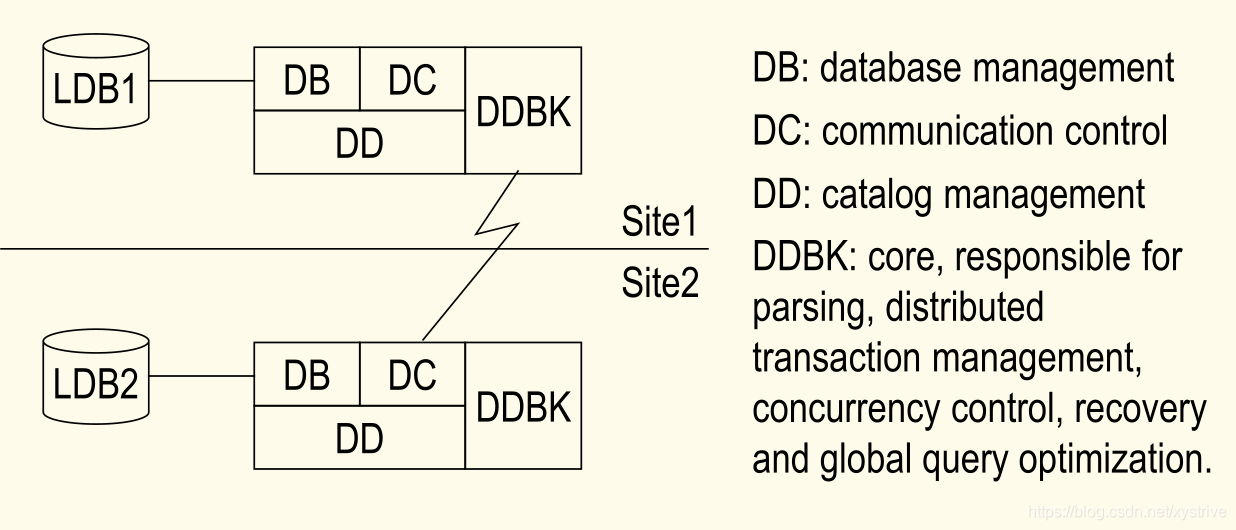
DC:通信控制,DD:目录管理,DDBK:核心,负责解析,分布式事务管理,并发控制,恢复和全局查询优化。
DDBMS全局查询优化的例子
全局查询优化可能会得到一个基于成本估算的执行计划,例如:
R1 &R2在分布式系统中S1 S2两个位置,要Select * From R1,R2 Where R1.a = R2.b;
- 把R2发给S1,得到R’,
- S1执行Select * From R1, R’ Where R1.a = R’.b;
访问管理
在关系型数据库中把对数据库的操作转化成对操作系统中文件的操作。它所提供的文件结构和访问路径将直接影响数据访问的速度。一种文件结构不可能对所有类型的数据访问都有效
访问类型
- 涉及到的元组数超过15%,就认定为需要操作most的数据。(因为硬盘是以块为单位进行操作的,并非以字节为单位,所以我们在数据库中读写其实也是以块为单位。假设数据是均匀分布的,其只要超过15%基本上就可覆盖所有块)
- 查找某个特定元组
- 查找小部分特定元组(<15%)
- 范围查找
- 更新操作
文件组织,关系型数据库底层数据结构:
堆文件:按插入顺序存储并只能按顺序检索的记录。配合索引扫描。适合查找most
**哈希文件:**根据某个属性的值通过hash函数映射记录地址。
堆文件+ B+树索引:最常用,可以提高数据访问效率。B+树是一种平衡树,且叶节点之间有双向链表。
大规模查找用堆文件顺序扫描,查找特定元组用B+树索引,范围查找可以用B+树的叶节点双向链表进行范围扫描。
簇型结构cluster,常用,raw disk:文件管理更底层的机制,允许用户自己控制数据在磁盘上怎么放。因为我们所谓的数据结构是逻辑上的存储,其经过操作系统在物理磁盘上真正的存储位置并不一定按照我们的想法(可能分散在不同磁片上)。如果我们可以在磁盘上按照物理顺序存储,在寻道查找的时候就很方便,raw disk就一次性申请需要大小的磁盘,可以自己实现一套文件管理。
动态哈希:动态调整哈希的范围以最大效率利用空间
栅格结构:多维数组(suitable for multi attributes queries)
索引技术
主要是B+树索引和簇索引。
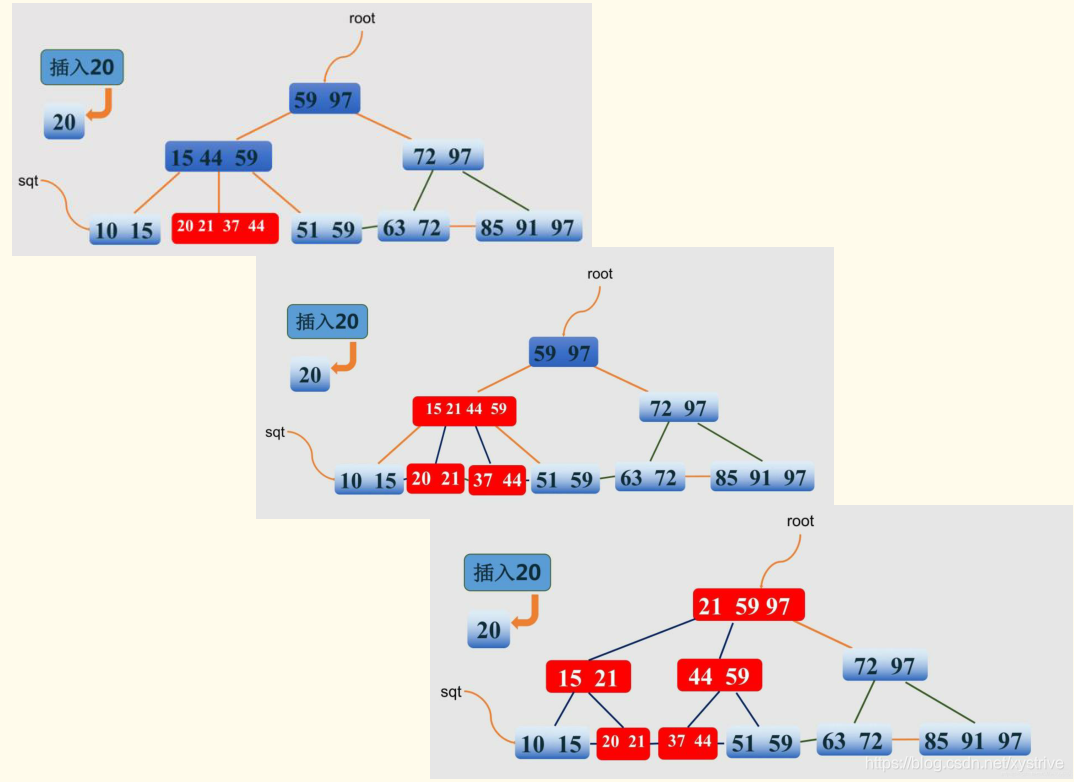
B+树种插入数:
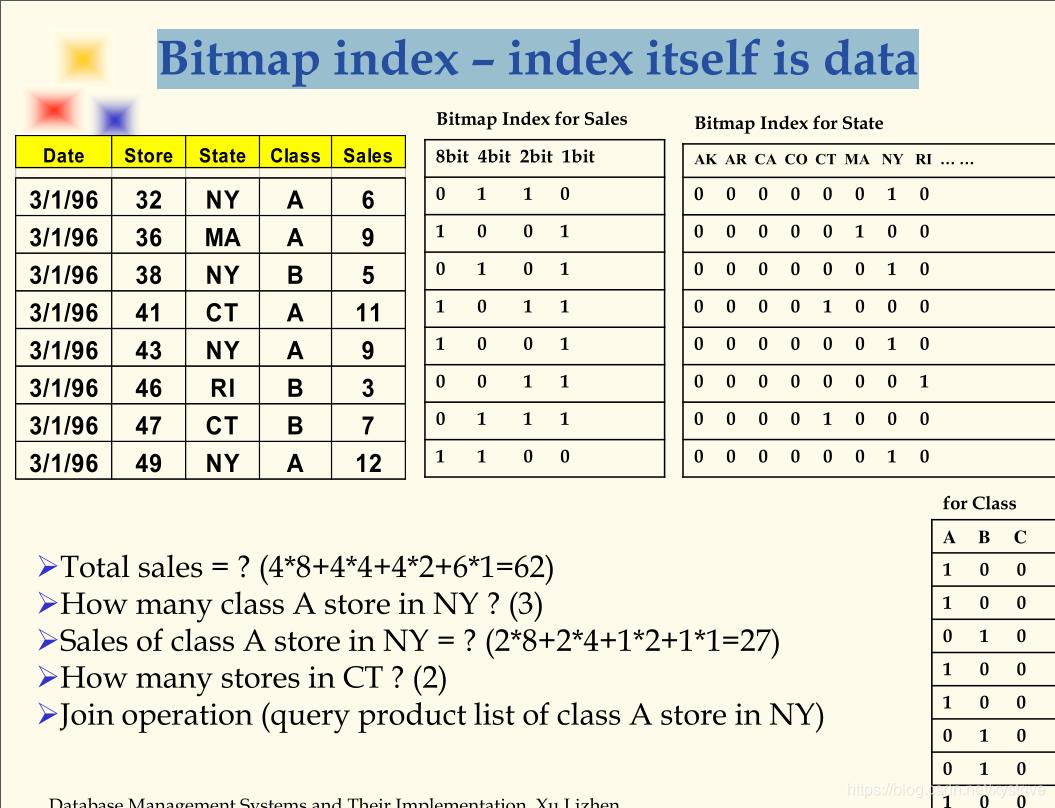
位图索引——索引本身就是数据:
数据分布
数据分布策略
灵活性,复杂性,优点和问题都随之升高:
- 集中式(Centralized):分布式系统,但数据仍然集中存储。这是最简单的,但是DDB没有任何优势。
- 分区(Partitioned):数据不重复分布。(没有副本)
- 复制(Replicated):每个站点上DB的完整副本。适用于检索密集型系统。
- 混合(以上的混合):在不同的站点DB的任意部分。最灵活和复杂的分配方法。
数据分布单位
- 根据关系(或文件),意味着无分区
- 根据片段:水平碎片:元组分区,垂直碎片:属性分区,混合
分割标准:
- 完整性Completeness:每个元组或属性必须在某些片段中有自己的反射。
- 重构Reconstruction:应该能够重构原始的全局关系。
- 不相交性Disjointness:用于水平分割。
不同透明等级
- 碎片化透明用户只需要知道全局关系,他不需要知道它们是否碎片化以及它们是如何分布的。在这种情况下,用户感觉不到数据的分布,就好像他在使用集中式数据库一样。
- 位置透明性用户需要知道关系是如何碎片化的,但他不必担心每个片段的存储位置。
- 本地映射透明性用户需要知道关系是如何碎片化的,以及它们是如何分布的,但他不必担心每个本地数据库由什么样的DBMS管理,使用什么样的DML等等。
- 没有透明度
数据分布引发的问题
- 多副本的一致性
- 分布的一致性:主要是由于更新操作导致的元组存储位置的变化。解决方法:1重新分配Redistribution:更新后:选择→移动→插入→删除。2捎带检查Piggybacking:在更新时立即检查元组,如果有任何不一致,它将与ACK信息一起发送回来,然后发送到正确的位置。
- 将全局查询转换为片段查询和选择物理副本。
- 数据库片段的设计与片段的分配。
以上1)~3)应该在DDBMS中解决。而4)是一个分布式数据库设计问题。
并行数据库
采用Share Noting (SN) structure
垂直平行和水平平行:
- Vertical parallel:一个复杂的查询可以分解成几个操作步骤,这些步骤的并行过程称为垂直并行。
- horizontal parallel:对于扫描操作,如果要扫描的关系被预先分割成几个片段,并存储在一个SN结构的并行计算机的不同磁盘上,那么扫描可以在这些磁盘上并行处理。这种平行叫水平平行。
目录的分发
目录——关于数据(元数据)的数据。其主要功能是将用户的操作需求传递给系统中的物理目标。
目录的内容:(1)~(4)不经常更改,而(5)每次更新操作都会更改。
- 每个数据对象的类型(如基表、视图等)及其模式
- 分布信息(例如片段位置,…)
- 访问路由(如索引,…)
- 授权信息
- 查询优化中使用的一些统计信息
目录的特点:
- 主要对其进行读取操作
- 对于系统的效率和数据分布的透明性非常重要
- 这对区域自治非常重要
- 目录的分布是由DDBMS的体系结构决定的,而不是由应用程序需求决定的
目录分销策略:
- 集中的:存储在一个站点上的完整目录。扩展集中目录:先集中;使用后保存;在有更新时通知
- 完全复制:在每个站点复制目录。简单检索。复杂的更新。可怜的自主权。
- 本地目录:本地数据的目录存储在每个站点。这意味着目录是和数据一起存储的。如果想要其他站点数据的目录信息(通过广播查找):主目录:在某些站点上存储完整的目录。使每个目录信息都有两个副本。缓存:通过广播获取和使用其他站点数据的目录信息后,将其保存以备将来使用(缓存)。通过版本号的比较更新缓存的目录。
- 混合:对分发信息使用完全复制策略,对其他部分使用本地目录策略。或使用本地目录策略统计信息,使用完全复制策略到其他部分。
R*目录管理
特点:
无全局目录,独立命名和数据定义,目录平静地成长
Syste
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









